[ENG] .NET 5, 6, 7, and 8 for busy developers | .NET Community Austria
Source link
دسته: ذخیره دادههای موقت
-
[ENG] .NET 5, 6, 7, and 8 for busy developers | .NET Community Austria
-

Use TestCase to run similar unit tests with NUnit | Code4IT
Just a second! 🫷
If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .If you want to support this blog, please ensure that you have disabled the adblocker for this site.
I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.Thank you for your understanding.
– DavideIn my opinion, Unit tests should be well structured and written even better than production code.
In fact, Unit Tests act as a first level of documentation of what your code does and, if written properly, can be the key to fixing bugs quickly and without adding regressions.
One way to improve readability is by grouping similar tests that only differ by the initial input but whose behaviour is the same.
Let’s use a dummy example: some tests on a simple
Calculatorclass that only performs sums on int values.public static class Calculator { public static int Sum(int first, int second) => first + second; }One way to create tests is by creating one test for each possible combination of values:
public class SumTests { [Test] public void SumPositiveNumbers() { var result = Calculator.Sum(1, 5); Assert.That(result, Is.EqualTo(6)); } [Test] public void SumNegativeNumbers() { var result = Calculator.Sum(-1, -5); Assert.That(result, Is.EqualTo(-6)); } [Test] public void SumWithZero() { var result = Calculator.Sum(1, 0); Assert.That(result, Is.EqualTo(1)); } }However, it’s not a good idea: you’ll end up with lots of identical tests (DRY, remember?) that add little to no value to the test suite. Also, this approach forces you to add a new test method to every new kind of test that pops into your mind.
When possible, we should generalize it. With NUnit, we can use the
TestCaseattribute to specify the list of parameters passed in input to our test method, including the expected result.We can then simplify the whole test class by creating only one method that accepts the different cases in input and runs tests on those values.
[Test] [TestCase(1, 5, 6)] [TestCase(-1, -5, -6)] [TestCase(1, 0, 1)] public void SumWorksCorrectly(int first, int second, int expected) { var result = Calculator.Sum(first, second); Assert.That(result, Is.EqualTo(expected)); }By using
TestCase, you can cover different cases by simply adding a new case without creating new methods.Clearly, don’t abuse it: use it only to group methods with similar behaviour – and don’t add
ifstatements in the test method!There is a more advanced way to create a TestCase in NUnit, named
TestCaseSource– but we will talk about it in a future C# tip 😉Further readings
If you are using NUnit, I suggest you read this article about custom equality checks – you might find it handy in your code!
🔗 C# Tip: Use custom Equality comparers in Nunit tests | Code4IT
This article first appeared on Code4IT 🐧
Wrapping up
I hope you enjoyed this article! Let’s keep in touch on Twitter or LinkedIn! 🤜🤛
Happy coding!
🐧
-

4 ways to create Unit Tests without Interfaces in C# | Code4IT
C# devs have the bad habit of creating interfaces for every non-DTO class because «we need them for mocking!». Are you sure it’s the only way?
Table of Contents
Just a second! 🫷
If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .If you want to support this blog, please ensure that you have disabled the adblocker for this site.
I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.Thank you for your understanding.
– DavideOne of the most common traits of C# developers is the excessive usage of interfaces.
For every non-DTO class we define, we usually also create the related interface. Most of the time, we don’t need it because we have multiple implementations of an interface. Instead, we say that we need an interface to enable mocking.
That’s true; it’s pretty straightforward to mock an interface: lots of libraries, like Moq and NSubstitute, allow you to create mocks and pass them to the class under test. What if there were another way?
In this article, we will learn how to have complete control over a dependency while having the concrete class, and not the related interface, injected in the constructor.
C# devs always add interfaces, just in case
If you’re a developer like me, you’ve been taught something like this:
One of the SOLID principles is Dependency Inversion; to achieve it, you need Dependency Injection. The best way to do that is by creating an interface, injecting it in the consumer’s constructor, and then mapping the interface and the concrete class.
Sometimes, somebody explains that we don’t need interfaces to achieve Dependency Injection. However, there are generally two arguments proposed by those who keep using interfaces everywhere: the “in case I need to change the database” argument and, even more often, the “without interfaces, I cannot create mocks”.
Are we sure?
The “Just in case I need to change the database” argument
One phrase that I often hear is:
Injecting interfaces allows me to change the concrete implementation of a class without worrying about the caller. You know, just in case I had to change the database engine…
Yes, that’s totally right – using interfaces, you can change the internal implementation in a bat of an eye.
Let’s be honest: in all your career, how many times have you changed the underlying database? In my whole career, it happened just once: we tried to build a solution using Gremlin for CosmosDB, but it turned out to be too expensive – so we switched to a simpler MongoDB.
But, all in all, it wasn’t only thanks to the interfaces that we managed to switch easily; it was because we strictly separated the classes and did not leak the models related to Gremlin into the core code. We structured the code with a sort of Hexagonal Architecture, way before this term became a trend in the tech community.
Still, interfaces can be helpful, especially when dealing with multiple implementations of the same methods or when you want to wrap your head around the methods, inputs, and outputs exposed by a module.
The “I need to mock” argument
Another one I like is this:
Interfaces are necessary for mocking dependencies! Otherwise, how can I create Unit Tests?
Well, I used to agree with this argument. I was used to mocking interfaces by using libraries like Moq and defining the behaviour of the dependency using the
SetUpmethod.It’s still a valid way, but my point here is that that’s not the only one!
One of the simplest tricks is to mark your classes as
abstract. But… this means you’ll end up with every single class marked as abstract. Not the best idea.We have other tools in our belt!
A realistic example: Dependency Injection without interfaces
Let’s start with a real-ish example.
We have a
NumbersRepositorythat just exposes one method:GetNumbers().public class NumbersRepository { private readonly int[] _allNumbers; public NumbersRepository() { _allNumbers = Enumerable.Range(0, int.MaxValue).ToArray(); } public IEnumerable<int> GetNumbers() => Random.Shared.GetItems(_allNumbers, 50); }Generally, one would be tempted to add an interface with the same name as the class,
INumbersRepository, and include theGetNumbersmethod in the interface definition.We are not going to do that – the interface is not necessary, so why clutter the code with something like that?
Now, for the consumer. We have a simple
NumbersSearchServicethat accepts, via Dependency Injection, an instance ofNumbersRepository(yes, the concrete class!) and uses it to perform a simple search:public class NumbersSearchService { private readonly NumbersRepository _repository; public NumbersSearchService(NumbersRepository repository) { _repository = repository; } public bool Contains(int number) { var numbers = _repository.GetNumbers(); return numbers.Contains(number); } }To add these classes to your ASP.NET project, you can add them in the DI definition like this:
builder.Services.AddSingleton<NumbersRepository>(); builder.Services.AddSingleton<NumbersSearchService>();Without adding any interface.
Now, how can we test this class without using the interface?
Way 1: Use the “virtual” keyword in the dependency to create stubs
We can create a subclass of the dependency, even if it is a concrete class, by overriding just some of its functionalities.
For example, we can choose to mark the
GetNumbersmethod in theNumbersRepositoryclass asvirtual, making it easily overridable from a subclass.public class NumbersRepository { private readonly int[] _allNumbers; public NumbersRepository() { _allNumbers = Enumerable.Range(0, 100).ToArray(); } - public IEnumerable<int> GetNumbers() => Random.Shared.GetItems(_allNumbers, 50); + public virtual IEnumerable<int> GetNumbers() => Random.Shared.GetItems(_allNumbers, 50); }Yes, we can mark a method as
virtualeven if the class is concrete!Now, in our Unit Tests, we can create a subtype of
NumbersRepositoryto have complete control of theGetNumbersmethod:internal class StubNumberRepo : NumbersRepository { private IEnumerable<int> _numbers; public void SetNumbers(params int[] numbers) => _numbers = numbers; public override IEnumerable<int> GetNumbers() => _numbers; }We have overridden the
GetNumbersmethod, but to do so, we had to include a new method,SetNumbers, to define the expected result of the former method.We then can use it in our tests like this:
[Test] public void Should_WorkWithStubRepo() { // Arrange var repository = new StubNumberRepo(); repository.SetNumbers(1, 2, 3); var service = new NumbersSearchService(repository); // Act var result = service.Contains(3); // Assert Assert.That(result, Is.True); }You now have the full control over the subclass. But this approach comes with a problem: if you have multiple methods marked as
virtual, and you are going to use all of them in your test classes, then you will need to override every single method (to have control over them) and work out how to decide whether to use the concrete method or the stub implementation.For example, we can update the
StubNumberRepoto let the consumer choose if we need the dummy values or the base implementation:internal class StubNumberRepo : NumbersRepository { private IEnumerable<int> _numbers; private bool _useStubNumbers; public void SetNumbers(params int[] numbers) { _numbers = numbers; _useStubNumbers = true; } public override IEnumerable<int> GetNumbers() { if (_useStubNumbers) return _numbers; return base.GetNumbers(); } }With this approach, by default, we use the concrete implementation of
NumbersRepositorybecause_useStubNumbersisfalse. If we call theSetNumbersmethod, we also specify that we don’t want to use the original implementation.Way 2: Use the virtual keyword in the service to avoid calling the dependency
Similar to the previous approach, we can mark some methods of the caller as
virtualto allow us to change parts of our class while keeping everything else as it was.To achieve it, we have to refactor a little our Service class:
public class NumbersSearchService { private readonly NumbersRepository _repository; public NumbersSearchService(NumbersRepository repository) { _repository = repository; } public bool Contains(int number) { - var numbers = _repository.GetNumbers(); + var numbers = GetNumbers(); return numbers.Contains(number); } + public virtual IEnumerable<int> GetNumbers() => _repository.GetNumbers(); }The key is that we moved the calls to the external references to a separate method, marking it as
virtual.This way, we can create a stub class of the Service itself without the need to stub its dependencies:
internal class StubNumberSearch : NumbersSearchService { private IEnumerable<int> _numbers; private bool _useStubNumbers; public StubNumberSearch() : base(null) { } public void SetNumbers(params int[] numbers) { _numbers = numbers.ToArray(); _useStubNumbers = true; } public override IEnumerable<int> GetNumbers() => _useStubNumbers ? _numbers : base.GetNumbers(); }The approach is almost identical to the one we saw before. The difference can be seen in your tests:
[Test] public void Should_UseStubService() { // Arrange var service = new StubNumberSearch(); service.SetNumbers(12, 15, 30); // Act var result = service.Contains(15); // Assert Assert.That(result, Is.True); }There is a problem with this approach: many devs (correctly) add null checks in the constructor to ensure that the dependencies are not null:
public NumbersSearchService(NumbersRepository repository) { ArgumentNullException.ThrowIfNull(repository); _repository = repository; }While this approach makes it safe to use the
NumbersSearchServicereference within the class’ methods, it also stops us from creating aStubNumberSearch. Since we want to create an instance ofNumbersSearchServicewithout the burden of injecting all the dependencies, we call the base constructor passingnullas a value for the dependencies. If we validate against null, the stub class becomes unusable.There’s a simple solution: adding a protected empty constructor:
public NumbersSearchService(NumbersRepository repository) { ArgumentNullException.ThrowIfNull(repository); _repository = repository; } protected NumbersSearchService() { }We mark it as
protectedbecause we want that only subclasses can access it.Way 3: Use the “new” keyword in methods to hide the base implementation
Similar to the
virtualkeyword is thenewkeyword, which can be applied to methods.We can then remove the
virtualkeyword from the base class and hide its implementation by marking the overriding method asnew.public class NumbersSearchService { private readonly NumbersRepository _repository; public NumbersSearchService(NumbersRepository repository) { ArgumentNullException.ThrowIfNull(repository); _repository = repository; } public bool Contains(int number) { var numbers = _repository.GetNumbers(); return numbers.Contains(number); } - public virtual IEnumerable<int> GetNumbers() => _repository.GetNumbers(); + public IEnumerable<int> GetNumbers() => _repository.GetNumbers(); }We have restored the original implementation of the Repository.
Now, we can update the stub by adding the
newkeyword.internal class StubNumberSearch : NumbersSearchService { private IEnumerable<int> _numbers; private bool _useStubNumbers; public void SetNumbers(params int[] numbers) { _numbers = numbers.ToArray(); _useStubNumbers = true; } - public override IEnumerable<int> GetNumbers() => _useStubNumbers ? _numbers : base.GetNumbers(); + public new IEnumerable<int> GetNumbers() => _useStubNumbers ? _numbers : base.GetNumbers(); }We haven’t actually solved any problem except for one: we can now avoid cluttering all our classes with the
virtualkeyword.A question for you! Is there any difference between using the
newand thevirtualkeyword? When you should pick one instead of the other? Let me know in the comments section! 📩Way 4: Mock concrete classes by marking a method as virtual
Sometimes, I hear developers say that mocks are the absolute evil, and you should never use them.
Oh, come on! Don’t be so silly!
That’s true, when using mocks you are writing tests on a irrealistic environment. But, well, that’s exactly the point of having mocks!
If you think about it, at school, during Science lessons, we were taught to do our scientific calculations using approximations: ignore the air resistance, ignore friction, and so on. We knew that that world did not exist, but we removed some parts to make it easier to validate our hypothesis.
In my opinion, it’s the same for testing. Mocks are useful to have full control of a specific behaviour. Still, only relying on mocks makes your tests pretty brittle: you cannot be sure that your system is working under real conditions.
That’s why, as I explained in a previous article, I prefer the Testing Diamond over the Testing Pyramid. In many real cases, five Integration Tests are more valuable than fifty Unit Tests.
But still, mocks can be useful. How can we use them if we don’t have interfaces?
Let’s start with the basic example:
public class NumbersRepository { private readonly int[] _allNumbers; public NumbersRepository() { _allNumbers = Enumerable.Range(0, 100).ToArray(); } public IEnumerable<int> GetNumbers() => Random.Shared.GetItems(_allNumbers, 50); } public class NumbersSearchService { private readonly NumbersRepository _repository; public NumbersSearchService(NumbersRepository repository) { ArgumentNullException.ThrowIfNull(repository); _repository = repository; } public bool Contains(int number) { var numbers = _repository.GetNumbers(); return numbers.Contains(number); } }If we try to use Moq to create a mock of
NumbersRepository(again, the concrete class) like this:[Test] public void Should_WorkWithMockRepo() { // Arrange var repository = new Moq.Mock<NumbersRepository>(); repository.Setup(_ => _.GetNumbers()).Returns(new int[] { 1, 2, 3 }); var service = new NumbersSearchService(repository.Object); // Act var result = service.Contains(3); // Assert Assert.That(result, Is.True); }It will fail with this error:
System.NotSupportedException : Unsupported expression: _ => _.GetNumbers()
Non-overridable members (here: NumbersRepository.GetNumbers) may not be used in setup / verification expressions.This error occurs because the implementation
GetNumbersis fixed as defined in theNumbersRepositoryclass and cannot be overridden.Unless you mark it as
virtual, as we did before.public class NumbersRepository { private readonly int[] _allNumbers; public NumbersRepository() { _allNumbers = Enumerable.Range(0, 100).ToArray(); } - public IEnumerable<int> GetNumbers() => Random.Shared.GetItems(_allNumbers, 50); + public virtual IEnumerable<int> GetNumbers() => Random.Shared.GetItems(_allNumbers, 50); }Now the test passes: we have successfully mocked a concrete class!
Further readings
Testing is a crucial part of any software application. I personally write Unit Tests even for throwaway software – this way, I can ensure that I’m doing the correct thing without the need for manual debugging.
However, one part that is often underestimated is the code quality of tests. Tests should be written even better than production code. You can find more about this topic here:
🔗 Tests should be even more well-written than production code | Code4IT
Also, Unit Tests are not enough. You should probably write more Integration Tests than Unit Tests. This one is a testing strategy called Testing Diamond.
🔗 Testing Pyramid vs Testing Diamond (and how they affect Code Coverage) | Code4IT
This article first appeared on Code4IT 🐧
Clearly, you can write Integration Tests for .NET APIs easily. In this article, I explain how to create and customize Integration Tests using NUnit:
🔗 Advanced Integration Tests for .NET 7 API with WebApplicationFactory and NUnit | Code4IT
Wrapping up
In this article, we learned that it’s not necessary to create interfaces for the sake of having mocks.
We have different other options.
Honestly speaking, I’m still used to creating interfaces and using them with mocks.
I find it easy to do, and this approach provides a quick way to create tests and drive the behaviour of the dependencies.
Also, I recognize that interfaces created for the sole purpose of mocking are quite pointless: we have learned that there are other ways, and we should consider trying out these solutions.
Still, interfaces are quite handy for two “non-technical” reasons:
- using interfaces, you can understand in a glimpse what are the operations that you can call in a clean and concise way;
- interfaces and mocks allow you to easily use TDD: while writing the test cases, you also define what methods you need and the expected behaviour. I know you can do that using stubs, but I find it easier with interfaces.
I know, this is a controversial topic – I’m not saying that you should remove all your interfaces (I think it’s a matter of personal taste, somehow!), but with this article, I want to highlight that you can avoid interfaces.
I hope you enjoyed this article! Let’s keep in touch on Twitter or LinkedIn! 🤜🤛
Happy coding!
🐧
-

Handling exceptions with Task.WaitAll and Task.WhenAll | Code4IT
Just a second! 🫷
If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .If you want to support this blog, please ensure that you have disabled the adblocker for this site.
I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.Thank you for your understanding.
– DavideAsynchronous programming enables you to execute multiple operations without blocking the main thread.
In general, we often think of the Happy Scenario, when all the operations go smoothly, but we rarely consider what to do when an error occurs.
In this article, we will explore how
Task.WaitAllandTask.WhenAllbehave when an error is thrown in one of the awaited Tasks.Prepare the tasks to be executed
For the sake of this article, we are going to use a silly method that returns the same number passed in input but throws an exception in case the input number can be divided by 3:
public Task<int> Echo(int value) => Task.Factory.StartNew( () => { if (value % 3 == 0) { Console.WriteLine($"[LOG] You cannot use {value}!"); throw new Exception($"[EXCEPTION] Value cannot be {value}"); } Console.WriteLine($"[LOG] {value} is a valid value!"); return value; } );Those
Console.WriteLineinstructions will allow us to see what’s happening “live”.We prepare the collection of tasks to be awaited by using a simple
Enumerable.Rangevar tasks = Enumerable.Range(1, 11).Select(Echo);And then, we use a try-catch block with some logs to showcase what happens when we run the application.
try { Console.WriteLine("START"); // await all the tasks Console.WriteLine("END"); } catch (Exception ex) { Console.WriteLine("The exception message is: {0}", ex.Message); Console.WriteLine("The exception type is: {0}", ex.GetType().FullName); if (ex.InnerException is not null) { Console.WriteLine("Inner exception: {0}", ex.InnerException.Message); } } finally { Console.WriteLine("FINALLY!"); }If we run it all together, we can notice that nothing really happened:
In fact, we just created a collection of tasks (which does not actually exist, since the result is stored in a lazy-loaded enumeration).
We can, then, call WaitAll and WhenAll to see what happens when an error occurs.
Error handling when using Task.WaitAll
It’s time to execute the tasks stored in the
taskscollection, like this:try { Console.WriteLine("START"); // await all the tasks Task.WaitAll(tasks.ToArray()); Console.WriteLine("END"); }Task.WaitAllaccepts an array of tasks to be awaited and does not return anything.The execution goes like this:
START 1 is a valid value! 2 is a valid value! :( You cannot use 6! 5 is a valid value! :( You cannot use 3! 4 is a valid value! 8 is a valid value! 10 is a valid value! :( You cannot use 9! 7 is a valid value! 11 is a valid value! The exception message is: One or more errors occurred. ([EXCEPTION] Value cannot be 3) ([EXCEPTION] Value cannot be 6) ([EXCEPTION] Value cannot be 9) The exception type is: System.AggregateException Inner exception: [EXCEPTION] Value cannot be 3 FINALLY!There are a few things to notice:
- the tasks are not executed in sequence: for example, 6 was printed before 4. Well, to be honest, we can say that
Console.WriteLineprinted the messages in that sequence, but maybe the tasks were executed in another different order (as you can deduce from the order of the error messages); - all the tasks are executed before jumping to the
catchblock; - the exception caught in the
catchblock is of typeSystem.AggregateException; we’ll come back to it later; - the
InnerExceptionproperty of the exception being caught contains the info for the first exception that was thrown.
Error handling when using Task.WhenAll
Let’s replace
Task.WaitAllwithTask.WhenAll.try { Console.WriteLine("START"); await Task.WhenAll(tasks); Console.WriteLine("END"); }There are two main differences to notice when comparing
Task.WaitAllandTask.WhenAll:Task.WhenAllaccepts in input whatever type of collection (as long as it is anIEnumerable);- it returns a
Taskthat you have toawait.
And what happens when we run the program?
START 2 is a valid value! 1 is a valid value! 4 is a valid value! :( You cannot use 3! 7 is a valid value! 5 is a valid value! :( You cannot use 6! 8 is a valid value! 10 is a valid value! 11 is a valid value! :( You cannot use 9! The exception message is: [EXCEPTION] Value cannot be 3 The exception type is: System.Exception FINALLY!Again, there are a few things to notice:
- just as before, the messages are not printed in order;
- the exception message contains the message for the first exception thrown;
- the exception is of type
System.Exception, and notSystem.AggregateExceptionas we saw before.
This means that the first exception breaks everything, and you lose the info about the other exceptions that were thrown.
📩 but now, a question for you: we learned that, when using
Task.WhenAll, only the first exception gets caught by thecatchblock. What happens to the other exceptions? How can we retrieve them? Drop a message in the comment below ⬇️Comparing Task.WaitAll and Task.WhenAll
Task.WaitAll and Task.WhenAll are similar but not identical.
Task.WaitAllshould be used when you are in a synchronous context and need to block the current thread until all tasks are complete. This is common in simple old-style console applications or scenarios where asynchronous programming is not required. However, it is not recommended in UI or modern ASP.NET applications because it can cause deadlocks or freeze the UI.Task.WhenAllis preferred in modern C# code, especially in asynchronous methods (where you can useasync Task). It allows you to await the completion of multiple tasks without blocking the calling thread, making it suitable for environments where responsiveness is important. It also enables easier composition of continuations and better exception handling.Let’s wrap it up in a table:
Feature Task.WaitAll Task.WhenAll Return Type voidTaskorTask<TResult[]>Blocking/Non-blocking Blocking (waits synchronously) Non-blocking (returns a Task) Exception Handling Throws AggregateException immediately Exceptions observed when awaited Usage Context Synchronous code (e.g., console apps) Asynchronous code (e.g., async methods) Continuation Not possible (since it blocks) Possible (use .ContinueWithorawait)Deadlock Risk Higher in UI contexts Lower (if properly awaited) Bonus tip: get the best out of AggregateException
We can expand a bit on the
AggregateExceptiontype.That specific type of exception acts as a container for all the exceptions thrown when using
Task.WaitAll.It contains a property named
InnerExceptionsthat contains all the exceptions thrown so that you can access them using an Enumerator.A common example is this:
if (ex is AggregateException aggEx) { Console.WriteLine("There are {0} exceptions in the aggregate exception.", aggEx.InnerExceptions.Count); foreach (var innerEx in aggEx.InnerExceptions) { Console.WriteLine("Inner exception: {0}", innerEx.Message); } }Further readings
This article is all about handling the unhappy path.
If you want to learn more about
Task.WaitAllandTask.WhenAll, I’d suggest you read the following two articles that I find totally interesting and well-written:🔗 Understanding Task.WaitAll and Task.WhenAll in C# | Muhammad Umair
and
🔗 Understanding WaitAll and WhenAll in .NET | Prasad Raveendran
This article first appeared on Code4IT 🐧
But, if you don’t know what asynchronous programming is and how to use TAP in C#, I’d suggest you start from the basics with this article:
🔗 First steps with asynchronous programming in C# | Code4IT
Wrapping up
I hope you enjoyed this article! Let’s keep in touch on LinkedIn, Twitter or BlueSky! 🤜🤛
Happy coding!
🐧
- the tasks are not executed in sequence: for example, 6 was printed before 4. Well, to be honest, we can say that
-

Top 6 Performance Tips when dealing with strings in C# 12 and .NET 8 | Code4IT
Small changes sometimes make a huge difference. Learn these 6 tips to improve the performance of your application just by handling strings correctly.
Table of Contents
Just a second! 🫷
If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .If you want to support this blog, please ensure that you have disabled the adblocker for this site.
I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.Thank you for your understanding.
– DavideSometimes, just a minor change makes a huge difference. Maybe you won’t notice it when performing the same operation a few times. Still, the improvement is significant when repeating the operation thousands of times.
In this article, we will learn five simple tricks to improve the performance of your application when dealing with strings.
Note: this article is part of C# Advent Calendar 2023, organized by Matthew D. Groves: it’s maybe the only Christmas tradition I like (yes, I’m kind of a Grinch 😂).
Benchmark structure, with dependencies
Before jumping to the benchmarks, I want to spend a few words on the tools I used for this article.
The project is a .NET 8 class library running on a laptop with an i5 processor.
Running benchmarks with BenchmarkDotNet
I’m using BenchmarkDotNet to create benchmarks for my code. BenchmarkDotNet is a library that runs your methods several times, captures some metrics, and generates a report of the executions. If you follow my blog, you might know I’ve used it several times – for example, in my old article “Enum.HasFlag performance with BenchmarkDotNet”.
All the benchmarks I created follow the same structure:
[MemoryDiagnoser] public class BenchmarkName() { [Params(1, 5, 10)] // clearly, I won't use these values public int Size; public string[] AllStrings { get; set; } [IterationSetup] public void Setup() { AllStrings = StringArrayGenerator.Generate(Size, "hello!", "HELLO!"); } [Benchmark(Baseline=true)] public void FirstMethod() { //omitted } [Benchmark] public void SecondMethod() { //omitted } }In short:
- the class is marked with the
[MemoryDiagnoser]attribute: the benchmark will retrieve info for both time and memory usage; - there is a property named
Sizewith the attribute[Params]: this attribute lists the possible values for theSizeproperty; - there is a method marked as
[IterationSetup]: this method runs before every single execution, takes the value from theSizeproperty, and initializes theAllStringsarray; - the methods that are parts of the benchmark are marked with the
[Benchmark]attribute.
Generating strings with Bogus
I relied on Bogus to create dummy values. This NuGet library allows you to generate realistic values for your objects with a great level of customization.
The string array generation strategy is shared across all the benchmarks, so I moved it to a static method:
public static class StringArrayGenerator { public static string[] Generate(int size, params string[] additionalStrings) { string[] array = new string[size]; Faker faker = new Faker(); List<string> fixedValues = [ string.Empty, " ", "\n \t", null ]; if (additionalStrings != null) fixedValues.AddRange(additionalStrings); for (int i = 0; i < array.Length; i++) { if (Random.Shared.Next() % 4 == 0) { array[i] = Random.Shared.GetItems<string>(fixedValues.ToArray(), 1).First(); } else { array[i] = faker.Lorem.Word(); } } return array; } }Here I have a default set of predefined values (
[string.Empty, " ", "\n \t", null]), which can be expanded with the values coming from theadditionalStringsarray. These values are then placed in random positions of the array.In most cases, though, the value of the string is defined by Bogus.
Generating plots with chartbenchmark.net
To generate the plots you will see in this article, I relied on chartbenchmark.net, a fantastic tool that transforms the output generated by BenchmarkDotNet on the console in a dynamic, customizable plot. This tool created by Carlos Villegas is available on GitHub, and it surely deserves a star!
Please note that all the plots in this article have a Log10 scale: this scale allows me to show you the performance values of all the executions in the same plot. If I used the Linear scale, you would be able to see only the biggest values.
We are ready. It’s time to run some benchmarks!
Tip #1: StringBuilder is (almost always) better than String Concatenation
Let’s start with a simple trick: if you need to concatenate strings, using a StringBuilder is generally more efficient than concatenating string.
[MemoryDiagnoser] public class StringBuilderVsConcatenation() { [Params(4, 100, 10_000, 100_000)] public int Size; public string[] AllStrings { get; set; } [IterationSetup] public void Setup() { AllStrings = StringArrayGenerator.Generate(Size, "hello!", "HELLO!"); } [Benchmark] public void WithStringBuilder() { StringBuilder sb = new StringBuilder(); foreach (string s in AllStrings) { sb.Append(s); } var finalString = sb.ToString(); } [Benchmark] public void WithConcatenation() { string finalString = ""; foreach (string s in AllStrings) { finalString += s; } } }Whenever you concatenate strings with the
+sign, you create a new instance of astring. This operation takes some time and allocates memory for every operation.On the contrary, using a
StringBuilderobject, you can add the strings in memory and generate the final string using a performance-wise method.Here’s the result table:
Method Size Mean Error StdDev Median Ratio RatioSD Allocated Alloc Ratio WithStringBuilder 4 4.891 us 0.5568 us 1.607 us 4.750 us 1.00 0.00 1016 B 1.00 WithConcatenation 4 3.130 us 0.4517 us 1.318 us 2.800 us 0.72 0.39 776 B 0.76 WithStringBuilder 100 7.649 us 0.6596 us 1.924 us 7.650 us 1.00 0.00 4376 B 1.00 WithConcatenation 100 13.804 us 1.1970 us 3.473 us 13.800 us 1.96 0.82 51192 B 11.70 WithStringBuilder 10000 113.091 us 4.2106 us 12.081 us 111.000 us 1.00 0.00 217200 B 1.00 WithConcatenation 10000 74,512.259 us 2,111.4213 us 6,058.064 us 72,593.050 us 666.43 91.44 466990336 B 2,150.05 WithStringBuilder 100000 1,037.523 us 37.1009 us 108.225 us 1,012.350 us 1.00 0.00 2052376 B 1.00 WithConcatenation 100000 7,469,344.914 us 69,720.9843 us 61,805.837 us 7,465,779.900 us 7,335.08 787.44 46925872520 B 22,864.17 Let’s see it as a plot.
Beware of the scale in the diagram!: it’s a Log10 scale, so you’d better have a look at the value displayed on the Y-axis.
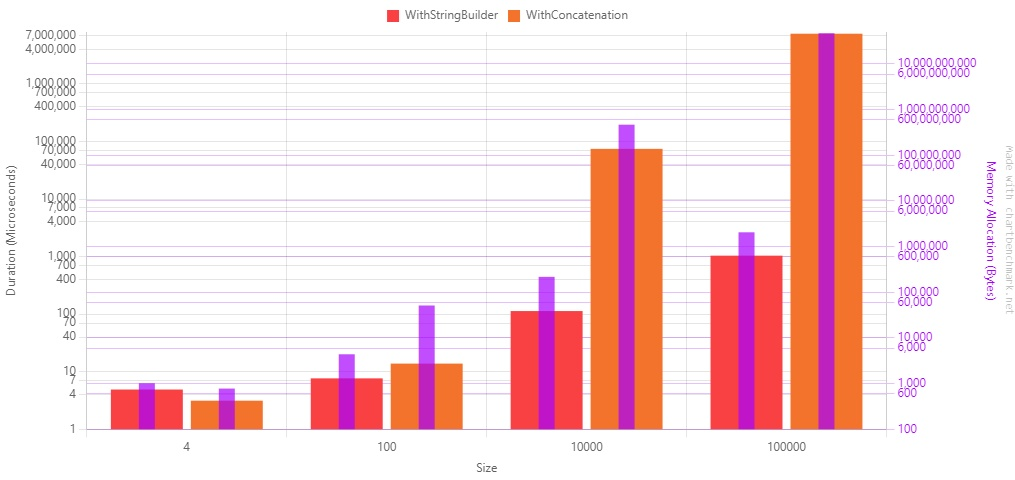
As you can see, there is a considerable performance improvement.
There are some remarkable points:
- When there are just a few strings to concatenate, the
+operator is more performant, both on timing and allocated memory; - When you need to concatenate 100000 strings, the concatenation is ~7000 times slower than the string builder.
In conclusion, use the
StringBuilderto concatenate more than 5 or 6 strings. Use the string concatenation for smaller operations.Edit 2024-01-08: turn out that
string.Concathas an overload that accepts an array of strings.string.Concat(string[])is actually faster than using the StringBuilder. Read more this article by Robin Choffardet.Tip #2: EndsWith(string) vs EndsWith(char): pick the right overload
One simple improvement can be made if you use
StartsWithorEndsWith, passing a single character.There are two similar overloads: one that accepts a
string, and one that accepts achar.[MemoryDiagnoser] public class EndsWithStringVsChar() { [Params(100, 1000, 10_000, 100_000, 1_000_000)] public int Size; public string[] AllStrings { get; set; } [IterationSetup] public void Setup() { AllStrings = StringArrayGenerator.Generate(Size); } [Benchmark(Baseline = true)] public void EndsWithChar() { foreach (string s in AllStrings) { _ = s?.EndsWith('e'); } } [Benchmark] public void EndsWithString() { foreach (string s in AllStrings) { _ = s?.EndsWith("e"); } } }We have the following results:
Method Size Mean Error StdDev Median Ratio EndsWithChar 100 2.189 us 0.2334 us 0.6771 us 2.150 us 1.00 EndsWithString 100 5.228 us 0.4495 us 1.2970 us 5.050 us 2.56 EndsWithChar 1000 12.796 us 1.2006 us 3.4831 us 12.200 us 1.00 EndsWithString 1000 30.434 us 1.8783 us 5.4492 us 29.250 us 2.52 EndsWithChar 10000 25.462 us 2.0451 us 5.9658 us 23.950 us 1.00 EndsWithString 10000 251.483 us 18.8300 us 55.2252 us 262.300 us 10.48 EndsWithChar 100000 209.776 us 18.7782 us 54.1793 us 199.900 us 1.00 EndsWithString 100000 826.090 us 44.4127 us 118.5465 us 781.650 us 4.14 EndsWithChar 1000000 2,199.463 us 74.4067 us 217.0480 us 2,190.600 us 1.00 EndsWithString 1000000 7,506.450 us 190.7587 us 562.4562 us 7,356.250 us 3.45 Again, let’s generate the plot using the Log10 scale:
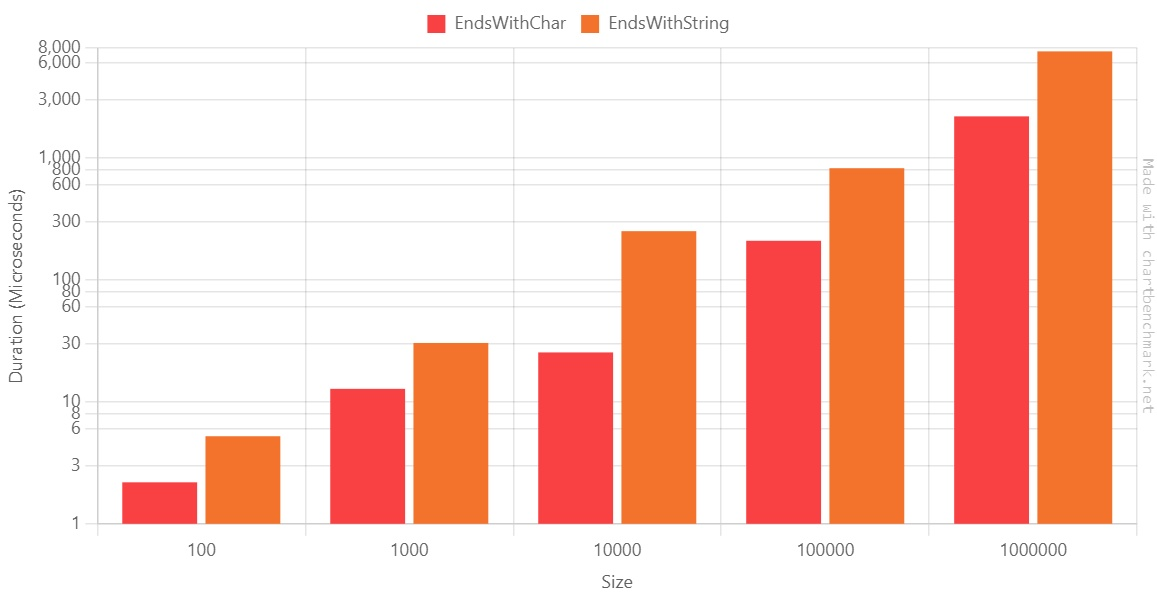
They appear to be almost identical, but look closely: based on this benchmark, when we have 10000, using
EndsWith(string)is 10x slower thanEndsWith(char).Also, here, the duration ratio on the 1.000.000-items array is ~3.5. At first, I thought there was an error on the benchmark, but when rerunning it on the benchmark, the ratio did not change.
It looks like you have the best improvement ratio when the array has ~10.000 items.
Tip #3: IsNullOrEmpty vs IsNullOrWhitespace vs IsNullOrEmpty + Trim
As you might know,
string.IsNullOrWhiteSpaceperforms stricter checks thanstring.IsNullOrEmpty.(If you didn’t know, have a look at this quick explanation of the cases covered by these methods).
Does it affect performance?
To demonstrate it, I have created three benchmarks: one for
string.IsNullOrEmpty, one forstring.IsNullOrWhiteSpace, and another one that lays in between: it first callsTrim()on the string, and then callsstring.IsNullOrEmpty.[MemoryDiagnoser] public class StringEmptyBenchmark { [Params(100, 1000, 10_000, 100_000, 1_000_000)] public int Size; public string[] AllStrings { get; set; } [IterationSetup] public void Setup() { AllStrings = StringArrayGenerator.Generate(Size); } [Benchmark(Baseline = true)] public void StringIsNullOrEmpty() { foreach (string s in AllStrings) { _ = string.IsNullOrEmpty(s); } } [Benchmark] public void StringIsNullOrEmptyWithTrim() { foreach (string s in AllStrings) { _ = string.IsNullOrEmpty(s?.Trim()); } } [Benchmark] public void StringIsNullOrWhitespace() { foreach (string s in AllStrings) { _ = string.IsNullOrWhiteSpace(s); } } }We have the following values:
Method Size Mean Error StdDev Ratio StringIsNullOrEmpty 100 1.723 us 0.2302 us 0.6715 us 1.00 StringIsNullOrEmptyWithTrim 100 2.394 us 0.3525 us 1.0282 us 1.67 StringIsNullOrWhitespace 100 2.017 us 0.2289 us 0.6604 us 1.45 StringIsNullOrEmpty 1000 10.885 us 1.3980 us 4.0781 us 1.00 StringIsNullOrEmptyWithTrim 1000 20.450 us 1.9966 us 5.8240 us 2.13 StringIsNullOrWhitespace 1000 13.160 us 1.0851 us 3.1482 us 1.34 StringIsNullOrEmpty 10000 18.717 us 1.1252 us 3.2464 us 1.00 StringIsNullOrEmptyWithTrim 10000 52.786 us 1.2208 us 3.5222 us 2.90 StringIsNullOrWhitespace 10000 46.602 us 1.2363 us 3.4668 us 2.54 StringIsNullOrEmpty 100000 168.232 us 12.6948 us 36.0129 us 1.00 StringIsNullOrEmptyWithTrim 100000 439.744 us 9.3648 us 25.3182 us 2.71 StringIsNullOrWhitespace 100000 394.310 us 7.8976 us 20.5270 us 2.42 StringIsNullOrEmpty 1000000 2,074.234 us 64.3964 us 186.8257 us 1.00 StringIsNullOrEmptyWithTrim 1000000 4,691.103 us 112.2382 us 327.4040 us 2.28 StringIsNullOrWhitespace 1000000 4,198.809 us 83.6526 us 161.1702 us 2.04 As you can see from the Log10 table, the results are pretty similar:
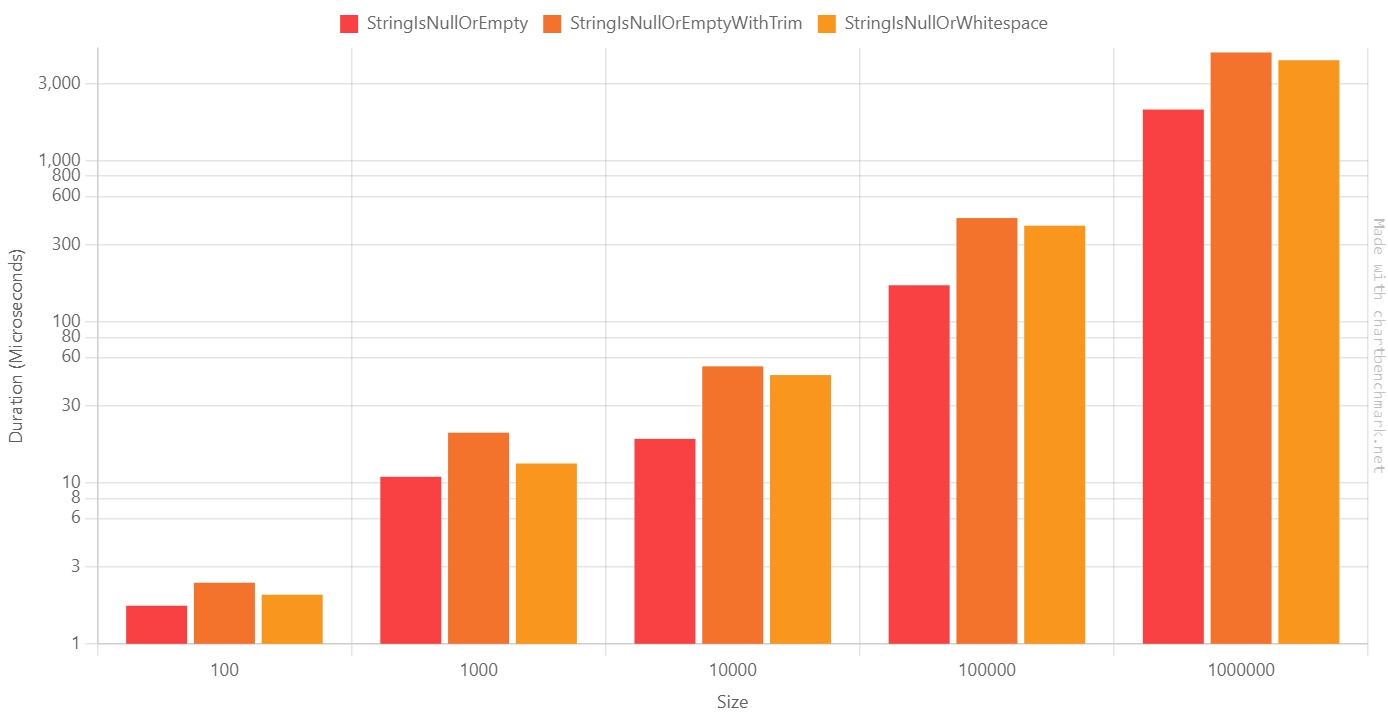
On average,
StringIsNullOrWhitespaceis ~2 times slower thanStringIsNullOrEmpty.So, what should we do? Here’s my two cents:
- For all the data coming from the outside (passed as input to your system, received from an API call, read from the database), use
string.IsNUllOrWhiteSpace: this way you can ensure that you are not receiving unexpected data; - If you read data from an external API, customize your JSON deserializer to convert whitespace strings as empty values;
- Needless to say, choose the proper method depending on the use case. If a string like “\n \n \t” is a valid value for you, use
string.IsNullOrEmpty.
Tip #4: ToUpper vs ToUpperInvariant vs ToLower vs ToLowerInvariant: they look similar, but they are not
Even though they look similar, there is a difference in terms of performance between these four methods.
[MemoryDiagnoser] public class ToUpperVsToLower() { [Params(100, 1000, 10_000, 100_000, 1_000_000)] public int Size; public string[] AllStrings { get; set; } [IterationSetup] public void Setup() { AllStrings = StringArrayGenerator.Generate(Size); } [Benchmark] public void WithToUpper() { foreach (string s in AllStrings) { _ = s?.ToUpper(); } } [Benchmark] public void WithToUpperInvariant() { foreach (string s in AllStrings) { _ = s?.ToUpperInvariant(); } } [Benchmark] public void WithToLower() { foreach (string s in AllStrings) { _ = s?.ToLower(); } } [Benchmark] public void WithToLowerInvariant() { foreach (string s in AllStrings) { _ = s?.ToLowerInvariant(); } } }What will this benchmark generate?
Method Size Mean Error StdDev Median P95 Ratio WithToUpper 100 9.153 us 0.9720 us 2.789 us 8.200 us 14.980 us 1.57 WithToUpperInvariant 100 6.572 us 0.5650 us 1.639 us 6.200 us 9.400 us 1.14 WithToLower 100 6.881 us 0.5076 us 1.489 us 7.100 us 9.220 us 1.19 WithToLowerInvariant 100 6.143 us 0.5212 us 1.529 us 6.100 us 8.400 us 1.00 WithToUpper 1000 69.776 us 9.5416 us 27.833 us 68.650 us 108.815 us 2.60 WithToUpperInvariant 1000 51.284 us 7.7945 us 22.860 us 38.700 us 89.290 us 1.85 WithToLower 1000 49.520 us 5.6085 us 16.449 us 48.100 us 79.110 us 1.85 WithToLowerInvariant 1000 27.000 us 0.7370 us 2.103 us 26.850 us 30.375 us 1.00 WithToUpper 10000 241.221 us 4.0480 us 3.588 us 240.900 us 246.560 us 1.68 WithToUpperInvariant 10000 339.370 us 42.4036 us 125.028 us 381.950 us 594.760 us 1.48 WithToLower 10000 246.861 us 15.7924 us 45.565 us 257.250 us 302.875 us 1.12 WithToLowerInvariant 10000 143.529 us 2.1542 us 1.910 us 143.500 us 146.105 us 1.00 WithToUpper 100000 2,165.838 us 84.7013 us 223.137 us 2,118.900 us 2,875.800 us 1.66 WithToUpperInvariant 100000 1,885.329 us 36.8408 us 63.548 us 1,894.500 us 1,967.020 us 1.41 WithToLower 100000 1,478.696 us 23.7192 us 50.547 us 1,472.100 us 1,571.330 us 1.10 WithToLowerInvariant 100000 1,335.950 us 18.2716 us 35.203 us 1,330.100 us 1,404.175 us 1.00 WithToUpper 1000000 20,936.247 us 414.7538 us 1,163.014 us 20,905.150 us 22,928.350 us 1.64 WithToUpperInvariant 1000000 19,056.983 us 368.7473 us 287.894 us 19,085.400 us 19,422.880 us 1.41 WithToLower 1000000 14,266.714 us 204.2906 us 181.098 us 14,236.500 us 14,593.035 us 1.06 WithToLowerInvariant 1000000 13,464.127 us 266.7547 us 327.599 us 13,511.450 us 13,926.495 us 1.00 Let’s see it as the usual Log10 plot:
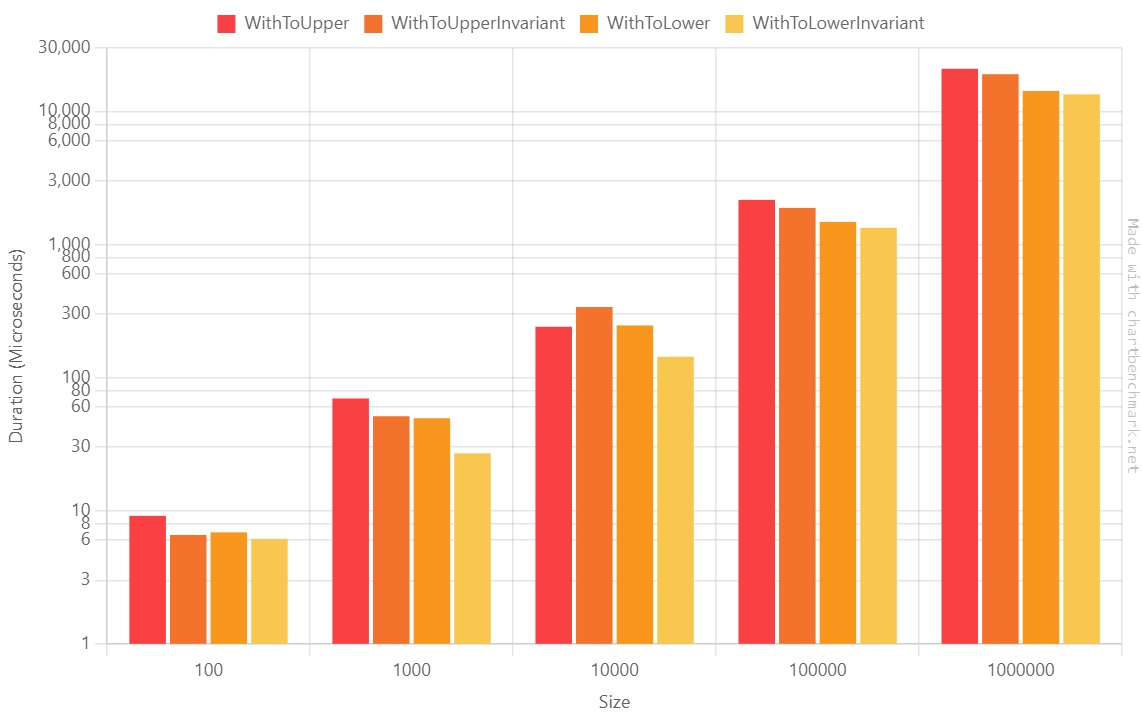
We can notice a few points:
- The ToUpper family is generally slower than the ToLower family;
- The Invariant family is faster than the non-Invariant one; we will see more below;
So, if you have to normalize strings using the same casing,
ToLowerInvariantis the best choice.Tip #5: OrdinalIgnoreCase vs InvariantCultureIgnoreCase: logically (almost) equivalent, but with different performance
Comparing strings is trivial: the
string.Comparemethod is all you need.There are several modes to compare strings: you can specify the comparison rules by setting the
comparisonTypeparameter, which accepts aStringComparisonvalue.[MemoryDiagnoser] public class StringCompareOrdinalVsInvariant() { [Params(100, 1000, 10_000, 100_000, 1_000_000)] public int Size; public string[] AllStrings { get; set; } [IterationSetup] public void Setup() { AllStrings = StringArrayGenerator.Generate(Size, "hello!", "HELLO!"); } [Benchmark(Baseline = true)] public void WithOrdinalIgnoreCase() { foreach (string s in AllStrings) { _ = string.Equals(s, "hello!", StringComparison.OrdinalIgnoreCase); } } [Benchmark] public void WithInvariantCultureIgnoreCase() { foreach (string s in AllStrings) { _ = string.Equals(s, "hello!", StringComparison.InvariantCultureIgnoreCase); } } }Let’s see the results:
Method Size Mean Error StdDev Ratio WithOrdinalIgnoreCase 100 2.380 us 0.2856 us 0.8420 us 1.00 WithInvariantCultureIgnoreCase 100 7.974 us 0.7817 us 2.3049 us 3.68 WithOrdinalIgnoreCase 1000 11.316 us 0.9170 us 2.6603 us 1.00 WithInvariantCultureIgnoreCase 1000 35.265 us 1.5455 us 4.4591 us 3.26 WithOrdinalIgnoreCase 10000 20.262 us 1.1801 us 3.3668 us 1.00 WithInvariantCultureIgnoreCase 10000 225.892 us 4.4945 us 12.5289 us 11.41 WithOrdinalIgnoreCase 100000 148.270 us 11.3234 us 32.8514 us 1.00 WithInvariantCultureIgnoreCase 100000 1,811.144 us 35.9101 us 64.7533 us 12.62 WithOrdinalIgnoreCase 1000000 2,050.894 us 59.5966 us 173.8460 us 1.00 WithInvariantCultureIgnoreCase 1000000 18,138.063 us 360.1967 us 986.0327 us 8.87 As you can see, there’s a HUGE difference between Ordinal and Invariant.
When dealing with 100.000 items,
StringComparison.InvariantCultureIgnoreCaseis 12 times slower thanStringComparison.OrdinalIgnoreCase!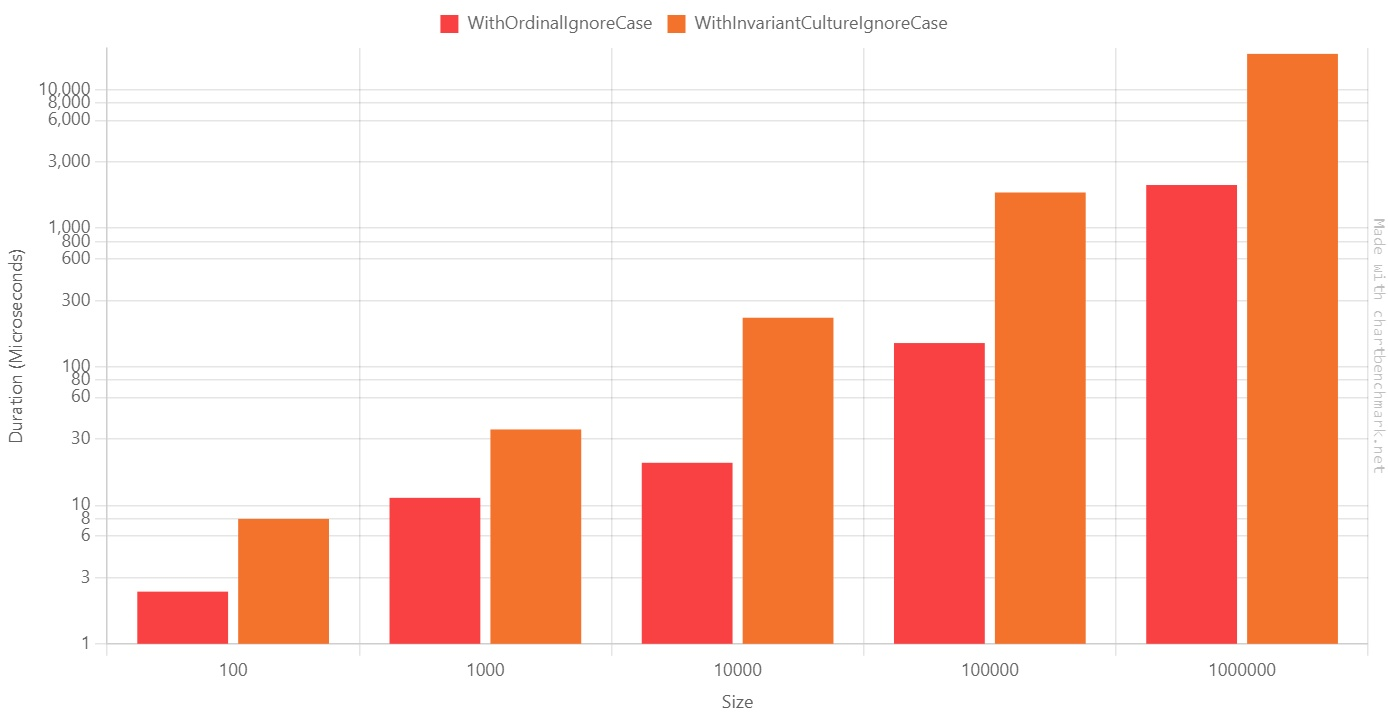
Why? Also, why should we use one instead of the other?
Have a look at this code snippet:
var s1 = "Aa"; var s2 = "A" + new string('\u0000', 3) + "a"; string.Equals(s1, s2, StringComparison.InvariantCultureIgnoreCase); //True string.Equals(s1, s2, StringComparison.OrdinalIgnoreCase); //FalseAs you can see,
s1ands2represent equivalent, but not equal, strings. We can then deduce thatOrdinalIgnoreCasechecks for the exact values of the characters, whileInvariantCultureIgnoreCasechecks the string’s “meaning”.So, in most cases, you might want to use
OrdinalIgnoreCase(as always, it depends on your use case!)Tip #6: Newtonsoft vs System.Text.Json: it’s a matter of memory allocation, not time
For the last benchmark, I created the exact same model used as an example in the official documentation.
This benchmark aims to see which JSON serialization library is faster: Newtonsoft or System.Text.Json?
[MemoryDiagnoser] public class JsonSerializerComparison { [Params(100, 10_000, 1_000_000)] public int Size; List<User?> Users { get; set; } [IterationSetup] public void Setup() { Users = UsersCreator.GenerateUsers(Size); } [Benchmark(Baseline = true)] public void WithJson() { foreach (User? user in Users) { var asString = System.Text.Json.JsonSerializer.Serialize(user); _ = System.Text.Json.JsonSerializer.Deserialize<User?>(asString); } } [Benchmark] public void WithNewtonsoft() { foreach (User? user in Users) { string asString = Newtonsoft.Json.JsonConvert.SerializeObject(user); _ = Newtonsoft.Json.JsonConvert.DeserializeObject<User?>(asString); } } }As you might know, the .NET team has added lots of performance improvements to the JSON Serialization functionalities, and you can really see the difference!
Method Size Mean Error StdDev Median Ratio RatioSD Gen0 Gen1 Allocated Alloc Ratio WithJson 100 2.063 ms 0.1409 ms 0.3927 ms 1.924 ms 1.00 0.00 – – 292.87 KB 1.00 WithNewtonsoft 100 4.452 ms 0.1185 ms 0.3243 ms 4.391 ms 2.21 0.39 – – 882.71 KB 3.01 WithJson 10000 44.237 ms 0.8787 ms 1.3936 ms 43.873 ms 1.00 0.00 4000.0000 1000.0000 29374.98 KB 1.00 WithNewtonsoft 10000 78.661 ms 1.3542 ms 2.6090 ms 78.865 ms 1.77 0.08 14000.0000 1000.0000 88440.99 KB 3.01 WithJson 1000000 4,233.583 ms 82.5804 ms 113.0369 ms 4,202.359 ms 1.00 0.00 484000.0000 1000.0000 2965741.56 KB 1.00 WithNewtonsoft 1000000 5,260.680 ms 101.6941 ms 108.8116 ms 5,219.955 ms 1.24 0.04 1448000.0000 1000.0000 8872031.8 KB 2.99 As you can see, Newtonsoft is 2x slower than System.Text.Json, and it allocates 3x the memory compared with the other library.
So, well, if you don’t use library-specific functionalities, I suggest you replace Newtonsoft with System.Text.Json.
Wrapping up
In this article, we learned that even tiny changes can make a difference in the long run.
Let’s recap some:
- Using StringBuilder is generally WAY faster than using string concatenation unless you need to concatenate 2 to 4 strings;
- Sometimes, the difference is not about execution time but memory usage;
- EndsWith and StartsWith perform better if you look for a char instead of a string. If you think of it, it totally makes sense!
- More often than not, string.IsNullOrWhiteSpace performs better checks than string.IsNullOrEmpty; however, there is a huge difference in terms of performance, so you should pick the correct method depending on the usage;
- ToUpper and ToLower look similar; however, ToLower is quite faster than ToUpper;
- Ordinal and Invariant comparison return the same value for almost every input; but Ordinal is faster than Invariant;
- Newtonsoft performs similarly to System.Text.Json, but it allocates way more memory.
This article first appeared on Code4IT 🐧
My suggestion is always the same: take your time to explore the possibilities! Toy with your code, try to break it, benchmark it. You’ll find interesting takes!
I hope you enjoyed this article! Let’s keep in touch on Twitter or LinkedIn! 🤜🤛
Happy coding!
🐧
- the class is marked with the
-
[ENG] MVPbuzzChat with Davide Bellone
About the author
Davide Bellone is a Principal Backend Developer with more than 10 years of professional experience with Microsoft platforms and frameworks.
He loves learning new things and sharing these learnings with others: that’s why he writes on this blog and is involved as speaker at tech conferences.
He’s a Microsoft MVP 🏆, conference speaker (here’s his Sessionize Profile) and content creator on LinkedIn.
-

How to kill a process running on a local port in Windows | Code4IT
Now you can’t run your application because another process already uses the port. How can you find that process? How to kill it?
Table of Contents
Just a second! 🫷
If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .If you want to support this blog, please ensure that you have disabled the adblocker for this site.
I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.Thank you for your understanding.
– DavideSometimes, when trying to run your ASP.NET application, there’s something stopping you.
Have you ever found a message like this?
Failed to bind to address https://127.0.0.1:7261: address already in use.
You can try over and over again, you can also restart the application, but the port still appears to be used by another process.
How can you find the process that is running on a local port? How can you kill it to free up the port and, eventually, be able to run your application?
In this article, we will learn how to find the blocking port in Windows 10 and Windows 11, and then we will learn how to kill that process given its PID.
How to find the process running on a port on Windows 11 using PowerShell
Let’s see how to identify the process that is running on port 7261.
Open a PowerShell and run the
netstatcommand:NETSTAT is a command that shows info about the active TCP/IP network connections. It accepts several options. In this case, we will use:
-n: Displays addresses and port numbers in numerical form.-o: Displays the owning process ID associated with each connection.-a: Displays all connections and listening ports;-p: Filter for a specific protocol (TCP or UDP)
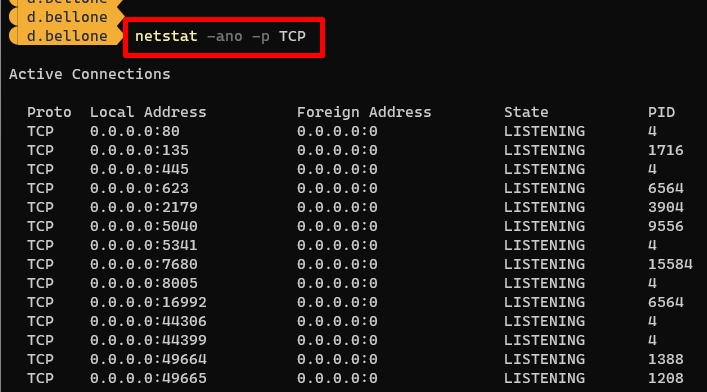
Notice that the last column lists the PID (Process ID) bound to each connection.
From here, we can use the
findstrcommand to get only the rows with a specific string (the searched port number).netstat -noa -p TCP | findstr 7261
Now, by looking at the last column, we can identify the Process ID: 19160.
How to kill a process given its PID on Windows or PowerShell
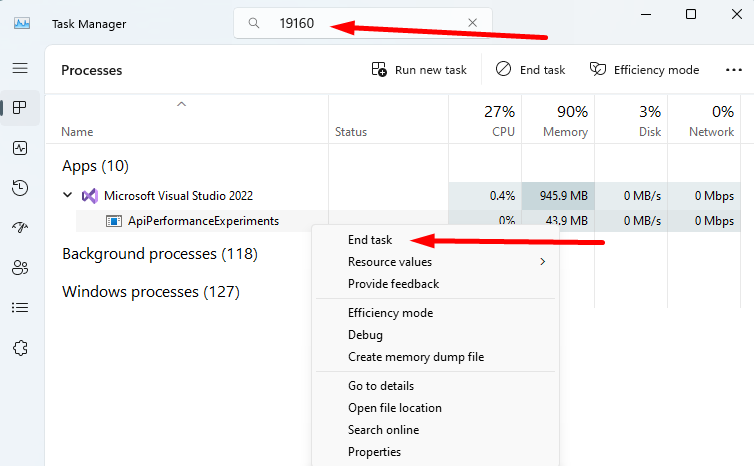
Now that we have the Process ID (PID), we can open the Task Manager, paste the PID value in the topmost textbox, and find the related application.
In our case, it was an instance of Visual Studio running an API application. We can now kill the process by hitting End Task.
If you prefer working with PowerShell, you can find the details of the related process by using the
Get-Processcommand: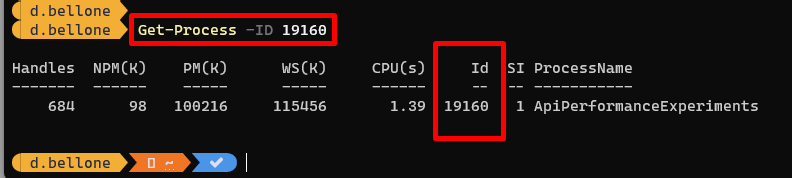
Then, you can use the
taskkillcommand by specifying the PID, using the/PIDflag, and adding the/Fflag to force the killing of the process.We have killed the process related to the running application. Visual Studio is still working, of course.
Further readings
Hey, what are these fancy colours on the PowerShell?
It’s a customization I added to show the current folder and the info about the associated GIT repository. It’s incredibly useful while developing and navigating the file system with PowerShell.
This article first appeared on Code4IT 🐧
Wrapping up
As you can imagine, this article exists because I often forget how to find the process that stops my development.
It’s always nice to delve into these topics to learn more about what you can do with PowerShell and which flags are available for a command.
I hope you enjoyed this article! Let’s keep in touch on Twitter or LinkedIn! 🤜🤛
Happy coding!
🐧
-

C# Tip: ObservableCollection – a data type to intercept changes to the collection | Code4IT
Just a second! 🫷
If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .If you want to support this blog, please ensure that you have disabled the adblocker for this site.
I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.Thank you for your understanding.
– DavideImagine you need a way to raise events whenever an item is added or removed from a collection.
Instead of building a new class from scratch, you can use
ObservableCollection<T>to store items, raise events, and act when the internal state of the collection changes.In this article, we will learn how to use
ObservableCollection<T>, an out-of-the-box collection available in .NET.Introducing the ObservableCollection type
ObservableCollection<T>is a generic collection coming from theSystem.Collections.ObjectModelnamespace.It allows the most common operations, such as
Add<T>(T item)andRemove<T>(T item), as you can expect from most of the collections in .NET.Moreover, it implements two interfaces:
INotifyCollectionChangedcan be used to raise events when the internal collection is changed.INotifyPropertyChangedcan be used to raise events when one of the properties of the changes.
Let’s see a simple example of the usage:
var collection = new ObservableCollection<string>(); collection.Add("Mario"); collection.Add("Luigi"); collection.Add("Peach"); collection.Add("Bowser"); collection.Remove("Luigi"); collection.Add("Waluigi"); _ = collection.Contains("Peach"); collection.Move(1, 2);As you can see, we can do all the basic operations: add, remove, swap items (with the
Movemethod), and check if the collection contains a specific value.You can simplify the initialization by passing a collection in the constructor:
var collection = new ObservableCollection<string>(new string[] { "Mario", "Luigi", "Peach" }); collection.Add("Bowser"); collection.Remove("Luigi"); collection.Add("Waluigi"); _ = collection.Contains("Peach"); collection.Move(1, 2);How to intercept changes to the underlying collection
As we said, this data type implements
INotifyCollectionChanged. Thanks to this interface, we can add event handlers to theCollectionChangedevent and see what happens.var collection = new ObservableCollection<string>(new string[] { "Mario", "Luigi", "Peach" }); collection.CollectionChanged += WhenCollectionChanges; Console.WriteLine("Adding Bowser..."); collection.Add("Bowser"); Console.WriteLine(""); Console.WriteLine("Removing Luigi..."); collection.Remove("Luigi"); Console.WriteLine(""); Console.WriteLine("Adding Waluigi..."); collection.Add("Waluigi"); Console.WriteLine(""); Console.WriteLine("Searching for Peach..."); var containsPeach = collection.Contains("Peach"); Console.WriteLine(""); Console.WriteLine("Swapping items..."); collection.Move(1, 2);The
WhenCollectionChangesmethod accepts aNotifyCollectionChangedEventArgsthat gives you info about the intercepted changes:private void WhenCollectionChanges(object? sender, NotifyCollectionChangedEventArgs e) { var allItems = ((IEnumerable<object>)sender)?.Cast<string>().ToArray() ?? new string[] { "<empty>" }; Console.WriteLine($"> Currently, the collection is {string.Join(',', allItems)}"); Console.WriteLine($"> The operation is {e.Action}"); var previousItems = e.OldItems?.Cast<string>()?.ToArray() ?? new string[] { "<empty>" }; Console.WriteLine($"> Before the operation it was {string.Join(',', previousItems)}"); var currentItems = e.NewItems?.Cast<string>()?.ToArray() ?? new string[] { "<empty>" }; Console.WriteLine($"> Now, it is {string.Join(',', currentItems)}"); }Every time an operation occurs, we write some logs.
The result is:
Adding Bowser... > Currently, the collection is Mario,Luigi,Peach,Bowser > The operation is Add > Before the operation it was <empty> > Now, it is Bowser Removing Luigi... > Currently, the collection is Mario,Peach,Bowser > The operation is Remove > Before the operation it was Luigi > Now, it is <empty> Adding Waluigi... > Currently, the collection is Mario,Peach,Bowser,Waluigi > The operation is Add > Before the operation it was <empty> > Now, it is Waluigi Searching for Peach... Swapping items... > Currently, the collection is Mario,Bowser,Peach,Waluigi > The operation is Move > Before the operation it was Peach > Now, it is PeachNotice a few points:
- the
senderproperty holds the current items in the collection. It’s anobject?, so you have to cast it to another type to use it. - the
NotifyCollectionChangedEventArgshas different meanings depending on the operation:- when adding a value,
OldItemsis null andNewItemscontains the items added during the operation; - when removing an item,
OldItemscontains the value just removed, andNewItemsisnull. - when swapping two items, both
OldItemsandNewItemscontain the item you are moving.
- when adding a value,
How to intercept when a collection property has changed
To execute events when a property changes, we need to add a delegate to the
PropertyChangedevent. However, it’s not available directly on theObservableCollectiontype: you first have to cast it to anINotifyPropertyChanged:var collection = new ObservableCollection<string>(new string[] { "Mario", "Luigi", "Peach" }); (collection as INotifyPropertyChanged).PropertyChanged += WhenPropertyChanges; Console.WriteLine("Adding Bowser..."); collection.Add("Bowser"); Console.WriteLine(""); Console.WriteLine("Removing Luigi..."); collection.Remove("Luigi"); Console.WriteLine(""); Console.WriteLine("Adding Waluigi..."); collection.Add("Waluigi"); Console.WriteLine(""); Console.WriteLine("Searching for Peach..."); var containsPeach = collection.Contains("Peach"); Console.WriteLine(""); Console.WriteLine("Swapping items..."); collection.Move(1, 2);We can now specify the
WhenPropertyChangesmethod as such:private void WhenPropertyChanges(object? sender, PropertyChangedEventArgs e) { var allItems = ((IEnumerable<object>)sender)?.Cast<string>().ToArray() ?? new string[] { "<empty>" }; Console.WriteLine($"> Currently, the collection is {string.Join(',', allItems)}"); Console.WriteLine($"> Property {e.PropertyName} has changed"); }As you can see, we have again the
senderparameter that contains the collection of items.Then, we have a parameter of type
PropertyChangedEventArgsthat we can use to get the name of the property that has changed, using thePropertyNameproperty.Let’s run it.
Adding Bowser... > Currently, the collection is Mario,Luigi,Peach,Bowser > Property Count has changed > Currently, the collection is Mario,Luigi,Peach,Bowser > Property Item[] has changed Removing Luigi... > Currently, the collection is Mario,Peach,Bowser > Property Count has changed > Currently, the collection is Mario,Peach,Bowser > Property Item[] has changed Adding Waluigi... > Currently, the collection is Mario,Peach,Bowser,Waluigi > Property Count has changed > Currently, the collection is Mario,Peach,Bowser,Waluigi > Property Item[] has changed Searching for Peach... Swapping items... > Currently, the collection is Mario,Bowser,Peach,Waluigi > Property Item[] has changedAs you can see, for every add/remove operation, we have two events raised: one to say that the
Counthas changed, and one to say that the internalItem[]is changed.However, notice what happens in the Swapping section: since you just change the order of the items, the
Countproperty does not change.This article first appeared on Code4IT 🐧
Final words
As you probably noticed, events are fired after the collection has been initialized. Clearly, it considers the items passed in the constructor as the initial state, and all the subsequent operations that mutate the state can raise events.
Also, notice that events are fired only if the reference to the value changes. If the collection holds more complex classes, like:
public class User { public string Name { get; set; } }No event is fired if you change the value of the
Nameproperty of an object already part of the collection:var me = new User { Name = "Davide" }; var collection = new ObservableCollection<User>(new User[] { me }); collection.CollectionChanged += WhenCollectionChanges; (collection as INotifyPropertyChanged).PropertyChanged += WhenPropertyChanges; me.Name = "Updated"; // It does not fire any event!Notice that
ObservableCollection<T>is not thread-safe! You can find an interesting article by Gérald Barré (aka Meziantou) where he explains a thread-safe version ofObservableCollection<T>he created. Check it out!As always, I suggest exploring the language and toying with the parameters, properties, data types, etc.
You’ll find lots of exciting things that may come in handy.
I hope you enjoyed this article! Let’s keep in touch on Twitter or LinkedIn! 🤜🤛
Happy coding!
🐧
-

Happy June Sale! 🎁
At Browserling and Online Tools we love sales.
We just created a new automated sale called Happy June Sale.
Now each June on the first day we show a 50% discount offer to all users who visit our site. BOOM SHAKA LAKA!
Buy a Sub Now!
What Is Browserling?
Browserling is an online service that lets you test how other websites look and work in different web browsers, like Chrome, Firefox, or Safari, without needing to install them. It runs real browsers on real machines and streams them to your screen, kind of like remote desktop but focused on browsers. This helps web developers and regular users check for bugs, suspicious links, and weird stuff that happens in certain browsers. You just go to Browserling, pick a browser and version, and then enter the site you want to test. It’s quick, easy, and works from your browser with no downloads or installs.
What Are Online Tools?
Online Tools is an online service that offers free, browser-based productivity tools for everyday tasks like editing text, converting files, editing images, working with code, and way more. It’s an all-in-one Digital Swiss Army Knife with 1500+ utilities, so you can find the exact tool you need without installing anything. Just open the site, use what you need, and get things done fast.
Who Uses Browserling and Online Tools?
Browserling and Online Tools are used by millions of regular internet users, developers, designers, students, and even Fortune 100 companies. Browserling is handy for testing websites in different browsers without having to install them. Online Tools are used for simple tasks like resizing or converting images, or even fixing small file problems quickly without downloading any apps.

Buy a subscription now and see you next time!
-
Browserling Coupon Code (Summer 2025) ☀
As the summer heat rolls in, it’s time to cool off your browsing experience with Browserling!
I’m excited to offer you an exclusive summer deal: use the coupon code
SUNNYLING25at the checkout to get a special discount on my service.Stay cool and productive with Browserling – your web testing companion for the sunny season.
PS. Today is the last day this coupon is valid.