When working with data, you will often move between SQL databases and Pandas DataFrames. SQL is excellent for storing and retrieving data, while Pandas is ideal for analysis inside Python.
In this article, we show how both can be used together, using a football (soccer) mini-league dataset. We build a small SQLite database in memory, read the data into Pandas, and then solve real analytics questions.
There are neither pythons or pandas in Bulgaria. Just software.
Setup – SQLite and Pandas
We start by importing the libraries and creating three tables –
[teams,players,matches] inside an SQLite in-memory database.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
importsqlite3
importpandas aspd
importnumpy asnp
conn=sqlite3.connect(“:memory:”)
cur=conn.cursor()
cur.executescript(“””
DROP TABLE IF EXISTS teams;
DROP TABLE IF EXISTS players;
DROP TABLE IF EXISTS matches;
CREATE TABLE teams (
team TEXT PRIMARY KEY,
city TEXT NOT NULL,
founded INTEGER NOT NULL
);
CREATE TABLE players (
player_id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
team TEXT NOT NULL REFERENCES teams(team),
pos TEXT NOT NULL,
age INTEGER NOT NULL,
goals INTEGER NOT NULL,
assists INTEGER,
minutes INTEGER NOT NULL
);
CREATE TABLE matches (
match_id INTEGER PRIMARY KEY AUTOINCREMENT,
date TEXT NOT NULL,
home TEXT NOT NULL,
away TEXT NOT NULL,
home_goals INTEGER NOT NULL,
away_goals INTEGER NOT NULL
);
INSERT INTO teams(team, city, founded) VALUES
(‘Lions’,’Sofia’, 2015),
(‘Wolves’,’Plovdiv’,1914),
(‘Eagles’,’Varna’,1930);
INSERT INTO players(name, team, pos, age, goals, assists, minutes) VALUES
(‘Ivan Petrov’,’Lions’,’FW’,24,11,3,1350),
(‘Martin Kolev’,’Lions’,’MF’,29,4,NULL,1490),
(‘Rui Costa’,’Lions’,’DF’,31,1,2,1600),
(‘Georgi Iliev’,’Wolves’,’FW’,27,7,5,1410),
(‘Joe Jackson’,’Wolves’,’FW’,27,17,5,410),
(‘Peter Marin’,’Eagles’,’FW’,20,5,1,870);
INSERT INTO matches(date,home,away,home_goals,away_goals) VALUES
(‘2024-08-03′,’Lions’,’Wolves’,2,1),
(‘2024-08-10′,’Eagles’,’Lions’,1,3),
(‘2024-08-17′,’Wolves’,’Eagles’,2,2);
“””)
conn.commit()
Now, we have three tables.
Loading SQL Data into Pandas
pd.read_sql does the magic to load either a table or a custom query directly.
teams=pd.read_sql(“SELECT * FROM teams”,conn)
players=pd.read_sql(“SELECT * FROM players”,conn)
matches=pd.read_sql(“SELECT * FROM matches”,conn,parse_dates=[“date”])
print(teams)
print(players.head())
print(matches)
At this point, the SQL data is ready for analysis with Pandas.
SQL vs Pandas – Filtering Rows
Task: Find forwards (FW) with more than 1200 minutes on the field:
Average teams aim at 100% Code Coverage just to reach the number. Great teams don’t. Why?
Table of Contents
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
Code Coverage is a valuable metric in software development, especially when it comes to testing. It provides insights into how much of your codebase is exercised by your test suite.
However, we must recognize that Code Coverage alone should not be the ultimate goal of your testing strategy. It has some known limitations, and 100% Code Coverage does not guarantee your code to be bug-free.
In this article, we’ll explore why Code Coverage matters, its limitations, and how to balance achieving high coverage and effective testing. We’ll use C# to demonstrate when Code Coverage works well and how you can cheat on the result.
What Is Code Coverage?
Code Coverage measures the percentage of code lines, branches, or statements executed during testing. It helps answer questions like:
How much of my code is tested?
Are there any untested paths or dead code?
Which parts of the application need additional test coverage?
In C#, tools like Cobertura, dotCover, and Visual Studio’s built-in coverage analysis provide Code Coverage reports.
You may be tempted to think that the higher the coverage, the better the quality of your tests. However, we will soon demonstrate why this assumption is misleading.
Why Code Coverage Matters
Clearly, if you write valuable tests, Code Coverage is a great ally.
A high value of Code Coverage helps you with:
Risk mitigation: High Code Coverage reduces the risk of undiscovered defects. If a piece of code isn’t covered, it will likely contain bugs.
Preventing regressions: code is destined to evolve over time. If you ensure that most of your code is covered by tests, whenever you’ll add some more code you will discover which parts of the existing system are impacted by your changes. If you update the production code and no test fails, it might be a bad sign: you probably need to cover the code you are modifying with enough tests.
Quality assurance: Code Coverage ensures that critical parts of your application are tested thoroughly. Good tests focus on the functional aspects of the code (what) rather than on the technical aspects (how). A good test suite is a safety net against regressions.
Guidance for Testing Efforts: Code Coverage highlights areas that need more attention. It guides developers in writing additional tests where necessary.
The Limitations of Code Coverage
While Code Coverage is valuable, it has limitations:
False Sense of Security: Achieving 100% coverage doesn’t guarantee bug-free software. It’s possible to have well-covered code that still contains subtle defects. This is especially true when mocking dependencies.
They focus on Lines, Not Behavior: Code Coverage doesn’t consider the quality of tests. It doesn’t guarantee that the tests covers all possible scenarios.
Ignored Edge Cases: Some code paths (exception handling, rare conditions) are complex to cover. High coverage doesn’t necessarily mean thorough testing.
3 Practical reasons why Code Coverage percentage can be misleading
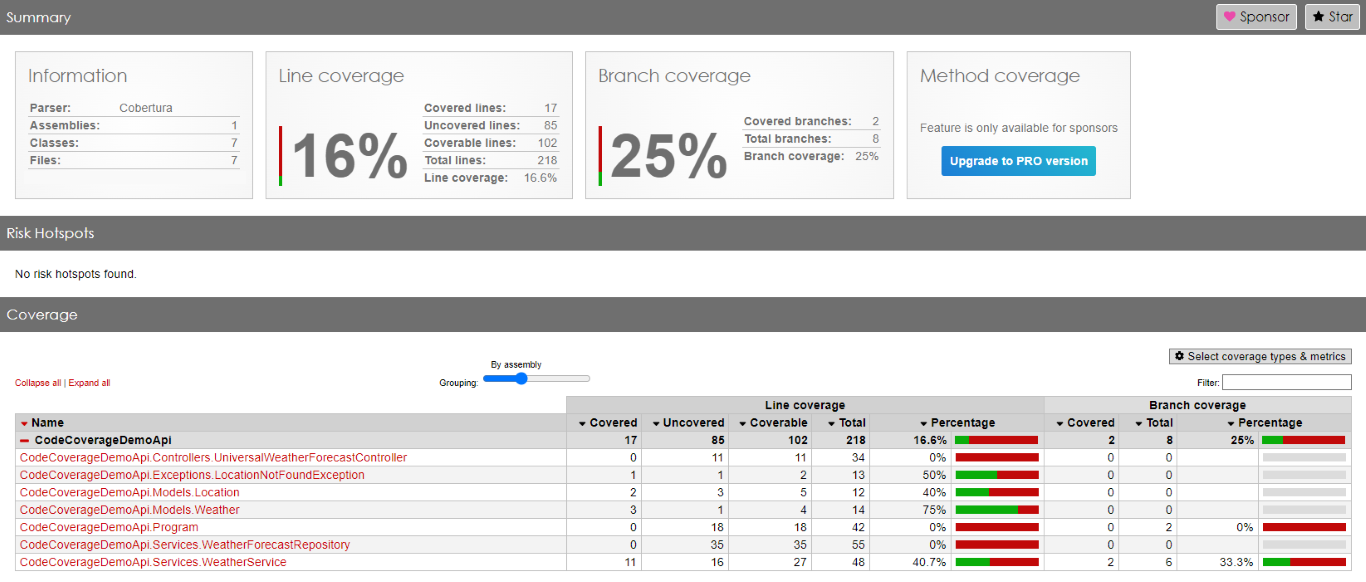
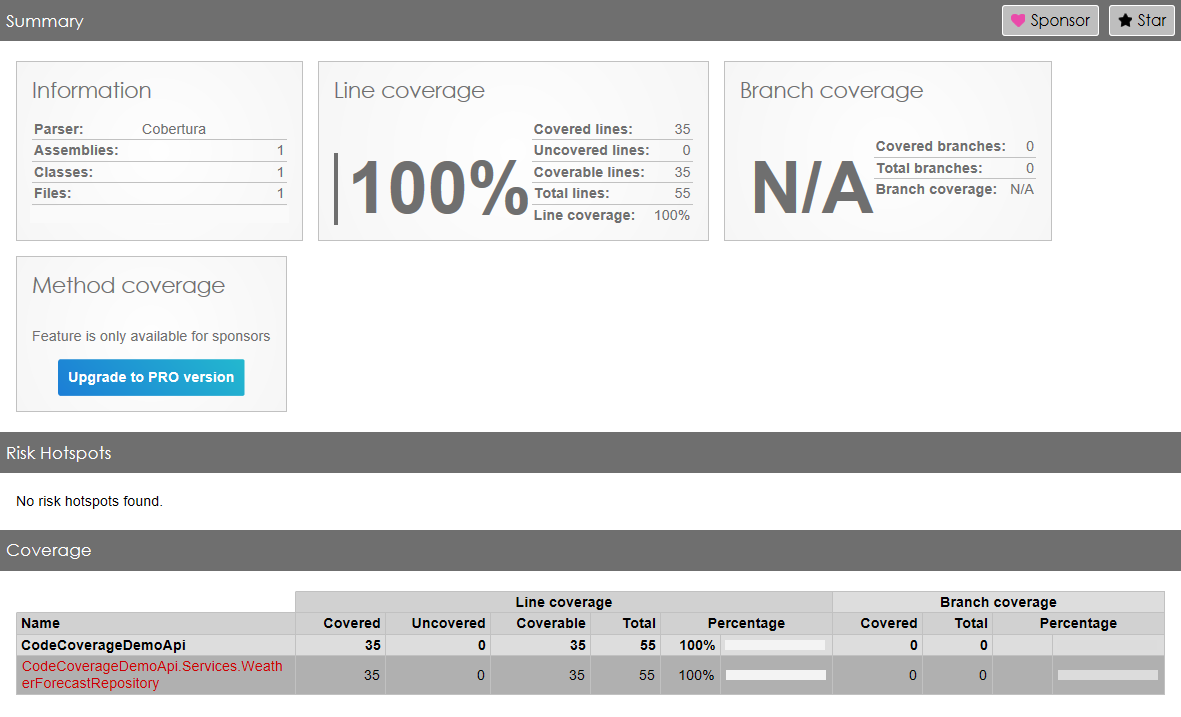
For the sake of this article, I’ve created a dummy .NET API project with the typical three layers: controller, service, and repository.
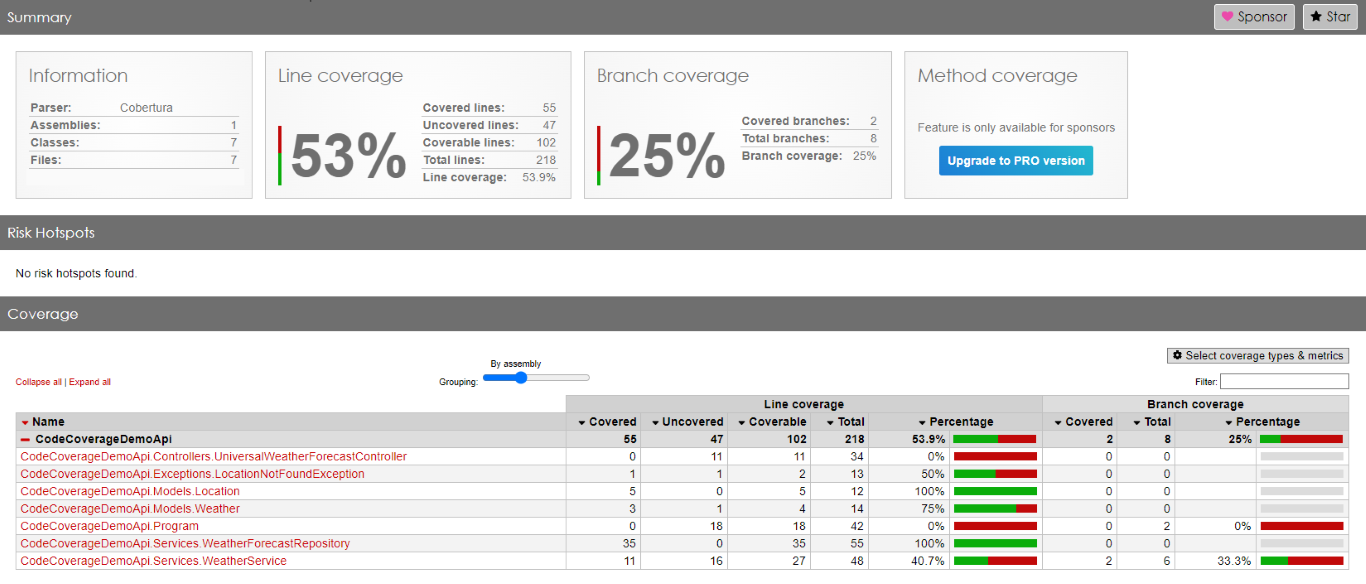
Here we are: we have reached 53% of total Code Coverage by adding one single test, which does not provide any value!
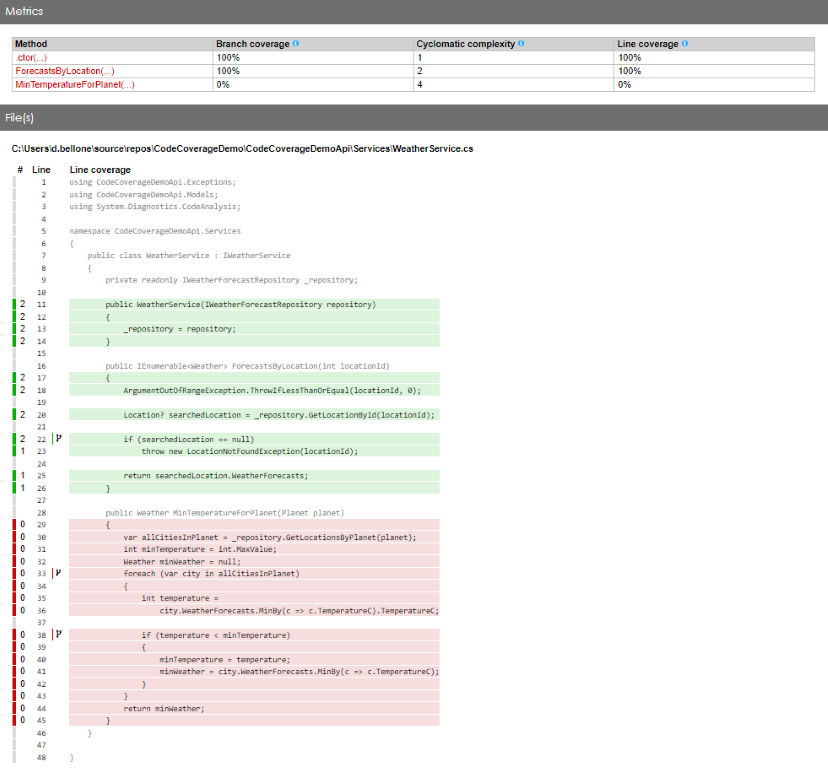
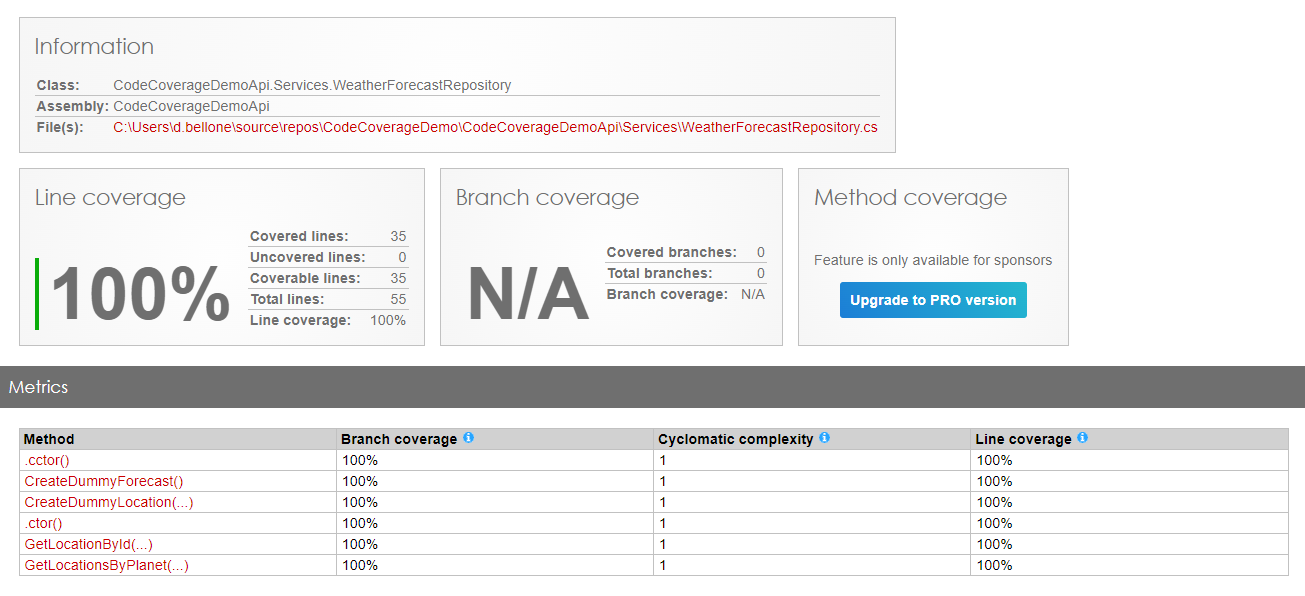
As you can see, in fact, the WeatherForecastRepository has now reached 100% Code Coverage.
Great job! Or is it?
You can cheat by excluding parts of the code
In C# there is a handy attribute that you can apply to methods and classes: ExcludeFromCodeCoverage.
While this attribute can be useful for classes that you cannot test, it can be used to inflate the Code Coverage percentage by applying it to classes and methods you don’t want to test (maybe because you are lazy?).
We can, in fact, add that attribute to every single class like this:
You can then add the same attribute to all the other classes – even the Program class! – to reach 100% Code Coverage without writing lots of test.
Note: to reach 100% I had to exclude everything but the tests on the Repository: otherwise, if I had exactly zero methods under tests, the final Code Coverage would’ve been 0.
As we saw, high Code Coverage is not enough. It’s a good starting point, but it must not be the final goal.
We can, indeed, focus our efforts in different areas:
Test Quality: Prioritize writing meaningful tests over chasing high coverage. Focus on edge cases, boundary values, and scenarios that matter to users.
Mutation Testing: Instead of just measuring coverage, consider mutation testing. It introduces artificial defects and checks if tests catch them.
Finally, my suggestion is to focus on integration tests rather than on unit tests: this testing strategy is called Testing Diamond.
Further readings
To generate Code Coverage reports, I used Coverlet, as I explained in this article (which refers to Visual Studio 2019, but the steps are still valid with newer versions).
In my opinion, we should not focus all our efforts on Unit Tests. On the contrary, we should write more Integration Tests to ensure that the functionality, as a whole, works correctly.
This way of defining tests is called Testing Diamond, and I explained it here:
Code Coverage is a useful metric but should not be the end goal. Aim for a balance: maintain good coverage while ensuring effective testing. Remember that quality matters more than mere numbers. Happy testing! 🚀
I hope you enjoyed this article! Let’s keep in touch on Twitter or LinkedIn! 🤜🤛
In modern web development, there are times when a page needs to refresh itself without the user pressing a button. Whether you are responding to updated content, clearing form inputs, or forcing a session reset, JavaScript provides a simple method for this task: location.reload().
This built-in method belongs to the window.location object and allows developers to programmatically reload the current web page. It is a concise and effective way to refresh a page under controlled conditions, without relying on user interaction.
What Is JavaScript location.reload()?
The location.reload() method refreshes the page it is called on. In essence, it behaves the same way a user would if they clicked the browser’s reload button. However, because it is called with JavaScript, the action can be triggered automatically or in response to specific events.
Here is the most basic usage:
location.reload();
This line of code tells the browser to reload the current page. It does not require any parameters by default and typically loads the page from the browser’s cache. Note that you can use our free resources (namely, online code editors) to follow along with this discussion.
Forcing a Hard Reload
Sometimes a regular reload is not enough, especially when you want to ensure that the browser fetches the latest version of the file from the server instead of using the cached copy. You can force a hard reload by passing true as a parameter:
location.reload(true);
However, it is important to note that modern browsers have deprecated this parameter in many cases. Instead, they treat all reloads the same. If you need to fully bypass the cache, server-side headers or a versioned URL might be a more reliable approach.
And let’s talk syntax:
So what about the false parameter? That reloads the page using the web browser cache. Note that false is also the default parameter. So if you run reload() without a parameter, you’re actually running object.reload(false). This is covered in the Mozilla developer docs.
So when do you use Location.reload(true)? One common situation is when the page has outdated information. A hard reload can also bypass caching issues on the client side.
Common Use Cases
The location.reload() method is used across a wide range of situations. Here are a few specific scenarios where it’s especially useful:
This use case helps clear form inputs or reset the page state after the form has been processed. You can test this in the online Javascript editor. No download required. Just enter the code and click run to immediately see how it looks.
2. Refresh after receiving new data:
In web applications that rely on live data, such as dashboards or status monitors, developers might use location.reload() to ensure the page displays the most current information after an update.
This is a simple way to give users control over when to reload, particularly in apps that fetch new content periodically.
4. Reload a Page Without Keeping the Current Page in Session History
This is another common use. It looks like this.
window.location.replace(window.location.href);
Basically, if a user presses the back button after they hit reload, they might be taken back to a page that no longer reflects the current application logic. The widow.location.replace() method navigates to a new URL, often the same one, and replaces the current page in the session history.
This effectively reloads the page without leaving a trace in the user’s history stack. It is particularly useful for login redirects, post-submission screens, or any scenario where you want to reset the page without allowing users to revisit the previous state using the back button.
Limitations and Best Practices
While location.reload() is useful; it should be used thoughtfully. Frequent or automatic reloads can frustrate users, especially if they disrupt input or navigation. In modern development, reloading an entire page is sometimes considered a heavy-handed approach.
For dynamic updates, using JavaScript to update only part of the page, through DOM manipulation or asynchronous fetch requests, is often more efficient and user-friendly.
Also, keep in mind that reloading clears unsaved user input and resets page state. It can also cause data to be resubmitted if the page was loaded through a form POST, which may trigger browser warnings or duplicate actions. If you’re looking for a job, make sure to brush up on this and any other common JavaScript interview questions.
Smarter Alternatives to Reloading the Page
While location.reload() is simple and effective, it is often more efficient to update only part of a page rather than reloading the entire thing. Reloading can interrupt the user experience, clear form inputs, and lead to unnecessary data usage. In many cases, developers turn to asynchronous techniques that allow content to be refreshed behind the scenes.
AJAX, which stands for Asynchronous JavaScript and XML, was one of the earliest ways to perform background data transfers without refreshing the page. It allows a web page to send or receive data from a server and update only the necessary parts of the interface. Although the term AJAX often brings to mind older syntax and XML data formats, the concept remains vital and is now commonly used with JSON and modern JavaScript methods.
One of the most popular modern approaches is the Fetch API. Introduced as a cleaner and more flexible alternative to XMLHttpRequest, the Fetch API uses promises to handle asynchronous requests. It allows developers to retrieve or send data from a server and then apply those updates directly to the page using the Document Object Model, or DOM.
This example retrieves data from the server and updates only a single element on the page. It is fast, efficient, and keeps the user interface responsive.
By using AJAX or the Fetch API, developers can create a more fluid and interactive experience. These tools allow for partial updates, background syncing, and real-time features without forcing users to wait for an entire page to reload. In a world where performance and responsiveness matter more than ever, these alternatives offer a more refined approach to managing content updates on the web.
Conclusion
The location.reload() method in JavaScript is a straightforward way to refresh the current web page. Whether used for resetting the interface or updating content, it offers a quick and accessible solution for common front-end challenges. But like all tools in web development, it should be used with an understanding of its impact on user experience.
Before reaching for a full page reload, consider whether updating the page’s content directly might serve your users better. When applied appropriately, location.reload() can be a useful addition to your JavaScript toolkit.
Want to put this into action? Add it to a JavaScript project and test it out.