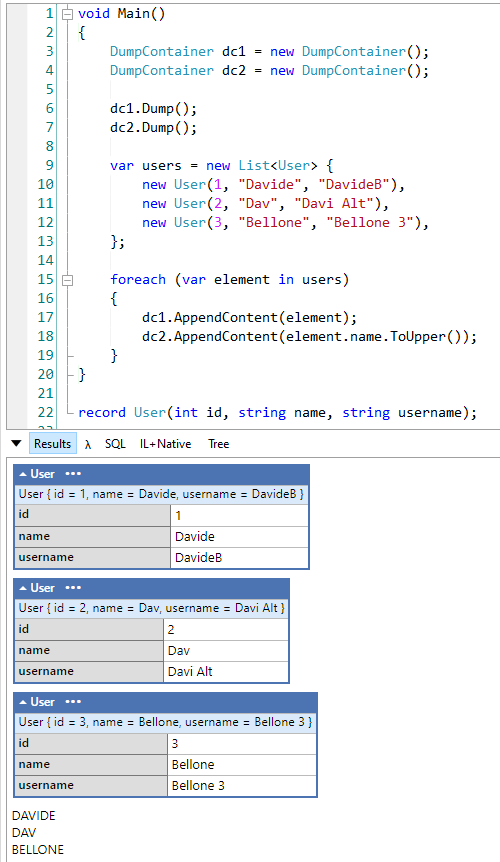
With Log4J’s vulnerability, we’ve all been reminded that systems are vulnerable, and OSS are not immune too. What should we do now?
Table of Contents
Just a second! 🫷
If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .If you want to support this blog, please ensure that you have disabled the adblocker for this site.
I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.Thank you for your understanding.
– Davide
After the Log4J vulnerability, we should reflect on how open source impacts our projects, and what are the benefits and disadvantages of using such libraries.
The following article is more an opinion, just some random thoughts about what happened and what we can learn from this event.
A recap of the Log4J vulnerability
To give some context to those who have never heard (or forgot) about the Log4J vulnerability, here’s a short recap.
Log4J is a popular Java library for logging. So popular that it has been inglobed in the Apache ecosystem.
For some reason I haven’t understood, the logger evaluates the log messages instead of just treating them as strings. So, a kind of SQL injection (but for logs) could be executed: by sending a specific string format to services that use Log4J, that string is evaluated and executed on the server; as a result, external scripts could be run on the server, allowing attackers to access your server. Of course, it’s not a detailed and 100% accurate description: there are plenty of resources on the Internet if you want to deep dive into this topic.
Some pieces of evidence show that the earliest exploitation of this vulnerability happened on Dec 1, 2021, as stated by Matthew Prince, CEO of Cloudflare, in this Tweet. But the vulnerability became public 9 days later.
Benefits of OSS projects
The source code of Log4J is publicly available on GitHub
This means that:
it’s free to use (yes, OSS != free, but it’s rare to find paid OSS projects)
you can download and run the source code
you can inspect the code and propose changes
it saves you time: you don’t have to reinvent the wheel – everything is already done by others.
Issues with OSS projects
Given that the source code is publicly accessible, attackers can study it to find security flaws, and – of course – take advantage of those vulnerabilities before the community notices them.
Most of the time, OSS projects are created by single devs to solve their specific problems. Then, they share those repositories to help their peers and allow other devs to work on the library. All the coding is done for free and in their spare time. As you can expect, the quality is deeply impacted by this.
What to do with OSS projects?
So, what should we do with all those OSS projects? Should we stop using them?
I don’t think so. just because those kinds of issues can arise, it doesn’t mean that they will arise so often.
Also, it’s pretty stupid to build everything from scratch “just in case”. Just because attackers don’t know the source code, it doesn’t mean that they can’t find a way to access your systems.
On the other hand, we should not blindly use every library we see on GitHub. It’s not true that just because it’s open source, it’s safe to use – as the Log4J story taught us.
So, what should we do?
I don’t have an answer. But for sure we can perform some operations when working on our projects.
We should review which external packages we’re using, and keep track of their version. Every N months, we should write a recap (even an Excel file is enough) to update the list of packages we’re using. In this way, if a vulnerability is discovered for a package, and a patch is released, we can immediately apply that patch to our applications.
Finding installed dependencies for .NET projects is quite simple: you can open the csproj file and see the list of NuGet packages you’re using.

The problem with this approach is that you don’t see the internal dependencies: if one of the packages you’re using depends on another package with a known vulnerability, your application may be vulnerable too.
How can you list all your dependencies? Are there any tools that work with your programming language? Drop a comment below, it can help other devs!
Then, before choosing a project instead of another, we should answer (at least) three questions. Does this package solve our problem? Does the code look safe to use? Is the repository active, or is it stale?
Spend some time skimming the source code, looking for weird pieces of code. Pay attention when they evaluate the code (possible issues like with Log4J), when they perform unexpected calls to external services (are they tracking you?), and so on.
Look at the repository history: is the repository still being updated? Is it maintained by a single person, or is there a community around it?
You can find this info on GitHub under the Insight tab.
In the following picture, you can see the contributions to the Log4J library (available here):

Does this repo have tests? Without tests (or, maybe worse, with not meaningful tests), the package should not be considered safe. Have a look at the code and at the CI pipelines, if publicly available.
Finally, a hope for a future: to define a standard and some procedures to rate the security of a package/repository. I don’t know if it can be feasible, but it would be a good addition to the OSS world.
Further readings
If you’re interested in the general aspects of the Log4J vulnerability, you can have a look at this article by the Wall Street Journal:
🔗What Is the Log4j Vulnerability? What to Know | The Wall Street Journal
If you prefer a more technical article, DataDog’s blog got you covered. In particular, jump to the “How the Log4Shell vulnerability works” section.
🔗Takeaways from the Log4j Log4Shell vulnerability | DataDog
But if you prefer some even more technical info, you can head to the official vulnerability description:
Here’s the JIRA ticket created to track it:
🔗JNDI lookups in layout (not message patterns) enabled in Log4j2 < 2.16.0 | Jira
Wrapping up
This was not the usual article/tutorial, it was more an opinion on the current status of OSS and on what we should do to avoid issues like those caused by Log4J.
It’s not the first vulnerability, and for sure it won’t be the only one.
What do you think? Should we move away from OSS?
How would you improve the OSS world?
Happy coding!
🐧