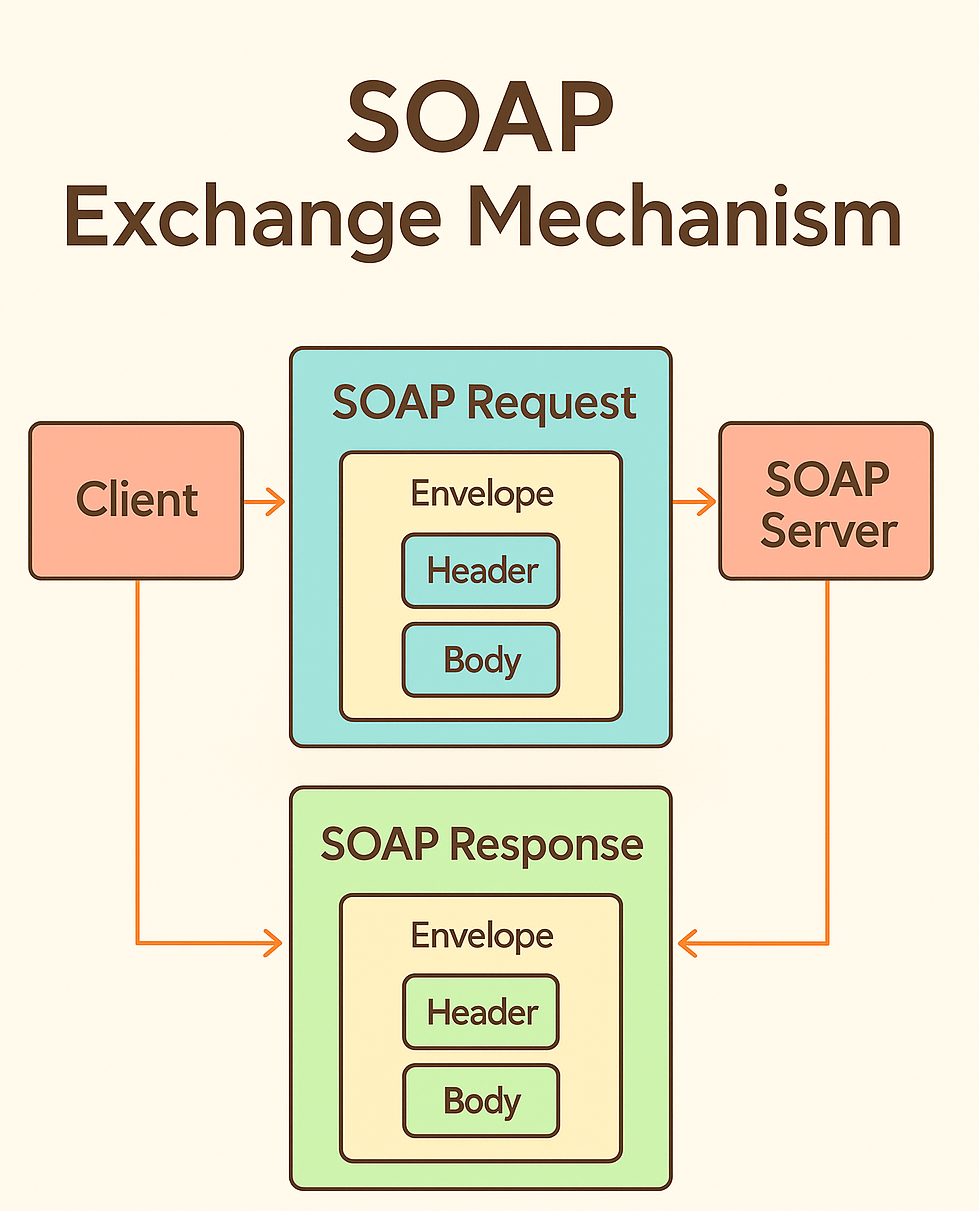
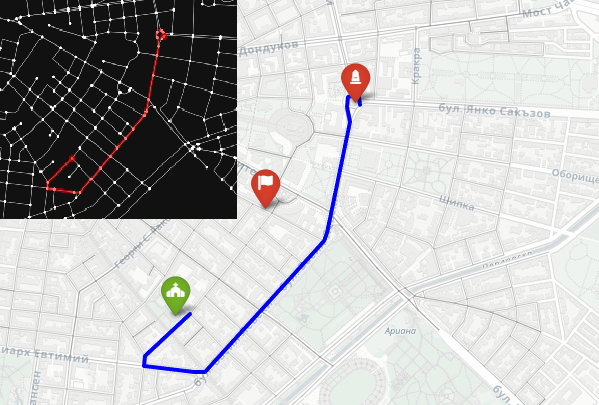
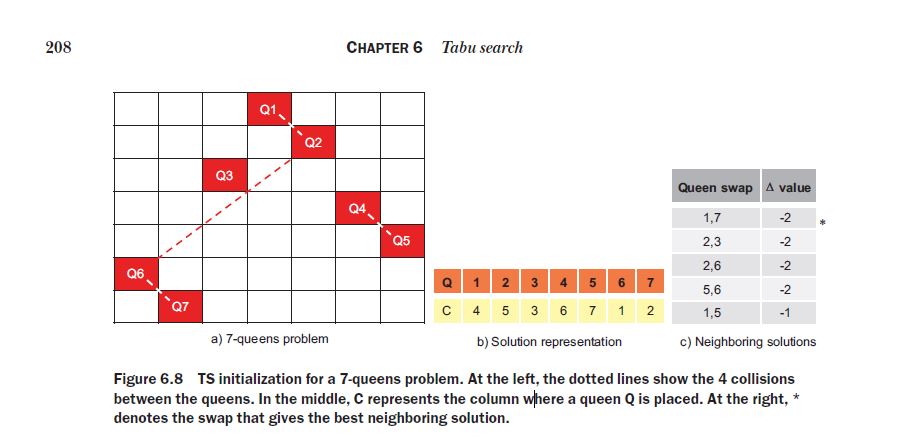
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import (
confusion_matrix, precision_score, recall_score,
roc_auc_score, average_precision_score, precision_recall_curve
)
# 1) Load a tiny cusomer churn CSV called churn.csv
df = pd.read_csv(“churn.csv”)
# 2) Do quick, safe checks – missing values and class balance.
missing_share = df.isna().mean().sort_values(ascending=False)
class_share = df[“churn”].value_counts(normalize=True).rename(“share”)
print(“Missing share (top 5):\n”, missing_share.head(5), “\n”)
print(“Class share:\n”, class_share, “\n”)
# 3) Split data into train, validation, test – 60-20-20.
X = df.drop(columns=[“churn”]); y = df[“churn”]
X_tr, X_te, y_tr, y_te = train_test_split(X, y, test_size=0.20, stratify=y, random_state=13)
X_tr, X_va, y_tr, y_va = train_test_split(X_tr, y_tr, test_size=0.25, stratify=y_tr, random_state=13)
neg, pos = int((y_tr==0).sum()), int((y_tr==1).sum())
spw = neg / max(pos, 1)
print(f“Shapes -> train {X_tr.shape}, val {X_va.shape}, test {X_te.shape}”)
print(f“Class balance in train -> neg {neg}, pos {pos}, scale_pos_weight {spw:.2f}\n”)
# Wrap as DMatrix (fast internal format)
feat_names = list(X.columns)
dtr = xgb.DMatrix(X_tr, label=y_tr, feature_names=feat_names)
dva = xgb.DMatrix(X_va, label=y_va, feature_names=feat_names)
dte = xgb.DMatrix(X_te, label=y_te, feature_names=feat_names)
# 4) Train XGBoost with early stopping using the Booster API.
params = dict(
objective=“binary:logistic”,
eval_metric=“aucpr”,
tree_method=“hist”,
max_depth=5,
eta=0.03,
subsample=0.8,
colsample_bytree=0.8,
reg_lambda=1.0,
scale_pos_weight=spw
)
bst = xgb.train(params, dtr, num_boost_round=4000, evals=[(dva, “val”)],
early_stopping_rounds=200, verbose_eval=False)
print(“Best trees (baseline):”, bst.best_iteration)
# 6) Choose a practical decision treshold from validation – “a line in the sand”.
p_va = bst.predict(dva, iteration_range=(0, bst.best_iteration + 1))
pre, rec, thr = precision_recall_curve(y_va, p_va)
f1 = 2 * pre * rec / np.clip(pre + rec, 1e–9, None)
t_best = float(thr[np.argmax(f1[:–1])])
print(“Chosen threshold t_best (validation F1):”, round(t_best, 3), “\n”)
# 7) Explain results on the test set in plain terms – confusion matrix, precision, recall, ROC AUC, PR AUC
p_te = bst.predict(dte, iteration_range=(0, bst.best_iteration + 1))
pred = (p_te >= t_best).astype(int)
cm = confusion_matrix(y_te, pred)
print(“Confusion matrix:\n”, cm)
print(“Precision:”, round(precision_score(y_te, pred), 3))
print(“Recall :”, round(recall_score(y_te, pred), 3))
print(“ROC AUC :”, round(roc_auc_score(y_te, p_te), 3))
print(“PR AUC :”, round(average_precision_score(y_te, p_te), 3), “\n”)
# 8) See which column mattered most
# (a hint – if people start calling the call centre a lot, most probably there is a problem and they will quit using your service)
imp = pd.Series(bst.get_score(importance_type=“gain”)).sort_values(ascending=False)
print(“Top features by importance (gain):\n”, imp.head(10), “\n”)
# 9) Add two business rules with monotonic constraints
cons = [0]*len(feat_names)
if “debt_ratio” in feat_names: cons[feat_names.index(“debt_ratio”)] = 1 # non-decreasing
if “tenure_months” in feat_names: cons[feat_names.index(“tenure_months”)] = –1 # non-increasing
mono = “(“ + “,”.join(map(str, cons)) + “)”
params_cons = params.copy()
params_cons.update({“monotone_constraints”: mono, “max_bin”: 512})
bst_cons = xgb.train(params_cons, dtr, num_boost_round=4000, evals=[(dva, “val”)],
early_stopping_rounds=200, verbose_eval=False)
print(“Best trees (constrained):”, bst_cons.best_iteration)
# 10) Compare the quality of bst_cons and bst with a few lines.
p_cons = bst_cons.predict(dte, iteration_range=(0, bst_cons.best_iteration + 1))
print(“PR AUC baseline vs constrained:”, round(average_precision_score(y_te, p_te), 3),
“vs”, round(average_precision_score(y_te, p_cons), 3))
print(“ROC AUC baseline vs constrained:”, round(roc_auc_score(y_te, p_te), 3),
“vs”, round(roc_auc_score(y_te, p_cons), 3), “\n”)
# 11) Save both models
bst.save_model(“easy_xgb_base.ubj”)
bst_cons.save_model(“easy_xgb_cons.ubj”)
print(“Saved models: easy_xgb_base.ubj, easy_xgb_cons.ubj”)