Every project begins with a spark of curiosity. It often emerges from exploring techniques outside the web and imagining how they might translate into interactive experiences. In this case, inspiration came from a dive into particle simulations.
The Concept
The core idea for this project came after watching a tutorial on creating cell-like particles using the xParticles plugin for Cinema 4D. The team often draws inspiration from 3D motion design techniques, and the question frequently arises in the studio: “Wouldn’t this be cool if it were interactive?” That’s where the idea was born.
After building our own set up in C4D based on the example, we created a general motion prototype to demonstrate the interaction. The result was a kind of repelling effect, where the cells displaced according to the cursor’s position. To create the demo, we added a simple sphere and gave it a collider tag so that the particles would be pushed away as the sphere moved through the simulation, emulating the mouse movement. An easy way to add realistic movement is to add a vibrate tag to the collider, and play around with the movement levels and frequency until it looks good.
Art Direction
With the base particle and interaction demo sorted, we rendered out the sequence and moved in After Effects to start playing around with the look and feel. We knew we wanted to give the particles a unique quality, one that felt more stylised as opposed to ultra realistic or scientific. After some exploration we landed on a lo-fi gradient mapped look, which felt like an interesting direction to move forward with. We achieved this by layer up a few effects:
Effect > Generate > 4 Colour Gradient: Add this to a new shape layer. This black and white gradient will act as a mask to control the blur intensities.
Effect > Blur > Camera Blur: Add this to a new adjustment layer. This general blur will smooth out the particles.
Effect > Blur > Compound Blur: Add this to the same adjustment layer as above. Set the blur layer to use the same shape layer we applied to the 4 colour gradient as its mask, make sure it is set to “Effects & Mask” mode in the drop down.
Effect > Color Correction > Colorama: Add this as a new adjustment layer. This is where the fun starts! You can add custom gradients into the output cycle and play around with the phase shift to customise the look according to your preference.
Next, we designed a simple UI to match the futuristic cell-based visual direction. A concept we felt would work well for a bio-tech company – so created a simple brand with key messaging to fit and voila! That’s the concept phase complete.
(Hot tip: If you’re doing an interaction concept in 3d software like C4D, create a plane with a cursor texture on and parent it to your main interaction component – in the case, the sphere collider. Render that out as a sequence so that it matches up perfectly with your simulation – you can then layer it over text, etc, and UI in After Effects)
Technical Approach and Tools
As this was a simple one page static site without need of a backend, we used our in-house boilerplate using Astro with Vite and Three.js. For the physics, we went with Rapier as it handles collision detection efficiently and is compatible with Three.js. That was our main requirement, since we didn’t need simulations or soft-body calculations.
For the Cellular Technology project, we specifically wanted to show how you can achieve a satisfying result without overcrowding the screen with tons of features or components. Our key focus was the visuals and interactivity – to make this satisfying for the user, it needed to feel smooth and seamless. A fluid-like simulation is a good way to achieve this. At Unseen, we often implement this effect as an added interaction component. For this project, we wanted to take a slightly different approach that would still achieve a similar result.
Based on the concept from our designers, there were a couple of directions for the implementation to consider. To keep the experience optimised, even at a large scale, having the GPU handle the majority of the calculations is usually the best approach. For this, we’d need the effect to be in a shader, and use more complicated implementations such as packing algorithms and custom voronoi-like patterns. However, after testing the Rapier library, we realised that simple rigid body object collision would suffice in re-creating the concept in real-time.
Physics Implementation
To do so, we needed to create a separate physics world next to our 3D rendered world, as the Rapier library only handles the physics calculations, and the graphics are left for the implementation of the developer’s choosing.
Here’s a snippet from the part were we create the rigid bodies:
for (let i = 0; i < this.numberOfBodies; i++) {
const x = Math.random() * this.bounds.x - this.bounds.x * 0.5
const y = Math.random() * this.bounds.y - this.bounds.y * 0.5
const z = Math.random() * (this.bounds.z * 0.95) - (this.bounds.z * 0.95) * 0.5
const bodyDesc = RAPIER.RigidBodyDesc.dynamic().setTranslation(x, y, z)
bodyDesc.setGravityScale(0.0) // Disable gravity
bodyDesc.setLinearDamping(0.7)
const body = this.physicsWorld.createRigidBody(bodyDesc)
const radius = MathUtils.mapLinear(Math.random(), 0.0, 1.0, this._cellSizeRange[0], this._cellSizeRange[1])
const colliderDesc = RAPIER.ColliderDesc.ball(radius)
const collider = this.physicsWorld.createCollider(colliderDesc, body)
collider.setRestitution(0.1) // bounciness 0 = no bounce, 1 = full bounce
this.bodies.push(body)
this.colliders.push(collider)
}
The meshes that represent the bodies are created separately, and on each tick, their transforms get updated by those from the physics engine.
// update mesh positions
for (let i = 0; i < this.numberOfBodies; i++) {
const body = this.bodies[i]
const position = body.translation()
const collider = this.colliders[i]
const radius = collider.shape.radius
this._dummy.position.set(position.x, position.y, position.z)
this._dummy.scale.setScalar(radius)
this._dummy.updateMatrix()
this.mesh.setMatrixAt(i, this._dummy.matrix)
}
this.mesh.instanceMatrix.needsUpdate = true
With performance in mind, we first decided to try the 2D version of the Rapier library, however it soon became clear that with cells distributed only in one plane, the visual was not convincing enough. The performance impact of additional calculations in the Z plane was justified by the improved result.
Building the Visual with Post Processing
Evidently, the post processing effects play a big role in this project. By far the most important is the blur, which makes the cells go from clear simple rings to a fluid, gooey mass. We implemented the Kawase blur, which is similar to Gaussian blur, but uses box blurring instead of the Gaussian function and is more performant at higher levels of blur. We applied it to only some parts of the screen to keep visual interest.
This already brought the implementation closer to the concept. Another vital part of the experience is the color-grading, where we mapped the colours to the luminosity of elements in the scene. We couldn’t resist adding our typical fluid simulation, so the colours get slightly offset based on the fluid movement.
if (uFluidEnabled) {
fluidColor = texture2D(tFluid, screenCoords);
fluid = pow(luminance(abs(fluidColor.rgb)), 1.2);
fluid *= 0.28;
}
vec3 color1 = uColor1 - fluid * 0.08;
vec3 color2 = uColor2 - fluid * 0.08;
vec3 color3 = uColor3 - fluid * 0.08;
vec3 color4 = uColor4 - fluid * 0.08;
if (uEnabled) {
// apply a color grade
color = getColorRampColor(brightness, uStops.x, uStops.y, uStops.z, uStops.w, color1, color2, color3, color4);
}
color += color * fluid * 1.5;
color = clamp(color, 0.0, 1.0);
color += color * fluidColor.rgb * 0.09;
gl_FragColor = vec4(color, 1.0);
Performance Optimisation
With the computational power required for the physics engine increasing quickly due to the number of calculations required, we aimed to make the experience as optimised as possible. The first step was to find the minimum number of cells without affecting the visual too much, i.e. without making the cells too sparse. To do so, we minimised the area in which the cells get created and made the cells slightly larger.
Another important step was to make sure no calculation is redundant, meaning each calculation must be justified by a result visible on the screen. To make sure of that, we limited the area in which cells get created to only just cover the screen, regardless of the screen size. This basically means that all cells in the scene are visible in the camera. Usually this approach involves a slightly more complex derivation of the bounding area, based on the camera field of view and distance from the object, however, for this project, we used an orthographic camera, which simplifies the calculations.
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
From C# 6 on, you can use the when keyword to specify a condition before handling an exception.
Consider this – pretty useless, I have to admit – type of exception:
publicclassRandomException : System.Exception
{
publicint Value { get; }
public RandomException()
{
Value = (new Random()).Next();
}
}
This exception type contains a Value property which is populated with a random value when the exception is thrown.
What if you want to print a different message depending on whether the Value property is odd or even?
You can do it this way:
try{
thrownew RandomException();
}
catch (RandomException re)
{
if(re.Value % 2 == 0)
Console.WriteLine("Exception with even value");
else Console.WriteLine("Exception with odd value");
}
But, well, you should keep your catch blocks as simple as possible.
That’s where the when keyword comes in handy.
CSharp when clause
You can use it to create two distinct catch blocks, each one of them handles their case in the cleanest way possible.
try{
thrownew RandomException();
}
catch (RandomException re) when (re.Value % 2 == 0)
{
Console.WriteLine("Exception with even value");
}
catch (RandomException re)
{
Console.WriteLine("Exception with odd value");
}
You must use the when keyword in conjunction with a condition, which can also reference the current instance of the exception being caught. In fact, the condition references the Value property of the RandomException instance.
A real usage: HTTP response errors
Ok, that example with the random exception is a bit… useless?
Let’s see a real example: handling different HTTP status codes in case of failing HTTP calls.
In the following snippet, I call an endpoint that returns a specified status code (506, in my case).
try{
var endpoint = "https://mock.codes/506";
var httpClient = new HttpClient();
var response = await httpClient.GetAsync(endpoint);
response.EnsureSuccessStatusCode();
}
catch (HttpRequestException ex) when (ex.StatusCode == (HttpStatusCode)506)
{
Console.WriteLine("Handle 506: Variant also negotiates");
}
catch (HttpRequestException ex)
{
Console.WriteLine("Handle another status code");
}
If the response is not a success, the response.EnsureSuccessStatusCode() throws an exception of type HttpRequestException. The thrown exception contains some info about the returned status code, which we can use to route the exception handling to the correct catch block using when (ex.StatusCode == (HttpStatusCode)506).
In case of unmanageable error, should you return null or throw exceptions?
Table of Contents
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
When you don’t have any fallback operation to manage null values (eg: retry pattern), you should throw an exception instead of returning null.
You will clean up your code and make sure that, if something cannot be fixed, it gets caught as soon as possible.
Don’t return null or false
Returning nulls impacts the readability of your code. The same happens for boolean results for operations. And you still have to catch other exceptions.
Take this example:
bool SaveOnFileSystem(ApiItem item)
{
// save on file systemreturnfalse;
}
ApiItem GetItemFromAPI(string apiId)
{
var httpResponse = GetItem(apiId);
if (httpResponse.StatusCode == 200)
{
return httpResponse.Content;
}
else {
returnnull;
}
}
DbItem GetItemFromDB()
{
// returns the item or nullreturnnull;
}
If all those methods complete successfully, they return an object (DbItem, ApiItem, or true); if they fail, they return null or false.
How can you consume those methods?
void Main()
{
var itemFromDB = GetItemFromDB();
if (itemFromDB != null)
{
var itemFromAPI = GetItemFromAPI(itemFromDB.ApiId);
if (itemFromAPI != null)
{
bool successfullySaved = SaveOnFileSystem(itemFromAPI);.
if (successfullySaved)
Console.WriteLine("Saved");
}
}
Console.WriteLine("Cannot save the item");
}
Note that there is nothing we can do in case something fails. So, do we really need all that nesting? We can do better!
Throw Exceptions instead
Let’s throw exceptions instead:
void SaveOnFileSystem(ApiItem item)
{
// save on file systemthrownew FileSystemException("Cannot save item on file system");
}
ApiItem GetItemFromAPI(string apiId)
{
var httpResponse = GetItem(apiId);
if (httpResponse.StatusCode == 200)
{
return httpResponse.Content;
}
else {
thrownew ApiException("Cannot download item");
}
}
DbItem GetItemFromDB()
{
// returns the item or throws an exceptionthrownew DbException("item not found");
}
Here, each method can complete in two statuses: it either completes successfully or it throws an exception of a type that tells us about the operation that failed.
We can then consume the methods in this way:
void Main()
{
try {
var itemFromDB = GetItemFromDB();
var itemFromAPI = GetItemFromAPI(itemFromDB.ApiId);
SaveOnFileSystem(itemFromAPI);
Console.WriteLine("Saved");
}
catch(Exception ex)
{
Console.WriteLine("Cannot save the item");
}
}
Now the reader does not have to spend time reading the nested operations, it’s all more linear and immediate.
Conclusion
Remember, this way of writing code should be used only when you cannot do anything if an operation failed. You should use exceptions carefully!
Now, a question for you: if you need more statuses as a return type of those methods (so, not only “success” and “fail”, but also some other status like “partially succeeded”), how would you transform that code?
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
You already know it: using meaningful names for variables, methods, and classes allows you to write more readable and maintainable code.
It may happen that a good name for your business entity matches one of the reserved keywords in C#.
What to do, now?
There are tons of reserved keywords in C#. Some of these are
int
interface
else
null
short
event
params
Some of these names may be a good fit for describing your domain objects or your variables.
Talking about variables, have a look at this example:
var eventList = GetFootballEvents();
foreach(vareventin eventList)
{
// do something}
That snippet will not work, since event is a reserved keyword.
You can solve this issue in 3 ways.
You can use a synonym, such as action:
var eventList = GetFootballEvents();
foreach(var action in eventList)
{
// do something}
But, you know, it doesn’t fully match the original meaning.
You can use the my prefix, like this:
var eventList = GetFootballEvents();
foreach(var myEvent in eventList)
{
// do something}
But… does it make sense? Is it really your event?
The third way is by using the @ prefix:
var eventList = GetFootballEvents();
foreach(var @event in eventList)
{
// do something}
That way, the code is still readable (even though, I admit, that @ is a bit weird to see around the code).
Of course, the same works for every keyword, like @int, @class, @public, and so on
Further readings
If you are interested in a list of reserved keywords in C#, have a look at this article:
Small changes sometimes make a huge difference. Learn these 6 tips to improve the performance of your application just by handling strings correctly.
Table of Contents
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
Sometimes, just a minor change makes a huge difference. Maybe you won’t notice it when performing the same operation a few times. Still, the improvement is significant when repeating the operation thousands of times.
In this article, we will learn five simple tricks to improve the performance of your application when dealing with strings.
Note: this article is part of C# Advent Calendar 2023, organized by Matthew D. Groves: it’s maybe the only Christmas tradition I like (yes, I’m kind of a Grinch 😂).
Benchmark structure, with dependencies
Before jumping to the benchmarks, I want to spend a few words on the tools I used for this article.
The project is a .NET 8 class library running on a laptop with an i5 processor.
Running benchmarks with BenchmarkDotNet
I’m using BenchmarkDotNet to create benchmarks for my code. BenchmarkDotNet is a library that runs your methods several times, captures some metrics, and generates a report of the executions. If you follow my blog, you might know I’ve used it several times – for example, in my old article “Enum.HasFlag performance with BenchmarkDotNet”.
All the benchmarks I created follow the same structure:
the class is marked with the [MemoryDiagnoser] attribute: the benchmark will retrieve info for both time and memory usage;
there is a property named Size with the attribute [Params]: this attribute lists the possible values for the Size property;
there is a method marked as [IterationSetup]: this method runs before every single execution, takes the value from the Size property, and initializes the AllStrings array;
the methods that are parts of the benchmark are marked with the [Benchmark] attribute.
Generating strings with Bogus
I relied on Bogus to create dummy values. This NuGet library allows you to generate realistic values for your objects with a great level of customization.
The string array generation strategy is shared across all the benchmarks, so I moved it to a static method:
Here I have a default set of predefined values ([string.Empty, " ", "\n \t", null]), which can be expanded with the values coming from the additionalStrings array. These values are then placed in random positions of the array.
In most cases, though, the value of the string is defined by Bogus.
Generating plots with chartbenchmark.net
To generate the plots you will see in this article, I relied on chartbenchmark.net, a fantastic tool that transforms the output generated by BenchmarkDotNet on the console in a dynamic, customizable plot. This tool created by Carlos Villegas is available on GitHub, and it surely deserves a star!
Please note that all the plots in this article have a Log10 scale: this scale allows me to show you the performance values of all the executions in the same plot. If I used the Linear scale, you would be able to see only the biggest values.
We are ready. It’s time to run some benchmarks!
Tip #1: StringBuilder is (almost always) better than String Concatenation
Let’s start with a simple trick: if you need to concatenate strings, using a StringBuilder is generally more efficient than concatenating string.
Whenever you concatenate strings with the + sign, you create a new instance of a string. This operation takes some time and allocates memory for every operation.
On the contrary, using a StringBuilder object, you can add the strings in memory and generate the final string using a performance-wise method.
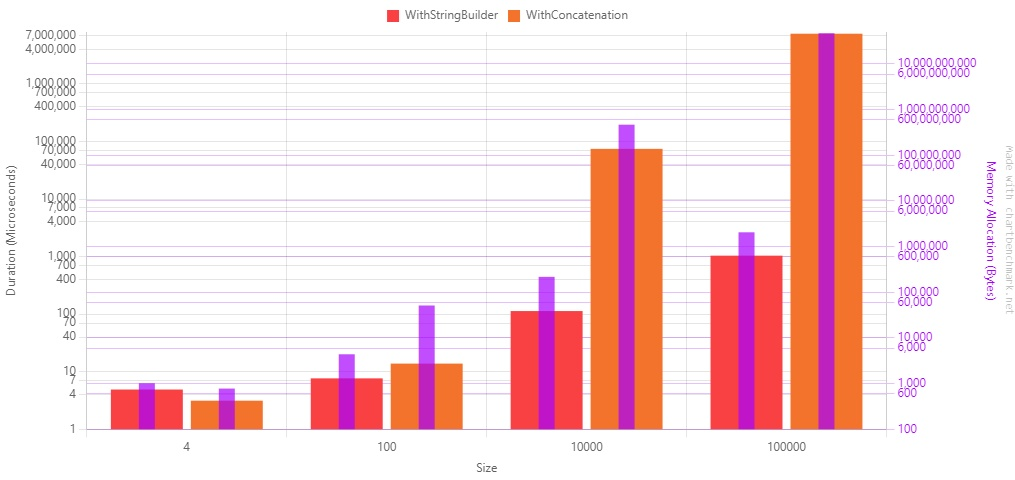
Here’s the result table:
Method
Size
Mean
Error
StdDev
Median
Ratio
RatioSD
Allocated
Alloc Ratio
WithStringBuilder
4
4.891 us
0.5568 us
1.607 us
4.750 us
1.00
0.00
1016 B
1.00
WithConcatenation
4
3.130 us
0.4517 us
1.318 us
2.800 us
0.72
0.39
776 B
0.76
WithStringBuilder
100
7.649 us
0.6596 us
1.924 us
7.650 us
1.00
0.00
4376 B
1.00
WithConcatenation
100
13.804 us
1.1970 us
3.473 us
13.800 us
1.96
0.82
51192 B
11.70
WithStringBuilder
10000
113.091 us
4.2106 us
12.081 us
111.000 us
1.00
0.00
217200 B
1.00
WithConcatenation
10000
74,512.259 us
2,111.4213 us
6,058.064 us
72,593.050 us
666.43
91.44
466990336 B
2,150.05
WithStringBuilder
100000
1,037.523 us
37.1009 us
108.225 us
1,012.350 us
1.00
0.00
2052376 B
1.00
WithConcatenation
100000
7,469,344.914 us
69,720.9843 us
61,805.837 us
7,465,779.900 us
7,335.08
787.44
46925872520 B
22,864.17
Let’s see it as a plot.
Beware of the scale in the diagram!: it’s a Log10 scale, so you’d better have a look at the value displayed on the Y-axis.
As you can see, there is a considerable performance improvement.
There are some remarkable points:
When there are just a few strings to concatenate, the + operator is more performant, both on timing and allocated memory;
When you need to concatenate 100000 strings, the concatenation is ~7000 times slower than the string builder.
In conclusion, use the StringBuilder to concatenate more than 5 or 6 strings. Use the string concatenation for smaller operations.
Edit 2024-01-08: turn out that string.Concat has an overload that accepts an array of strings. string.Concat(string[]) is actually faster than using the StringBuilder. Read more this article by Robin Choffardet.
Tip #2: EndsWith(string) vs EndsWith(char): pick the right overload
One simple improvement can be made if you use StartsWith or EndsWith, passing a single character.
There are two similar overloads: one that accepts a string, and one that accepts a char.
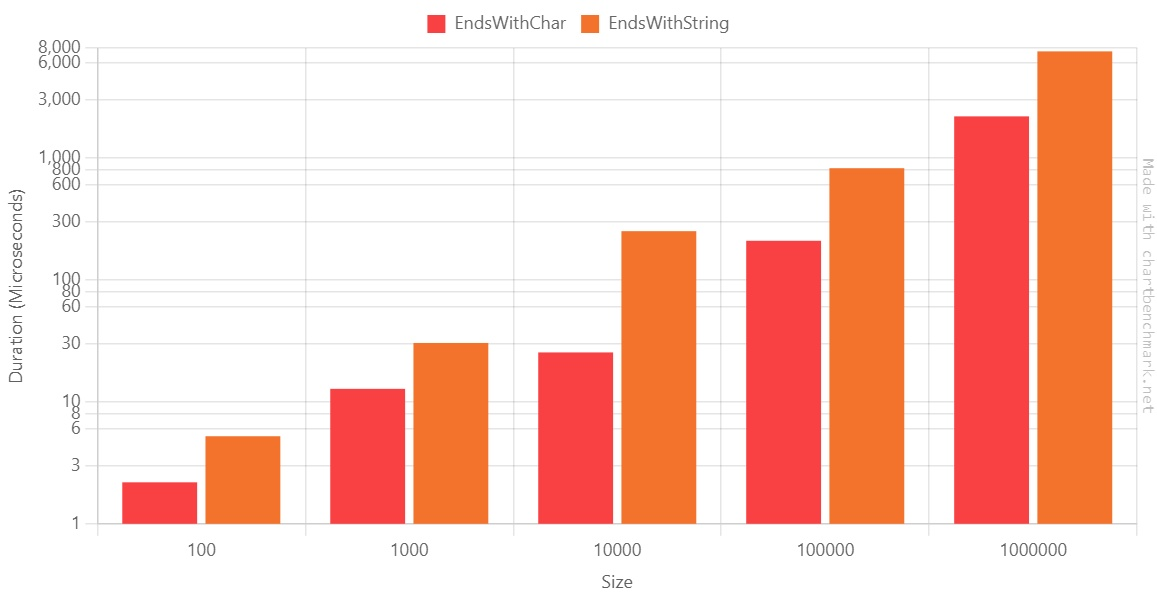
Again, let’s generate the plot using the Log10 scale:
They appear to be almost identical, but look closely: based on this benchmark, when we have 10000, using EndsWith(string) is 10x slower than EndsWith(char).
Also, here, the duration ratio on the 1.000.000-items array is ~3.5. At first, I thought there was an error on the benchmark, but when rerunning it on the benchmark, the ratio did not change.
It looks like you have the best improvement ratio when the array has ~10.000 items.
Tip #3: IsNullOrEmpty vs IsNullOrWhitespace vs IsNullOrEmpty + Trim
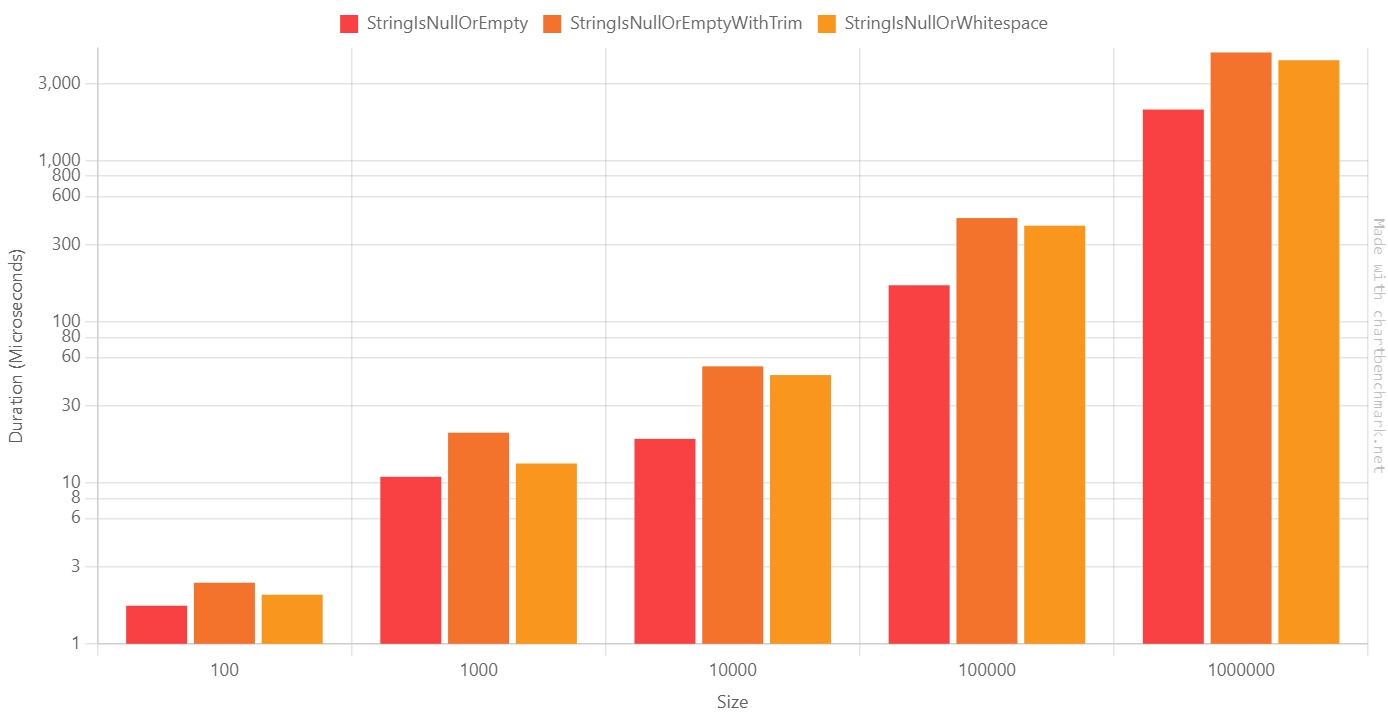
As you might know, string.IsNullOrWhiteSpace performs stricter checks than string.IsNullOrEmpty.
To demonstrate it, I have created three benchmarks: one for string.IsNullOrEmpty, one for string.IsNullOrWhiteSpace, and another one that lays in between: it first calls Trim() on the string, and then calls string.IsNullOrEmpty.
As you can see from the Log10 table, the results are pretty similar:
On average, StringIsNullOrWhitespace is ~2 times slower than StringIsNullOrEmpty.
So, what should we do? Here’s my two cents:
For all the data coming from the outside (passed as input to your system, received from an API call, read from the database), use string.IsNUllOrWhiteSpace: this way you can ensure that you are not receiving unexpected data;
If you read data from an external API, customize your JSON deserializer to convert whitespace strings as empty values;
Needless to say, choose the proper method depending on the use case. If a string like “\n \n \t” is a valid value for you, use string.IsNullOrEmpty.
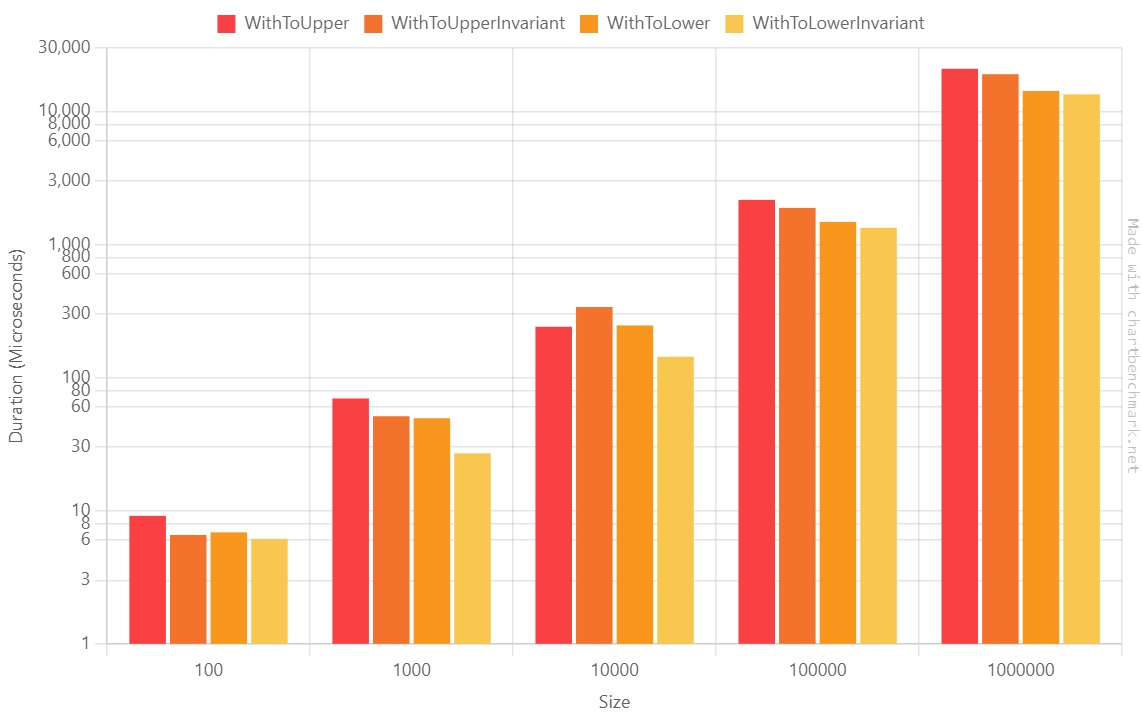
Tip #4: ToUpper vs ToUpperInvariant vs ToLower vs ToLowerInvariant: they look similar, but they are not
Even though they look similar, there is a difference in terms of performance between these four methods.
[MemoryDiagnoser]publicclassToUpperVsToLower()
{
[Params(100, 1000, 10_000, 100_000, 1_000_000)]publicint Size;
publicstring[] AllStrings { get; set; }
[IterationSetup]publicvoid Setup()
{
AllStrings = StringArrayGenerator.Generate(Size);
}
[Benchmark]publicvoid WithToUpper()
{
foreach (string s in AllStrings)
{
_ = s?.ToUpper();
}
}
[Benchmark]publicvoid WithToUpperInvariant()
{
foreach (string s in AllStrings)
{
_ = s?.ToUpperInvariant();
}
}
[Benchmark]publicvoid WithToLower()
{
foreach (string s in AllStrings)
{
_ = s?.ToLower();
}
}
[Benchmark]publicvoid WithToLowerInvariant()
{
foreach (string s in AllStrings)
{
_ = s?.ToLowerInvariant();
}
}
}
What will this benchmark generate?
Method
Size
Mean
Error
StdDev
Median
P95
Ratio
WithToUpper
100
9.153 us
0.9720 us
2.789 us
8.200 us
14.980 us
1.57
WithToUpperInvariant
100
6.572 us
0.5650 us
1.639 us
6.200 us
9.400 us
1.14
WithToLower
100
6.881 us
0.5076 us
1.489 us
7.100 us
9.220 us
1.19
WithToLowerInvariant
100
6.143 us
0.5212 us
1.529 us
6.100 us
8.400 us
1.00
WithToUpper
1000
69.776 us
9.5416 us
27.833 us
68.650 us
108.815 us
2.60
WithToUpperInvariant
1000
51.284 us
7.7945 us
22.860 us
38.700 us
89.290 us
1.85
WithToLower
1000
49.520 us
5.6085 us
16.449 us
48.100 us
79.110 us
1.85
WithToLowerInvariant
1000
27.000 us
0.7370 us
2.103 us
26.850 us
30.375 us
1.00
WithToUpper
10000
241.221 us
4.0480 us
3.588 us
240.900 us
246.560 us
1.68
WithToUpperInvariant
10000
339.370 us
42.4036 us
125.028 us
381.950 us
594.760 us
1.48
WithToLower
10000
246.861 us
15.7924 us
45.565 us
257.250 us
302.875 us
1.12
WithToLowerInvariant
10000
143.529 us
2.1542 us
1.910 us
143.500 us
146.105 us
1.00
WithToUpper
100000
2,165.838 us
84.7013 us
223.137 us
2,118.900 us
2,875.800 us
1.66
WithToUpperInvariant
100000
1,885.329 us
36.8408 us
63.548 us
1,894.500 us
1,967.020 us
1.41
WithToLower
100000
1,478.696 us
23.7192 us
50.547 us
1,472.100 us
1,571.330 us
1.10
WithToLowerInvariant
100000
1,335.950 us
18.2716 us
35.203 us
1,330.100 us
1,404.175 us
1.00
WithToUpper
1000000
20,936.247 us
414.7538 us
1,163.014 us
20,905.150 us
22,928.350 us
1.64
WithToUpperInvariant
1000000
19,056.983 us
368.7473 us
287.894 us
19,085.400 us
19,422.880 us
1.41
WithToLower
1000000
14,266.714 us
204.2906 us
181.098 us
14,236.500 us
14,593.035 us
1.06
WithToLowerInvariant
1000000
13,464.127 us
266.7547 us
327.599 us
13,511.450 us
13,926.495 us
1.00
Let’s see it as the usual Log10 plot:
We can notice a few points:
The ToUpper family is generally slower than the ToLower family;
The Invariant family is faster than the non-Invariant one; we will see more below;
So, if you have to normalize strings using the same casing, ToLowerInvariant is the best choice.
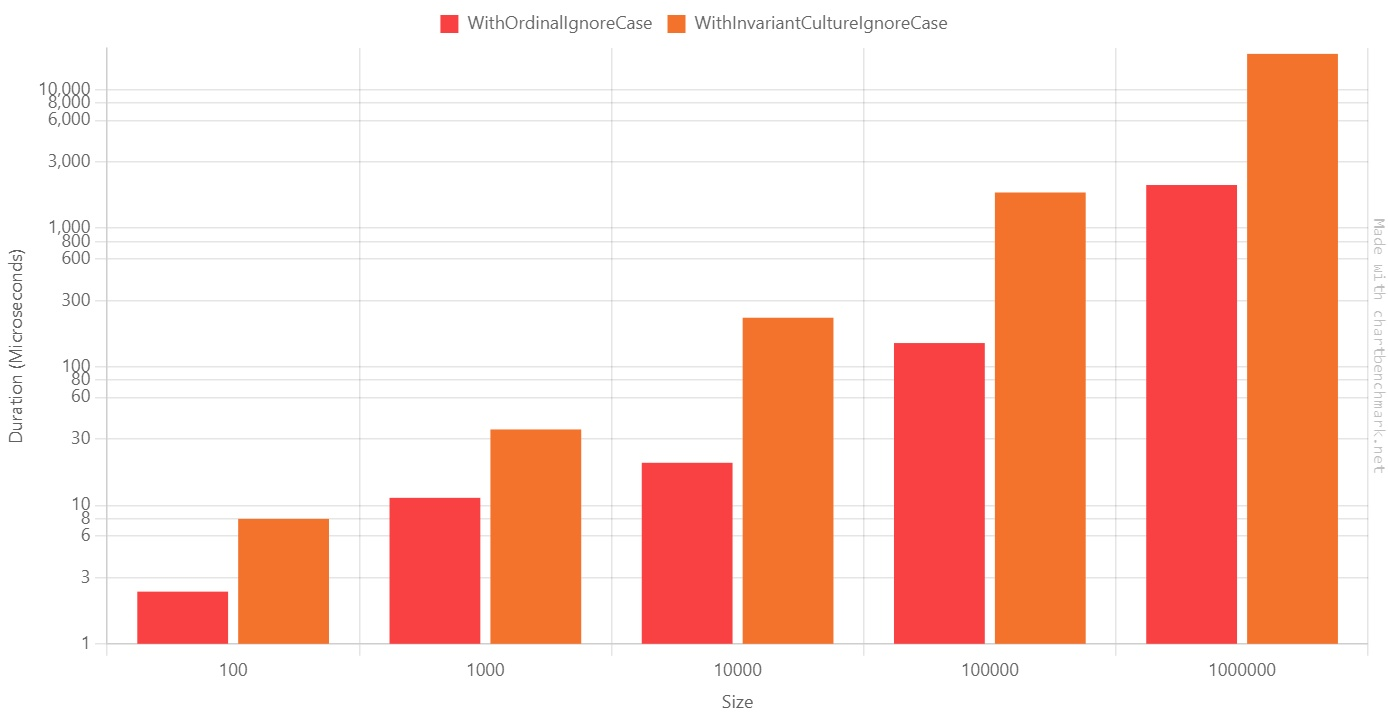
Tip #5: OrdinalIgnoreCase vs InvariantCultureIgnoreCase: logically (almost) equivalent, but with different performance
Comparing strings is trivial: the string.Compare method is all you need.
There are several modes to compare strings: you can specify the comparison rules by setting the comparisonType parameter, which accepts a StringComparison value.
As you can see, there’s a HUGE difference between Ordinal and Invariant.
When dealing with 100.000 items, StringComparison.InvariantCultureIgnoreCase is 12 times slower than StringComparison.OrdinalIgnoreCase!
Why? Also, why should we use one instead of the other?
Have a look at this code snippet:
var s1 = "Aa";
var s2 = "A" + newstring('\u0000', 3) + "a";
string.Equals(s1, s2, StringComparison.InvariantCultureIgnoreCase); //Truestring.Equals(s1, s2, StringComparison.OrdinalIgnoreCase); //False
As you can see, s1 and s2 represent equivalent, but not equal, strings. We can then deduce that OrdinalIgnoreCase checks for the exact values of the characters, while InvariantCultureIgnoreCase checks the string’s “meaning”.
So, in most cases, you might want to use OrdinalIgnoreCase (as always, it depends on your use case!)
Tip #6: Newtonsoft vs System.Text.Json: it’s a matter of memory allocation, not time
For the last benchmark, I created the exact same model used as an example in the official documentation.
This benchmark aims to see which JSON serialization library is faster: Newtonsoft or System.Text.Json?
As you might know, the .NET team has added lots of performance improvements to the JSON Serialization functionalities, and you can really see the difference!
Method
Size
Mean
Error
StdDev
Median
Ratio
RatioSD
Gen0
Gen1
Allocated
Alloc Ratio
WithJson
100
2.063 ms
0.1409 ms
0.3927 ms
1.924 ms
1.00
0.00
–
–
292.87 KB
1.00
WithNewtonsoft
100
4.452 ms
0.1185 ms
0.3243 ms
4.391 ms
2.21
0.39
–
–
882.71 KB
3.01
WithJson
10000
44.237 ms
0.8787 ms
1.3936 ms
43.873 ms
1.00
0.00
4000.0000
1000.0000
29374.98 KB
1.00
WithNewtonsoft
10000
78.661 ms
1.3542 ms
2.6090 ms
78.865 ms
1.77
0.08
14000.0000
1000.0000
88440.99 KB
3.01
WithJson
1000000
4,233.583 ms
82.5804 ms
113.0369 ms
4,202.359 ms
1.00
0.00
484000.0000
1000.0000
2965741.56 KB
1.00
WithNewtonsoft
1000000
5,260.680 ms
101.6941 ms
108.8116 ms
5,219.955 ms
1.24
0.04
1448000.0000
1000.0000
8872031.8 KB
2.99
As you can see, Newtonsoft is 2x slower than System.Text.Json, and it allocates 3x the memory compared with the other library.
So, well, if you don’t use library-specific functionalities, I suggest you replace Newtonsoft with System.Text.Json.
Wrapping up
In this article, we learned that even tiny changes can make a difference in the long run.
Let’s recap some:
Using StringBuilder is generally WAY faster than using string concatenation unless you need to concatenate 2 to 4 strings;
Sometimes, the difference is not about execution time but memory usage;
EndsWith and StartsWith perform better if you look for a char instead of a string. If you think of it, it totally makes sense!
More often than not, string.IsNullOrWhiteSpace performs better checks than string.IsNullOrEmpty; however, there is a huge difference in terms of performance, so you should pick the correct method depending on the usage;
ToUpper and ToLower look similar; however, ToLower is quite faster than ToUpper;
Ordinal and Invariant comparison return the same value for almost every input; but Ordinal is faster than Invariant;
Newtonsoft performs similarly to System.Text.Json, but it allocates way more memory.
My suggestion is always the same: take your time to explore the possibilities! Toy with your code, try to break it, benchmark it. You’ll find interesting takes!
I hope you enjoyed this article! Let’s keep in touch on Twitter or LinkedIn! 🤜🤛
There are many business lines in the world that are not easy to manage, and the trucking business is one of them. This industry is one of the booming industries in many countries.
Nowadays, many business owners are trying to take part in this industry. Over the past years, this business has shown constant growth, which has made it a popular business line. If you are planning to start a trucking business, then you have to understand the complex jargon of this field. Along with that, you need to get a DOT authority for operating a business in your State.
In this blog, you will find out how you can start and run your trucking business successfully.
Do your research
To hit the jackpot, the first thing you need to do is to crack the nuts. This means you will have to research the market and needs.
By doing in-depth research, you will be able to identify your business niche in the trucking industry. Are you interested in transporting goods or using a truck for mobile billboards? These are only two examples, but when you research it, you will definitely find more possibilities in it.
After that, it will be easy for you to develop a business plan.
Find your target market
Another one of the leading business strategies is finding and understanding the target audience. Once you understand for whom you will offer your services and what their needs are, it will become easy for you to offer the services and make more sales.
It will be a wise decision if you develop your business strategy according to the niche market. By following this approach, you can ensure that your operations are cohesive and on track. When you tailor your trucking services according to the needs of your clients, in results your business will be able to earn a reputation and revenue.
Finance your fleet
Businesses are all about heavy investment, no matter the size or scale of your startup. When it comes to the trucking business, you will be surprised to know the buying cost of trucks. When planning the finances for buying trucks, you will also have to prepare for the maintenance costs. You can find many financing options to start your business.
You can also start your own company with new vehicles or can consider investing in offers for used commercial vehicles and construction machinery.
Make it legal
It is crucial for business owners to meet all the legal requirements to operate their businesses in State. Without legal recognition or approval, the federal ministry can take charge of you, and you could end up losing your business.
Many people enter the trucking business without knowing that it is highly regulated. You will need to get a permit or authority to operate your business activities interstate. You will also need to file for a DOT MC Number in your State.
Ensure that your business complies with the applicable laws for maintaining legitimacy.
Invest on technology
Technology is the future, and especially for trucking business startups, you should realize its importance earlier. Technology is about to dominate services and different businesses. With technology, you will provide numerous benefits to your business.
When it comes to transporting business, you will have to track and manage the orders. For this, it is crucial for you to use mobile applications or websites to promote your business and make it visible. If you cannot afford oversized technological items in your business, you can still add basics like GPS systems, smart cameras, and more.
Learn your competition
When you research your market, you should also study your competitors. It will help you to understand the threats and weaknesses that already existing businesses are facing. This way, you will come up with innovative business strategies and fill the needs of the clients.
You can also offer the most competitive prices from other truckers and brokers with reasonable margins, so a good number of clients will attract your business.
Pro tip:
You should always connect directly with consigners so you will pass the benefits to your clients through a reduction in prices.
Final note:
There is no doubt in it that the trucking business has been booming over the years, and it has brought gold for owners. If you get the fundamentals right, being new in the market, you can also harvest the jackpot.