Ransomware is one of the most disruptive cyber threats, encrypting critical organizational data and demanding ransom payments for restoration. While early campaigns relied on mass phishing or opportunistic malware distribution, modern ransomware operations have evolved into highly sophisticated, targeted attacks. Today’s adversaries not only infect machines but also move laterally across networks, harvest credentials, neutralize defences, and maintain persistent control—all while remaining stealthy and evading detection.
Disclaimer: The Remote Access Tools discussed in this blog are legitimate software products designed to support IT administration and remote support. This article highlights how adversaries may misuse them in ransomware campaigns if they are misconfigured, poorly managed, or left unmonitored. It does not suggest that the tools themselves are inherently vulnerable or malicious.
A key enabler of these attacks is the exploitation of legitimate Remote Access Tools (RATs) such as AnyDesk, UltraViewer, AppAnywhere, RustDesk, CloneDesk, Splashtop, and TightVNC. Originally designed for IT administration and remote support, many of these tools offer free or freely available versions, which attackers often abuse because they are easy to deploy, widely trusted, and frequently whitelisted in enterprise environments. These tools provide:
Unattended access: Connect without user interaction
Organizations often whitelist Remote Access Tools and trust their digital signatures, which attackers exploit to bypass security controls and persist stealthily. Understanding how Remote Access Tools are abused is critical for building effective defences against modern ransomware threats.
The Ransomware Kill Chain: A Step-by-Step Breakdown
The ransomware kill-chain outlines each stage of an attack, from initial access to final impact. When attackers leverage legitimate Remote Access Tools, they gain stealth, persistence, and control, making detection and mitigation more challenging.
Stage 1: Initial Access – Credential Compromise
Attackers gain legitimate access using stolen or brute-forced credentials, bypassing defences while appearing as trusted users. Targeting administrator accounts provides maximum control and enables later stages like Remote Access Tool deployment and lateral movement.
Common Attack Pathways:
Brute-force attacks against RDP/SMB endpoints
Credential reuse from leaks or past breaches
Targeting administrator accounts for maximum privileges
Detection Indicators:
Windows Event IDs 4625 → 4624 (multiple failed logins immediately followed by success)
RDP logon type 10 at unusual hours
Logins from unexpected geolocations.
Stage 2: Remote Tool Abuse – Hijacking vs. Silent Installation
After gaining access, attackers focus on Remote Access Tool deployment for stealthy persistence. They can either hijack an existing Remote Access Tool to avoid detection or perform a silent installation using signed installers with minimal footprint. Silent installation often leverages known command-line flags, vendor documentation, or reverse-engineering to find deployment parameters.
Method 1: Hijacking Existing Remote Access Tools
Enumerate installed Remote Access Tools via WMI, registry, or PowerShell.
Add attacker credentials or modify access configurations.
Avoids creating new files or processes, reducing detection risk.
Method 2: Silent Installation of Remote Access Tools
Deploy lightweight, signed installers without user interaction.
Attackers leverage registry run keys (HKCU\Software\Microsoft\Windows\CurrentVersion\Run), hidden scheduled tasks, and configuration file modifications to maintain persistence. Privilege escalation is achieved using tools like PowerRun or TrustedInstaller, allowing Remote Access Tools to run with SYSTEM privileges and bypass user-level restrictions.
Mechanisms:
Registry Run Keys: HKCU\Software\Microsoft\Windows\CurrentVersion\Run
Scheduled Tasks: Hidden tasks to auto-restart Remote Access Tools
Configuration Files: Modify config.toml (RustDesk) for unattended access
Privilege Escalation: Launch Remote Access Tool as SYSTEM using PowerRun or TrustedInstaller
Using Remote Access Tools, attackers can interactively stop Antivirus services, manipulate group policies, and add Remote Access Tool directories to exclusion lists. Critical logs are cleared, and file shredding tools are used to remove forensic evidence, making post-incident investigation difficult.
Techniques:
Stop Antivirus services: sc stop <service> or net stop <service>
Policy manipulation: Add Remote Access Tool directories to exclusions.
Log clearing: Adversaries often use the following command lines as part of Anti-Forensics to clear event logs: wevtutil cl Security wevtutil cl System wevtutil cl Application
File shredding: Remove forensic artifacts
Stage 5: Payload Deployment & Execution
Attackers stop Antivirus services, modify security policies, disable recovery mechanisms, clear event logs, and shred sensitive files to evade detection and hinder forensic investigations. They may also tamper with backup solutions, disable shadow copies, and use Living-off-the-Land Binaries (LOLBins) like rundll32 or PowerShell to blend malicious actions with legitimate processes. These actions ensure minimal visibility for defenders and create a safe environment for ransomware execution.
Mechanism:
Ransomware is delivered through Remote Access Tool channels, often disguised as trusted updates or administrative actions, and executed within existing remote sessions to bypass user suspicion and security monitoring.
Stage 6: Lateral Expansion
Lateral movement is facilitated through credential reuse, Remote Access Tool propagation, or exploiting enterprise Remote Access Tool deployments.
Mechanisms:
Credential reuse across endpoints
Enterprise Remote Access Tool exploitation for mass deployment
Indicators:
Multiple endpoints reporting new Remote Access Tool connections
Unauthorized scheduled tasks or registry modifications across machines
Stage 7: Impact – Encryption & Lockout
Ransomware payload execution triggers data encryption, account lockouts, and Remote Access Tool credential changes to block administrative remediation. Campaigns such as LockBit, Black and Basta variants demonstrate this final stage in live attacks.
Outcome:
Encrypt files on target systems
Lock accounts or change Remote Access Tool credentials to prevent remediation
Real-World Campaign Examples
Below are commonly abused Remote Access Tools leveraged by adversaries in ransomware campaigns for persistence, deployment, and lateral movement.
Understanding the tactics, techniques, and procedures (TTPs) used by adversaries is crucial to defending against Remote Access Tool-driven ransomware campaigns. By mapping these activities to the MITRE ATT&CK framework, security teams can visualize how attackers gain access, deploy tools, maintain persistence, escalate privileges, and eventually deliver impactful payloads. The table below highlights the key stages of attack, the techniques leveraged, and the commonly abused remote access tools aligned to each step.
Stages
Technique
MITRE ATT&CK Sub-Technique ID
Observations
Initial Access
Brute Force
T1110.001
Targeting RDP/SMB endpoints to gain initial access
Tool Deployment
Ingress Tool Transfer
T1105
Remote access utilities transferred for execution
Execution
Remote Services
T1021.001
Remote sessions used to execute payloads
Persistence
Registry Run Keys
T1547.001
Registry keys created/modified for tool persistence
Privilege Escalation
Abuse Elevation Control Mechanism
T1548.002
Elevation of privileges observed to run tools with SYSTEM rights
Defense Evasion
Impair Defenses
T1562.001
Security services disabled, logs cleared
Lateral Movement
Remote Services
T1021.001
Remote services abused to move across endpoints
Impact
Data Encrypted for Impact
T1486
Tools leveraged to deploy ransomware and encrypt data
Emerging Trends & Future Threats
As ransomware operators evolve, new tactics are emerging that expand beyond traditional on-premise exploitation. These trends highlight how attackers are combining automation, cloud abuse, and RaaS ecosystems to maximize the scale and stealth of their operations.
AI-driven Remote Access Tool deployment: Automated decision-making for payloads
RaaS integration: Remote Access Tools embedded in ransomware-as-a-service offerings for enterprise campaigns
Multi-stage attacks: Initial Remote Access Tool compromise followed by secondary payloads (data exfiltration, cryptojacking, lateral ransomware)
How Quick Heal / Seqrite Protect Against These Activities.
Ransomware actors may try to weaponize trusted tools, but Quick Heal and Seqrite are built with multiple layers of defence to stop them in their tracks. By combining real-time monitoring, self-protection, and advanced behavioural detection, these solutions ensure that attackers can’t easily disable security or slip past unnoticed.
Virus Protection: Actively detects and neutralizes trojanized installers or hidden payloads before they can execute.
Antivirus Self Protection: Prevents attackers from forcefully terminating or uninstalling security services.
Behaviour-Based Detection: Monitors for abnormal activities linked to ransomware, such as mass file changes or suspicious process launches.
Ransomware Protection: Blocks unauthorized encryption attempts in real time, cutting off the attack before data is locked.
Application Control: Restricts the use of unauthorized remote tools, ensuring only trusted applications are allowed to run.
Security Best Practices & Recommendations
Defending against ransomware isn’t just about having the right tools — it’s also about using them wisely and building strong day-to-day habits. Here are some practical steps every organization can take to stay ahead of attackers:
Restrict Remote Access Tool Usage: Only keep the remote tools you really need and remove the rest. The fewer entry points, the safer your systems are.
Enforce Multi-Factor Authentication (MFA): Even if attackers steal a password, MFA makes it much harder for them to log in.
Limit Administrative Rights: Don’t hand out admin privileges unless absolutely necessary. Less privilege means less damage if an account is compromised.
Audit & Monitor Logs Continuously: Keep a close watch on your logs — unusual logins, silent installs, or strange setup commands can be early warning signs.
Regular Updates & Patching: Stay on top of updates for both your operating systems and security tools so attackers can’t exploit old flaws.
User Awareness Training: People are the first line of defence. Training staff to spot phishing emails or suspicious remote support activity can stop attacks before they even start.
Conclusion:
Legitimate IT tools can easily become hidden attack vectors when mismanaged, and Remote Access Tool abuse is now a critical enabler of next-generation ransomware. To counter this risk, enterprises need a layered approach that combines governance, monitoring, and rapid response.
Quick Heal and Seqrite play a central role in this defence strategy, providing strong Antivirus protection, behavioural detection, and Anti-Ransomware protection. When paired with strict governance and incident response, organizations can stay ahead of attackers.
Key measures include:
Remote Access Tool governance and whitelisting
Multi-layered Antivirus protections powered by Quick Heal / Seqrite
Behavioural detection and outbound filtering
Rapid incident response for containment and recovery
By adopting this multi-layered defence strategy, organizations can proactively detect, contain, and mitigate Remote Access Tool–based ransomware campaigns—turning trusted tools from potential threats into controlled, manageable assets.
Do you need the index of the current item in a foreach loop with C#? Here you’ll see two approaches.
Table of Contents
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
Sometimes, when looping over a collection of elements in C#, you need not only the items itself, but also its position in the collection.
How to get the index of the current element in a foreach loop?
The easiest way is to store and update the index in a separate variable
List<string> myFriends = new List<string> {
"Emma", "Rupert", "Daniel", "Maggie", "Alan"};
int index = 0;
foreach (var friend in myFriends)
{
Console.WriteLine($"Friend {index}: {friend}");
index++;
}
This works fine, nothing to add.
But, if you want something a little more elegant and compact, you can use the Select method from LINQ:
there is a tight bond between the current item in the loop and the index
I find it cleaner and easier to read
Or… You can just replace it with a simple for loop!
What about performance?
I’ve done a simple benchmark (see here), and it resulted that for lists with less than 1000 items, the first solution is faster, and for lists with 10000 items, using LINQ is way faster than using an external index.
Size (#items)
With simple index (ms)
With LINQ (ms)
100
96
128
1000
1225
1017
10000
5523
786
This happens with .NET 5.
Update 2021-06-09: the previous benchmark was wrong!!😐
The times listed in the previous table were misleading: I calculated those durations using a StopWatch and calling it in different methods.
But, when performing a more precise benchmark using Benchmark.NET, the results are totally different.
With .NET Core 3.1.14 I get the following results:
Method
array
Mean
Error
WithIndex
Int32[10000]
269,386.4 ns
6,168.76 ns
WithLinq
Int32[10000]
396,421.3 ns
7,778.64 ns
WithIndex
Int32[1000]
25,438.3 ns
504.03 ns
WithLinq
Int32[1000]
39,981.3 ns
1,578.48 ns
WithIndex
Int32[100]
2,440.8 ns
48.34 ns
WithLinq
Int32[100]
3,687.7 ns
73.60 ns
WithIndex
Int32[10]
185.6 ns
3.52 ns
WithLinq
Int32[10]
369.5 ns
9.51 ns
While with .NET 5 I get these results:
Method
array
Mean
Error
WithIndex
Int32[10000]
134,431.02 ns
2,181.244 ns
WithLinq
Int32[10000]
273,691.68 ns
5,334.833 ns
WithIndex
Int32[1000]
12,961.69 ns
233.351 ns
WithLinq
Int32[1000]
26,023.63 ns
495.341 ns
WithIndex
Int32[100]
1,088.25 ns
21.485 ns
WithLinq
Int32[100]
2,299.12 ns
21.901 ns
WithIndex
Int32[10]
48.01 ns
0.748 ns
WithLinq
Int32[10]
228.66 ns
4.531 ns
As you can see, actually using LINQ is slower than using a simple index. While in .NET Core 3 the results were quite similar, with .NET 5 there was a huge improvement both cases, but now using a simple index is two times faster than using LINQ.
SORRY FOR THAT MISLEADING INFO! Thank you, Ben, for pointing it out in the comments section! 🙏
Below you can see the code I used for this benchmark. I you want to get started with Benchmark.NET, look at the documentation or to my article Enum.HasFlag performance with BenchmarkDotNet
We’ve discovered that there are many ways to use indexes tightly bound with items. If you look at performance, go for the simplest ways (for loop or foreach with simple index). If you want a more concise code, go for LINQ.
Anything else to add?
👉 Let’s discuss it on Twitter or on the comment section below!
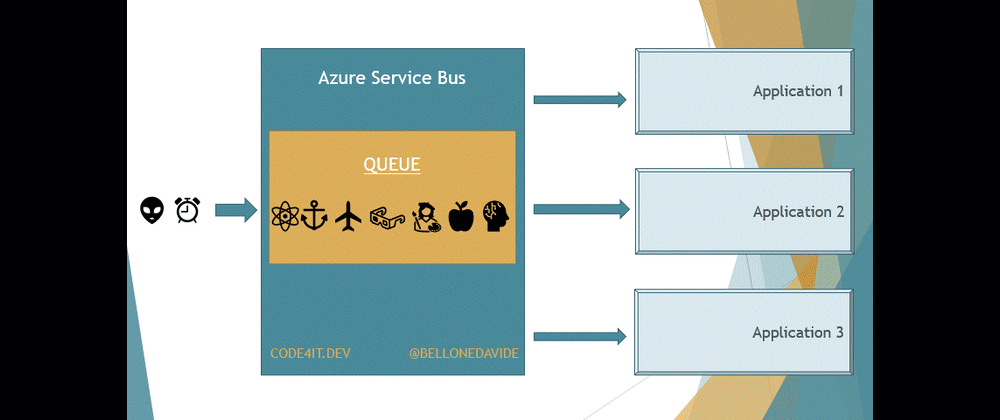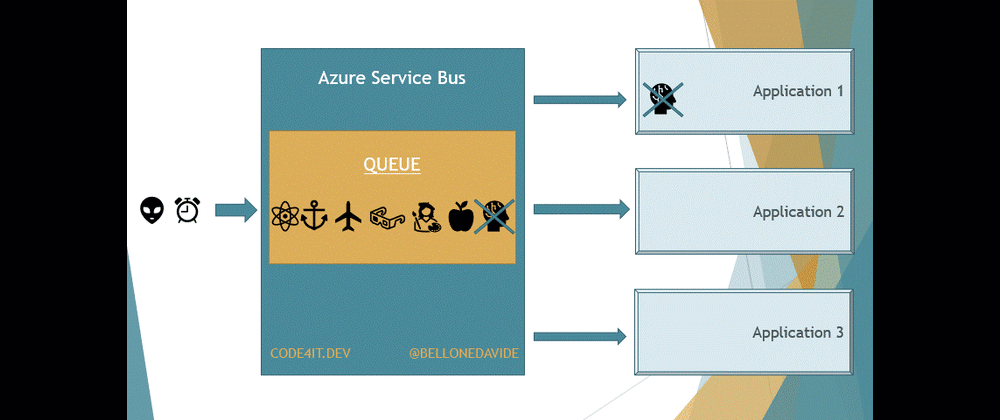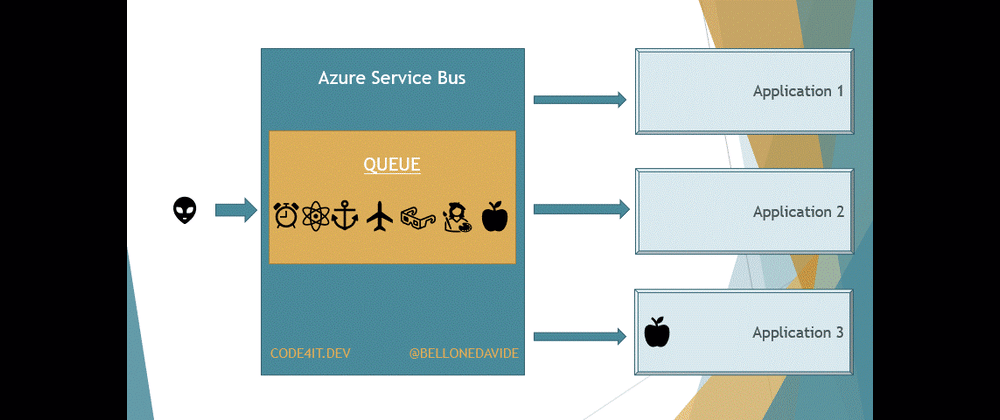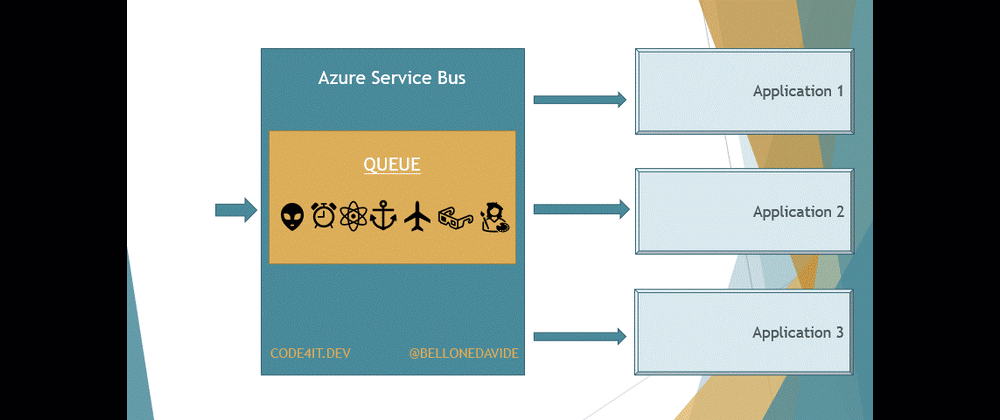
Queues or Topics? How are they similar and how they are different? We’ll see how to use those capabilities in Azure Service Bus with .NET and C#
Table of Contents
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
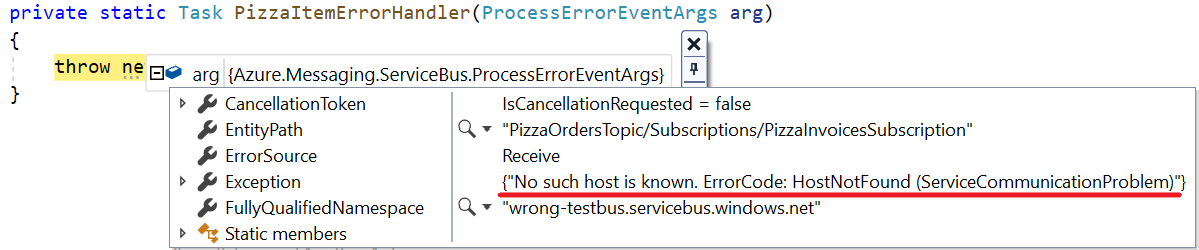
In the previous article, we’ve seen that with Azure Service Bus, the message broker provided by Microsoft, you can send messages in a queue in a way that the first application that receives it, also removes that message from the queue.
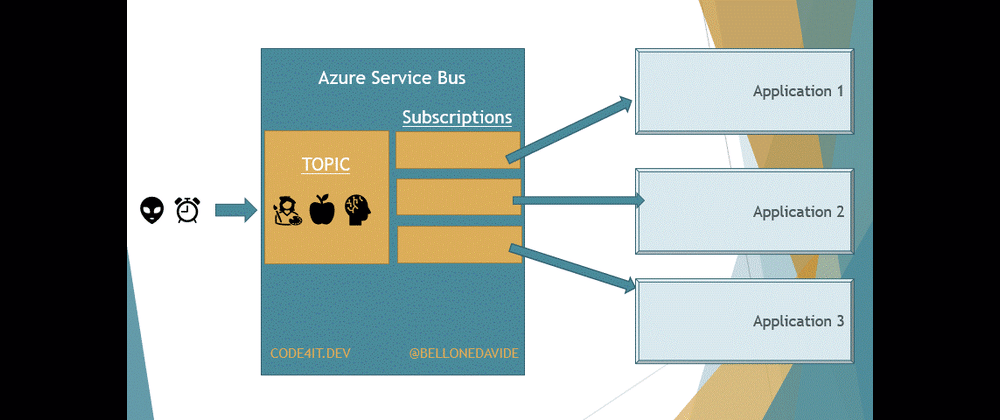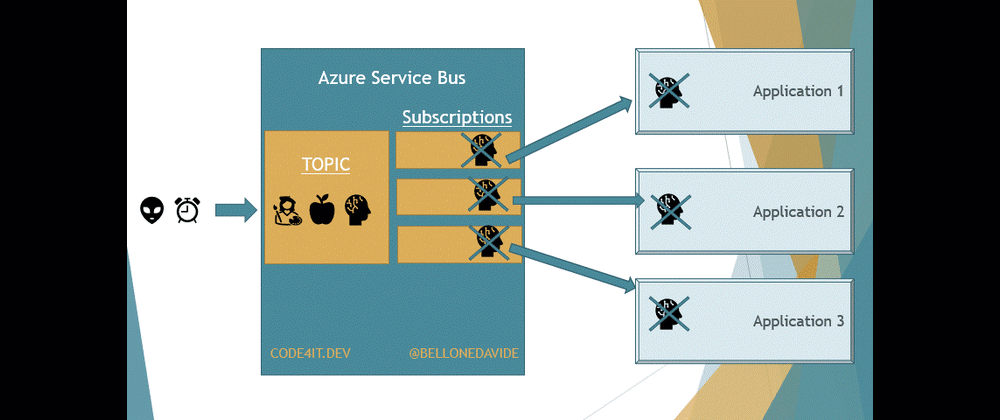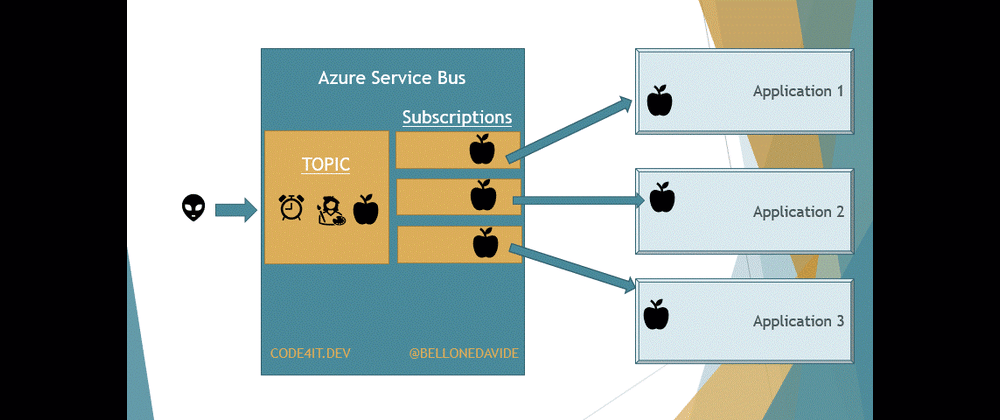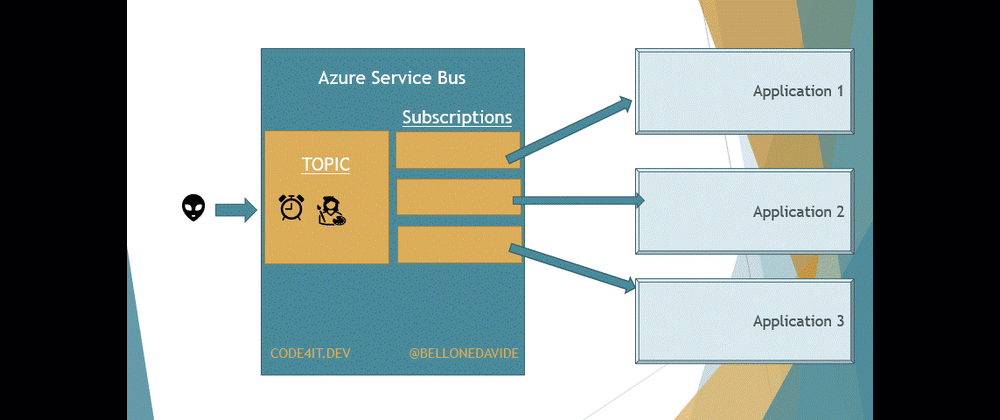
In this article, we’re gonna see another capability of Azure Service Bus: Topics. With topics, many different applications can read the same message from the Bus; the message will be removed from the Bus only when every application has finished processing that message.
This is the second article in this series about Azure Service Bus:
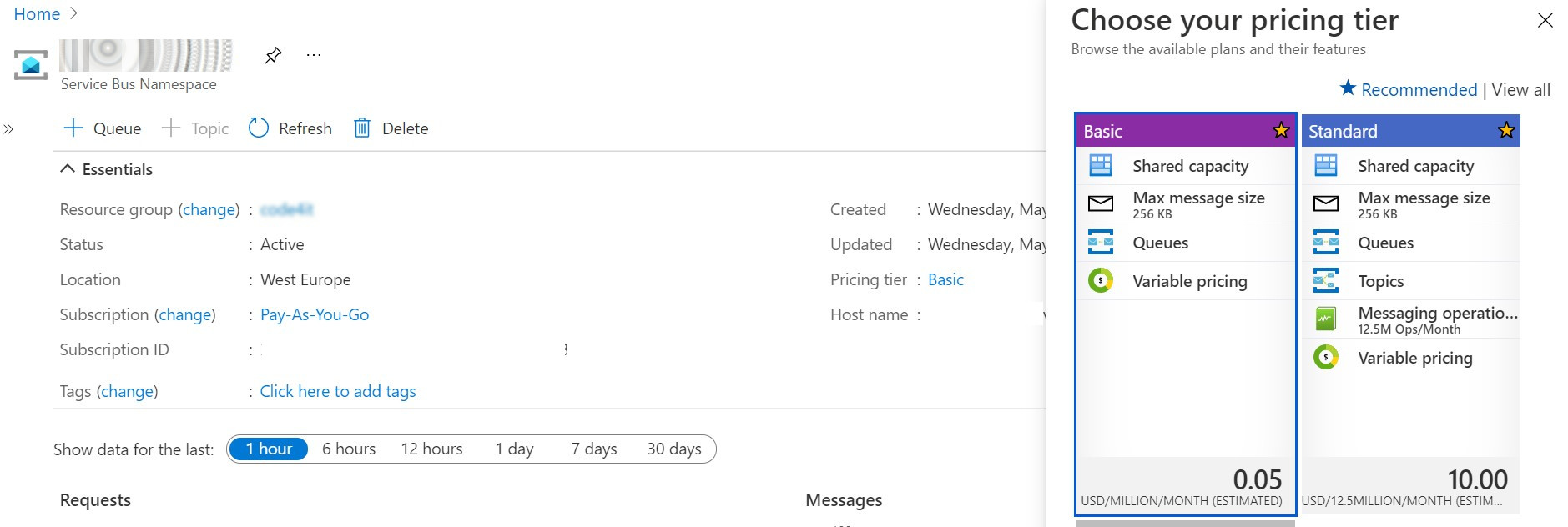
Basic: its price depends on how many messages you send. You only have Queues.
Standard: similar to the Basic tier, but allows you to have both Queues and Topics.
Premium: zone-redundant, with both Queues and Topics; of course, quite expensive.
To use Topics, we need to upgrade our subscription tier to Standard or Premium.
Open Portal Azure, head to the resource details of the Queue and click on the Pricing Tier section.
Here, select the Standard tier and save.
Queue vs Topic
Queues and Topics are similar: when an application sends a message somewhere, a receiver on the other side reads it and performs some operations on the received message.
But there is a key difference between Queues and Topics. With Queues, the first receiver that completes the reading of the message also removes it from the Queue so that the message cannot be processed by other readers.
With Topics, the message is removed only after every receiver has processed the message. Every Topic has one or more Subscribers, a connection between the Topic itself and the applications. All the applications subscribe to a specific Subscription, and receive messages only from it.
When the message is read from all the Subscribers, the message is removed from the Topic too.
A topic subscription resembles a virtual queue that receives copies of the messages that are sent to the topic. Consumers receive messages from a subscription identically to the way they receive messages from a queue.
This means that our applications do not access directly the Topic, as we would do if we were talking about Queues. Here we access the Subscriptions to get a copy of the message on the Topic. Once the same message has been removed from all the Subscriptions, the message is also removed from the Topic.
This is important to remember: when using Topics, the Topic itself is not enough, you also need Subscriptions.
Create Topics and Subscriptions on Azure
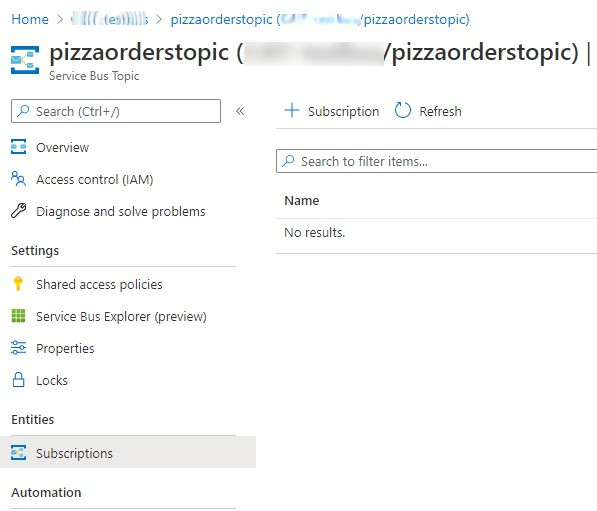
Once we have upgraded our pricing plan to Standard, we can see the Topic button available:
Click on that button, and start creating your Topic. It’s simple, just choose its name and some optional info.
Then, navigate to the newly created Topic page and, on the Entities panel on the right, click on Subscriptions. From here, you can manage the subscriptions related to the Topic.
Click on the add button, fill the fields and… voilá! You are ready to go!
Of course, you can see all the resources directly on the browser. But, as I’ve explained in the previous article, I prefer another tool, ServiceBusExplorer, that you can download from Chocolatey.
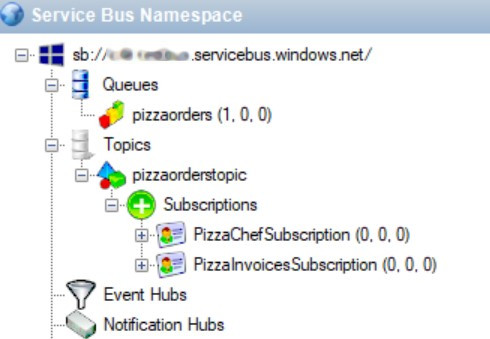
Open the tool, insert the connection string, and you’ll see something like this:
What does this structure tell us?
Here we have a Queue, pizzaorders, which is the one we used in the previous example. Then we have a Topic: pizzaorderstopic. Linked to the Topic we have two Subscriptions: PizzaChefSubscription and PizzaInvoicesSubsciption.
Our applications will send messages into the pizzaorderstopic Topic and read them from the two Subscriptions.
How to use Azure Service Bus Topics in .NET
For this article, we’re gonna rework the code we’ve seen in the previous article.
Now we are gonna handle the pizza orders not only for the pizza chef but also for keeping track of the invoices.
How to send a message in a Topic with CSharp
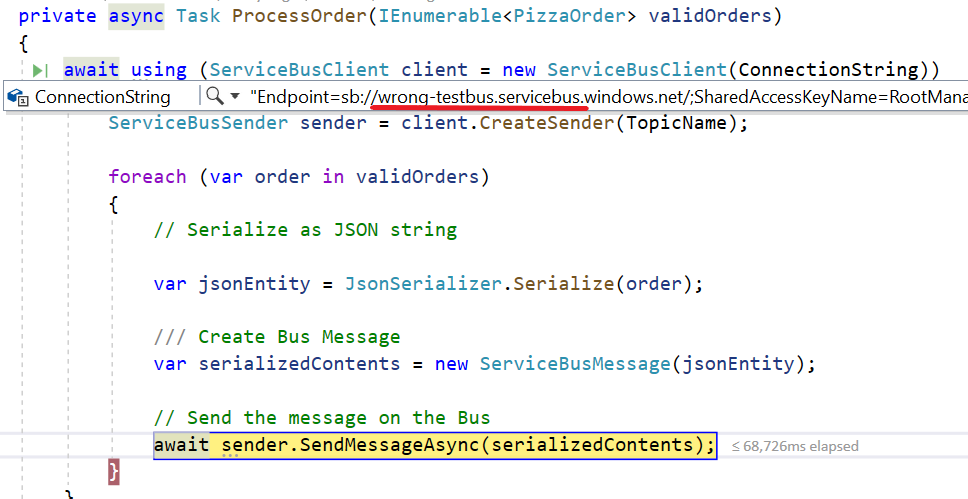
From the developer’s perspective, sending messages on a Queue or a Topic is actually the same, so we can reuse the same code I showed in the previous article.
We still need to instantiate a new Sender and send a message through it.
ServiceBusSender sender = client.CreateSender(TopicName);
// create a message as stringawait sender.SendMessageAsync(serializedContents);
Of course, we must use the Topic Name instead of the Queue name.
You can easily say that sending a message on a Topic is transparent to the client just by looking at the CreateSender signature:
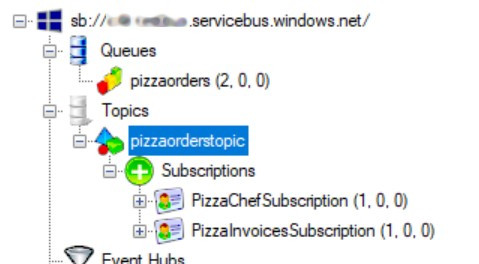
Now, if we run the application and order a new pizza, we will see that a new message is ready on the Topic, and it is waiting to be read from all the Subscriptions.
How to receive a message from a Topic with CSharp
Now that the same message is available for both PizzaChefSubscription and PizzaInvoicesSubscription, we need to write the code to connect to the subscriptions.
Again, it is similar to what we’ve seen for simple queues. We still need to instantiate a Receiver, but this time we have to specify the Topic name and the Subscription name:
ServiceBusClient serviceBusClient = new ServiceBusClient(ConnectionString);
_ordersProcessor = serviceBusClient.CreateProcessor(TopicName, SubscriptionName);
The rest of the code is the same.
As you see, we need only a few updates to move from a Queue to a Topic!
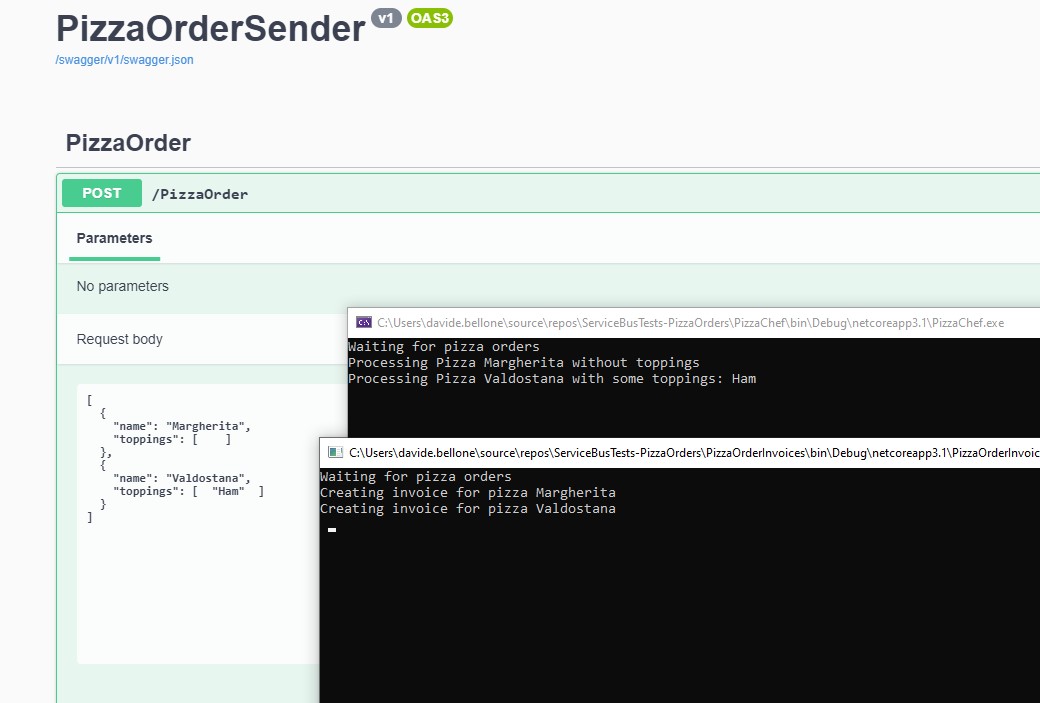
Final result
To see what happens, I’ve created a clone of the PizzaChef project, and I’ve named it PizzaOrderInvoices. Both projects reference the same Topic, but each of them is subscribed to its Subscription.
When receiving a message, the PizzaChef projects prints it in this way:
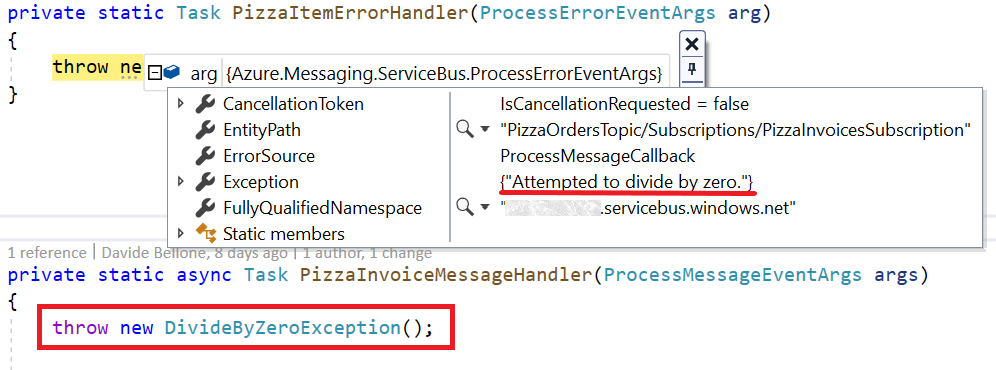
string body = args.Message.Body.ToString();
var processedPizza = JsonSerializer.Deserialize<ProcessedPizzaOrder>(body);
Console.WriteLine($"Processing {processedPizza}");
await args.CompleteMessageAsync(args.Message);
and the PizzaOrderInvoices performs the following operations:
string body = args.Message.Body.ToString();
var processedPizza = JsonSerializer.Deserialize<Pizza>(body);
Console.WriteLine($"Creating invoice for pizza {processedPizza.Name}");
await args.CompleteMessageAsync(args.Message);
Similar things, but with two totally unrelated clients.
So now, if we run all three applications and send a new request, we will see the same messages processed by both applications.
Wrapping up
In this article, we’ve seen what are the differences between a Queue and a Topic when talking about Azure Service Bus.
As we’ve learned, you can insert a new message on a Queue or on a Topic in the same way. The main difference, talking about the code, is that to read a message from a Topic you have to subscribe to a Subscription.
Now that we’ve learned how to manage both Queues and Topics, we need to learn how to manage errors: and that will be the topic of the next article.
Readymag is a design tool for creating websites on a blank canvas. Grids and templates remain useful, but Readymag also makes room for another approach, one where designers can experiment more freely with composition, storytelling, and visual rhythm. As the web evolves, the free layout model feels increasingly relevant beyond art or experimental work.
Between structure and freedom
Design history often swings between order and freedom. Some seek clarity and repetition, while others chase the chance to break rules for expression and surprise. Web design reflects this tension, shaped from the start by both technical limits and visual experimentation.
Printing technology once dictated strict, grid-based layouts, later formalized by the Swiss school of graphic design. Early web technologies echoed this logic, making grids the default structure for clarity and usability. Yet many have pushed against it. Avant-garde and postmodern designers experimented with chaotic compositions, and on the web, Flash-era sites turned pages into performances.
Today, grid and freedom approaches coexist. Tools like Readymag make it possible to borrow from both as needed, sometimes emphasizing structure, sometimes prioritizing expressiveness through typography, imagery, and motion.
The philosophy and psychology of freedom
If the grid in design symbolizes order, free layout is its breakaway gesture. Beyond altering page composition, it reflects deeper psychological and philosophical drives: the urge to experiment, assert individuality, and search for new meanings. Printing presses produce flawless, identical letters. A handwritten mark is always unique. Free layout works the same way: it allows designers to create something unique and memorable.
Working without the grid means inviting randomness, juxtaposing the incompatible, chasing unexpected solutions. Not all experiments yield finished products, but they often shape new languages. In this sense, free layout isn’t chaos for chaos’s sake—it’s a laboratory where future standards are born.
Freedom also changes the user’s experience. While grids reduce cognitive load, free composition is useful in creating emphasis and rhythm. Psychologists note that attention sharpens when expectations are disrupted. The most engaging designs often draw on both approaches, balancing clarity with moments of surprise.
How does it work in practice
While the philosophy of free layout may sound abstract, tools make it tangible. Each editor or builder imposes its own logic: some enforce rigid structures, others allow almost unlimited freedom. Comparing them shows how this philosophy plays out in practice.
Classic digital design tools like Photoshop were built as a blank canvas: the designer chooses whether or not to use a grid. Interface tools like Figma also offer both modes—you can stick to columns and auto-layout, or position elements freely and experiment with composition.
By contrast, pure web builders follow code logic. They work with containers, sections, and grids. Here the designer acts like an architect, assembling a structure that will display consistently across devices, support responsiveness, and guarantee predictability. Freedom is limited in favor of stability and usability.
Readymag stands apart. Its philosophy is closer to InDesign than to HTML: a blank canvas where elements can be placed however the designer wishes. The power of this approach is in prioritizing storytelling, impression, and experimentation.
Storytelling and creativity
Free layout gives the author a key tool: to direct attention the way a filmmaker frames a shot. Magazine longreads, promo pages, art projects—all of these rely on narrative. The reader needs to be guided through the story, tension built, emphasis placed. A strict grid often hinders this: it imposes uniform rhythm, equalizes blocks, and drains momentum. Free layout, by contrast, enables visual drama—a headline slicing into a photo, text running diagonally, an illustration spilling past the frame. Reading turns into an experience.
The best websites of recent years show this in practice. They use deliberately broken grids: elements that float, shift, and create the sense of a living space. The unconventional arrangement itself becomes part of the story. Users don’t just read or look; they walk through the composition. Chaotic typography or abrupt animation goes beyond simple illustration and becomes a metaphor.
Let’s explore a few examples of how this works in practice (all the websites below were made by Readymag users).
This multimedia longread on the Nagorno-Karabakh conflict traces its history and recent escalation through text and imagery. The design relies on bold typography, layered photographs, and shifting compositions that alternate between grid-like order and free placement. Scrolling becomes a narrative device: sections unfold with rhythm and contrast, guiding the reader while leaving space for visual tension and moments of surprise. The result is a reading experience that balances structure with expressiveness, reflecting the gravity of the subject through form as well as content.
On this website a collection of P.Y.E. sunglasses is presented through an immersive layout. Scrolling triggers rotations, shifts, and lens-like distortions, turning the screen into an expressive, almost performative space. Here, free composition sets the mood and builds a narrative around the product. Yet when it comes to the catalog itself, the design switches back to a clear grid, allowing for easy comparison of models and prices.
Everything.can.be.scanned collects ordinary objects—tickets, pill packs, toys, scraps—and presents them as digital scans. The interface abandons order: items float in cluttered compositions, and the user is invited to drag them around, building their own arrangements. Texts and playful interactions, like catching disappearing shadows, add layers of exploration. Here, free layout is not just an aesthetic choice but the core mechanic, turning randomness into a way of seeing.
Hayal & Hakikat recounts the story of Ottoman-era convicts through archival portraits that appear in sequence as the user scrolls. The repetition of images creates a grid-like rhythm, while interruptions like shifts in placement and sudden pauses break the order and add dramatic tension. The balance of structure and disruption mirrors the subject itself, turning the act of looking into part of the narrative.
The analogy with film and theater is clear. Editing isn’t built from uniform shots: directors speed or slow the rhythm, insert sharp cuts, break continuity for dramatic effect. Theater works the same way—through pauses, sudden light changes, an actor stepping into the audience. On the web, free layout plays that role. It can disrupt the scrolling rhythm, halt attention, force the user to reset expectations. It is a language of emotion rather than information. More than a compositional device, it becomes a narrative tool—shaping story dynamics, heightening drama, setting rhythm. Where the goal is to engage, surprise, and immerse, it often proves stronger than the traditional grid.
The future
Today, freeform layout on the web is still often seen as a niche tool used in art projects and experimental media. But as technology evolves, it’s becoming clear that its philosophy can move beyond experimentation and grow into one of the fundamental languages of the future internet.
A similar shift once happened in print. The transition from letterpress to phototypesetting and then to modern printing technologies expanded what was possible on the page and gave designers more freedom with layouts. The web is going through the same process: early constraints shaped a grid-based logic, but new technologies and tools like Readymag make it much simpler to experiment with custom arrangements when the project calls for it.
User expectations are also changing. A generation raised on games, TikTok, and memes is attuned not to linear order but to flow, interplay, unpredictability. For them, strict grids may feel corporate, even dull. This suggests that in the future, grid-based and freeform layouts will continue to coexist, each used where it works best, and often together in the same design.
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
The Principle of least surprise, also called Principle of least astonishment is a quite simple principle about Software design with some interesting aspects.
Simplifying it a log, this principle says that:
A function or class should do the most obvious thing you can expect from its name
What is the problem with this method? Well, simply, the Client may expect to receive the strings concatenated without other modifications; but internally, the function calls the ToLowerInvariant() method on the returned string, thus modifying the expected behavior.
So, when calling
var first ="Abra";
var second = "Kadabra";
var concatenated = Concatenate(first, second);
The concatenated variable will be abrakadabra instead of AbraKadabra.
Clearly, the client does not expect this method to replace an existing item. Again, the solution is to give it a better name: InsertOrUpdate, or Upsert.
Lastly, the function should use the Design Pattern suggested by its name.
publicclassRepositoryFactory{
privatestatic Repository instance = null;
publicstatic Repository Instance
{
get {
if (instance == null) {
instance = new Repository();
}
return instance;
}
}
}
This article kicks off our series “Creating Emotionally Meaningful Experiences with AI, Three.js, and Blender.” In it, Andrew invites us into his world and shares a deeply personal journey into creativity, emotion, and the joy of making. It may just shift how we see our own creative potential and the meaning behind what we make.
Introduction
Before I start, I want to give credits to Miffy by Dick Bruna, Denis Wipart, Moon, Southern Shotty, Xianyao Wei, Ning Huang, and Evelyn Hsiao. The characters belong to the Miffy Universe by Dick Bruna. The 3D characters you are seeing are a recreation of his art as a fan piece of his artwork. Denis, Moon, and Southern Shotty were the main inspirations for the scenes. I also want to shoutout to Ning Huang, Xianyao Wei, and Evelyn Hsiao as they helped with scene idea generation concepts and inspiration. For the full list of credits, and the Blender and Figma Files, see the GitHub.
My opinions and writing are entirely my own and are not and should not be a reflection of the credited individuals in this article and should most definitely not be taken as whole/universal truths. We each have our own systems of beliefs, and this article and future articles are reflections of my beliefs. It doesn’t mean I’m right or wrong, that determination is up to you.
This article is part of our series Creating Emotionally Meaningful Experiences with AI, Three.js, and Blender:
Part 1: Developing Creativity & Emotional Design Skills for Beginners Learn how to overcome creative block, copy-and-tweak with confidence, and design projects that truly resonate.
Part 2: Overcoming the AI Emotional Void & Building Creative Safety Explore how to overcome the AI emotional void & the importance of psychological safety for creative work.
Part 3: Finding Meaning: Emotional Regulation & Creative Intuition Developing emotional regulation and pattern matching skills and how to give meaning to your work for beginners.
Who this series is for
If you talk to the talented and famous people today, a lot of them will admit when they first started what they are doing now they thought they were “too dumb” to understand it. If you read the designer/developer spotlights here on Codrops, you’ll see a lot of very famous and talented people claim the same thing, that when they first started, they felt like a fraud or incapable of doing it. And yet, now they are known for what they’re doing, amazing at it, pushing the industry forward, and inspiring others. Here’s Mr. Doob, the legendary creator of Three.js, claiming he was convinced he wasn’t smart enough at first as well as other famous artists (including Danish Mir and crzyzhaa). They don’t say that because they’re lying and want to seem humble. They say it because it’s true. Getting older is realizing how broken people are even if they’re famous and talented and how we fake so many aspects of ourselves as humans. The difference between those you admire and yourself is likely just consistency, time, luck, and emotional management skills which are things I want to discuss in this article.
A lot of people are self-aware of their problems, but not self-aware enough on how to get oneself to fix those problems. That’s why we have therapists and life-coaches: to help provide guidance on how to actually change oneself. The great news is there are ways to develop that without a therapist and life-coach more effectively. You already change and grow yourself naturally over the years, but instead of letting it be passive, you can make it way more active. Of course you’ll never be perfect, but perfection isn’t the goal, growth is.
This series isn’t for the talented people out there, it’s for the people that don’t believe they are talented when they actually are. It’s for those who suffer from psychological blockers like extreme perfectionism that can lead to boredom, unfulfilled dreams, or chronic self-doubt. Talent is less about having natural abilities and more about consistency and having systems in place that make you consistent. That takes emotional work, and hopefully emotional work I can make understandable.
This series is also for those who want to make things emotionally meaningful. While what makes something “meaningful” is highly subjective, I hope to introduce broader patterns and systems that can help develop your own unique natural intuition and insight capabilities. That way, you can emotionally connect with and help others easier. If you’re on the business side, well, with products and services today being so similar, the main differentiator/competitive advantage is no longer the capabilities of a product/service, but how you make people feel. This is especially true now with AI, which has accelerated the need for emotionally meaningful experiences. The societal trends we see today highlight this growing emotional void, e.g. the Gen Z dating crisis, the rise of public vulnerability like “20 things I wish I knew in my 20s” etc. In other words, younger generations want psychological saftey that traditional structures and value systems struggle to support. Learning empathy for marketing purposes sounds insidious, but this is a highly nuanced topic that needs a separate article or, quite honestly, a book. I will cover this portion more in Part 2 and Part 3 and not very much in this article.
For the record, I still doubt myself a lot. There’s a lot of days where I pretend to know what I’m doing, but secretly learn stuff while I’m doing the work. And that’s normal, it’s called imposter syndrome and it’ll probably never go away, but at the very least you shouldn’t feel like an imposter unless you lack integrity. Like at some point though, you are self-aware enough to realize (mostly) what your limitations are and what they aren’t and adjust accordingly. That way you never fake too much confidence and overpromise while underdelivering. If you asked me some React best practices or optimizations I probably couldn’t answer many of them. However, give me a day and I can probably get back to you an answer and how that would change my future and/or existing projects. And honestly that’s what you do on the job all the time.
In other words, it’s not about who you are or what you know at the current moment, it’s about having the systems in place (whether conscious or not) that allow you to feel confident in yourself to tackle a problem with certainty. When you tell someone you can help them with their project, you’re not saying you know exactly how in the moment, but what you are saying is you know you will be capable of figuring it out and can do it within the constraints (e.g., budget/deadline) agreed upon by both parties. The issue here is that many of us lack self-awareness of what our capabilities really are. I hope this series helps in growing that self-awareness.
I will note, though, as you go through this series you may feel highly uncomfortable or even guilty and that’s totally normal. I still feel guilty and uncomfortable every day discovering unflattering truths about myself or when my actions violate my own words. Of course, I hope you feel inspired, but I’m not asking you to change or grow, just keep doing what you’re doing. If you hate yourself before reading this article/series, you won’t magically stop hating yourself after reading this article despite that being my intention. Sometimes the pain of staying the same has to feel worse than the pain of changing before your brain decides to make a decision. That’s nothing to be ashamed about, I went through that. I didn’t choose growth willingly, I was forced into growing. However, it’s best not to wait for pain or use that as an excuse. My recent growth is definitely a blend of choice and being forced, but not entirely forced anymore.
Emotional processing takes time, your logical understanding comes first which makes it seem like you “should” be able to change, but that’s not how change works. Just let it sit, and time will show you what you really value deep down. Maybe it’s now, maybe it’s later, or maybe it’s never. It doesn’t matter. No matter what happens, don’t judge yourself, just seek to understand yourself better.
1. Intro to Emotional Design and Emotional Design Patterns
1.1 What is Creativity and Overcoming Creative Block
To better understand emotional design (which requres one to be creative), let’s take a look at what creativity is.
I often hear people say they aren’t creative or they’re only good at copying things and have difficulties translating their thoughts into things other people can see or use. This is an extremely common feeling even among super talented creatives. There’s a term for it: creative block, which is identified by having difficulties starting/completing projects, inability to generate ideas etc. There’s a lot of causes for it, like if your external environment is dry and dull, or maybe you have extreme perfectionism from bad parenting etc. There are different solutions for each of these problems, but since there are so many causes of creative block, I want to try and provide a more broad solution by discussing what creativity actually is.
Simply put, creativity is the process of copying others and tweaking things. In other words, we all stand on the shoulders of giants. Think of any viral website or project and it’s likely a combination of things you’ve probably seen before, just in a slightly different way. We tend to call it “inspiration,” but behind inspiration is copying. “Copying” has this negative connotation associated with it, when in reality we do that all around us every single day. You see someone’s clothing you admire? You start wearing that brand, copying them too, but slightly adjust the style. Then someone likes your style and copies you and modifiers it slightly and the pattern goes on and on until the style becomes so different you can’t tell.
Copying and tweaking exists everywhere. Slack, Discord, and Microsoft Teams are all similar too. Even life’s creativity of us as humans is about copying our human DNA and tweaking it to create each one of us as unique individuals with distinct characteristics. The list never ends. Everything is a copy of something with tweaks. When you see everything in the world as copies of each other, you learn way faster and you can better identify the differences between those copies and how to create differences between those copies. In a sense, copying is just consistency, e.g., you copy similar actions and routines you do from one day to another. But you don’t want to stay consistent if it’s making you miserable (i.e. consistently harmful actions vs consistently non-harmful actions). That’s where tweaking AKA growth comes in.
I highly recommend watching this video on creativity. Even though I developed my thoughts independently prior to watching this video, someone else already said very similar things to what I’m saying. I’m not even being novel when I thought I was. My novelty is not in my idea, but the way I say/execute that same idea, that’s my “tweaking” part. I essentially “copied” them, even when I didn’t know they existed until after I wrote this article and came back to add this paragraph. I don’t agree with some of their framing, but the underlying idea/concept is the same as what I present in this section. The book Steal Like An Artist also shares similar views as I do, but it is framed differently as well.
In other words, creativity is just about looking at what others are doing and see how you can do it a bit differently. This distinguishment that different domains are inherently “creative” or “not-creative” is outdated. The reason we have this distinguishment is because we like to simplify things, we need to communicate, and economic factors. From a societal perspective, being a lawyer isn’t considered creative, but it is incredibly creative in the sense you have to know when to present evidence, when to hold back, and how to say things to emotionally appeal to a jury etc. That’s all creativity too. Perhaps it’s not “artistic” creativity, but it’s definitely emotional and linguistic creativity. And the cool thing is that you can use these lawyer timing tactics you know about in video game design patterns too!
For the past thousand years, we work to simplify things as humans. That’s why we have biases, stereotypes, and why we like to be lazy. Our natural default as humans is to simplify things (less cognitive load = less resource consumption for our bodies = better survival chances) and that’s why we ended up with “domains” and fields of studies. Today we’re realizing that many fields are more interconnected than we thought. Modern breakthroughs happen when different domains are cross pollinated. That’s how “the Godfather of AI” created the idea that LLMs are based off of, he applied the human brain workings to technology and stated to “be a contrarian” in an interview because people thought what he was doing was dumb. But he wasn’t just a contrarian, he was also a conformist. The contrarian in him was the “tweaking part” but he still built his knowledge using the math and science off other researchers, the “copying” part.
Incredible breakthroughs or paradigm shifts are just people who have spent a significant amount of time tweaking. The term “tweaking” isn’t meant to be reductive/dismissve as you can have very sophisticated and non-obvious tweaking patterns, but the idea is that even huge changes start from copying. Copying and tweaking isn’t meant to be easy or some mechanical process, it’s just an easy way of thinking about creativity. I’m not alone on this, Steve Jobs’s email to himself expresses this similar sentiment as well as many other people we typically see as genius or industry leaders. It doesn’t mean just because you realize this you’re a “good” humble person, but what it does mean is that you are self-aware enough to realize that you are the sum of the world and people around you (the good and the bad). The more you uncover the sources that make you who you are, the more you learn about yourself (AKA increasing your self-awareness). Whether you’re cynical and dislike most people or not, in some odd way that does bring some amount of peace and optimism when you accept that you are the sum of other people.
Tweaking is just like exercise. We know we should exercise, and some do it consistently, some try then give up, and others do it on and off. And we all have different reasons we want to exercise, some do it to attract a romantic partner while others do it to lose weight, feel better, or manage health issues or a combination of multiple reasons. It’s the same reason why we’re creative and push through that “ugly phase” of work, some do it because they’re driven by money, others do it because they want to use their creativity to connect with others etc.
Copying is the foundation of creativity, it’s not something to feel bad about. Whether you believe it or not, copying things means you’re on the right track to becoming more “creative” in the way that people typically interpret that word. If you always copy and never tweak, then it’s like you’re someone who always talks about wanting exercise but never doing it. Just like how you can’t learn the piano by only watching someone play piano, you have to actually practice with a piano. Likewise, with creativity, you actually have to practice being creative by tweaking.
Literally the only thing you have to do is credit others. No one thinks you’re less creative when you credit your inspirations AKA the people/things you copied and tweaked from. If they do, they’re the kind of people who will weaponize transparency and honestly anything against you, and those people always exist. It’s really easy to feel that people will judge you, but that’s just a defensive mechanism when you aren’t confident in yourself and don’t love yourself enough (of course, that’s not the only reason people hide credits, but this is a very common reason). It took me years to overcome this as I used to hide my inspirations to make people think I’m more creative than I am. However, as I developed more self-confidence, I feel no need to hide the people I took inspiration from. If you still hide credits like I used to, don’t feel embarrassed about it. Self-love is a journey in itself and having low self-esteem may not even have been your fault (like if you had abusive parents or were bullied).
So how do you overcome creative block? Simply put, you find fun in the process. Treat your failures like exercises and explorations of curiosity rather than reflections on your own capabilities and self-worth. Instead of thinking, “Wow, I spent 3 hours on that, what a waste of time, I must not be good enough” think, “Wow I’m really proud of myself I spent 3 hours trying something new and failing. I discovered how not to do something which will help me later because I know I have to fail 1000 times before I succeed.” Don’t feed your self-doubt. Treat learning to be creative like any other skill, whether that be learning how to code, piano, or some sport etc. That’s pretty generic advice you’ve probably heard before, but hopefully this section provides the context on where that advice comes from.
There’s also this argument that some are born more creative than others. Sure, but it doesn’t mean you can’t work on it if you want to. And quite honestly we’re all born differently haha, some people are born with taller genetics while others shorter genetics etc. As someone who used to suck at art, I can safely say if you have the right methods, you can develop creative/artistic abilities even if it’s less explicit than other fields.
It is important to note that just because you spend a lot of time tweaking things doesn’t mean you’ll get better outcomes. You can be “more creative” but create things that no one really likes. Like a child who draws a crazy creature, it’s very original, but not many enjoy it beyond the people around them (although even that too can be resonant). Just like exercise, you can do a lot of exercise, but if you do it wrong, you won’t get optimal health benefits/outcomes. However, this is not the point of this section. This section is not to provide a guide on how to practice creatively effectively, rather, it’s about how to overcome creative block. The next sections addresses how to create “well-recieved” projects and practice creativity more “effectively.”
1.2 A note on well-received emotionally resonant projects
Take a look at the following room portfolios in the screenshot below. I included one from the legendary Bruno Simon, Henry Heffernan a very talented developer, and one I made myself (yes, including myself is self-aggrandizing in a way, but my main intention is to show I practice what I preach). They all performed well in terms of publicity in the creative space (some more than others obviously, but that’s not the point). The question is then, why did these stand out across many other room portfolios? I mean at the end of the day look at them, they’re just rooms? Where’s the originality? Snorefest central, thank you next (I’m joking, I love these websites haha).
From left to right, Bruno Simon, Henry Heffernan, and Soo Ah’s room portfolios
Take a look at another set of websites that were emotionally resonant. Where’s the originality here either? They’re all looping worlds with some sort of person on a two-wheeled vehicle.
If you look at all six of these websites and break them down to their basics, it does seem like they all just copied each other. That must mean all I have to do is make my own room portfolio or looping world with a two-wheeled vehicle and people will like it!
Well, no, that’s not how it works. There’s a lot of factors that go into each of these that make them stand out even though, at a base level, you can view them as “unoriginal.” You can obviously tell all of them spend a lot of time tweaking, but they tweaked appropriately to impact the third factor, creating emotional resonance. It’s like music, most modern well-performing songs are based on very popular chord progressions (basically sets of notes in specific orders that people have determined sound pretty good). Just because you select a common chord progression a lot of famous songs use doesn’t mean you’ll make something that takes off in the music industry. Similarly, if you’re writing a book you can use the same “hero’s journey” plotline many famous books use, but have your book not perform well.
You might argue that other factors like luck, timing, and peoples’ reputation/status greatly contributed to their “success” and you’d be 100% right, but those are factors that are largely out of your control or are simply by-products of doing the right tweaking with the right emotional resonance in the first place; so let’s focus on the parts you can control more directly.
Emotional resonance consists of many components so lets break down where the emotional resonance comes from each project. At the end of the day, it’s rooted in human psychology, but instead of getting into the academic terms, let’s focus on the high level concepts. I can’t cover every component, but I’ll try and cover the easier ones to understand.
Bruno Simon’s Room
He’s famous and is a trendsetter. People naturally look up to and admire talented people and give more weight to their creations.
He created a room of high semi-realistic fidelity with cool functionalities. This appeals to developers and inspires them to pick up 3D art and 3D artists to pick up code. Not many people knew you could do something to this level of fidelity in a browser before. The novelty shock created resonance.
He made something personal to him, his own room. It feels like an intimate vulnerable look into his own life and what he values. There’s a ton of objects in there that represent who he is, such as the dog bed suggests he is a dog owner and has a caring side for animals and the streamer setup suggests he’s modern and makes videos. This creates a connection with him as a person and makes a person want to create their own personal sharing through a room portfolio.
Henry Heffernan’s Room
Like Bruno’s, this is super personal. It clearly shows he has a passion for the old-time vibe computers and the nostalgic games on the computer definitely emotionally impacted a lot of people in that way.
It’s very interactive and real and the subtle details like screen flickering and fingerprints shows attention to detail. When we see a screen flicker in real life or fingerprints on our screen we get upset and frustrated, but when it’s done purposefully in his portfolio, it becomes funny, thoughtful, and perhaps a little endearing. Shared frustration through a new medium creates emotional resonance. Here, the details also show that he’d carry that over into other aspects of his creations and technical skill which is also inherently attractive.
Soo Ah’s Room
Cute things basically. Not much else to say here. There are also popular references to League of Legends, BTS, motivational quotes, and Kirby appealing to a wide demographic of gamers, KPOP fans and those into self-help motivational quotes.
The colors are also lavender and pink which are associated with soothing creams/smells/moods, and the rounded corners of the 3D models contribute to the softness. There’s also a dominant wood-vibe which gives it that homey “one-with-nature” vibe.
Joshua’s World
Simple and easy to understand. People immediately know stories about bikers who travel long distances, and he used that concept as a way to share his own journey. All models have a consistent color palette and subtle animations for detail.
The low-poly style is inherently cute.
Sébastien Lempens‘ Portfolio
Uses the Eiffel tower, a reference to Paris, a very romantic city. The idea of exploring a city like Paris inherently touches people’s emotions.
The time takes place during sunset/sunrise, another really emotionally moving time for a lot of people. There’s even a term for this, the “golden hour.”
The wind turbines signify space, and clean energy (or cleanliness in general). We all love clean cities that we can explore and clean signifies safety.
The Ferris wheel resonates playfulness.
Molazone
While this isn’t as widely known (at least to my knowledge), it did win FWA of the month, so it did quite well among judges, but perhaps not so well-known known outside of the creative circle. A large part of it is probably because it was created by a professional studio and team, and that inherently puts it at a disadvantage in terms of emotional resonance. If it was made by a single person or a small team of individuals together rather than having an official studio, it definitely would have performed better on social media. However, I think it’s one of those sites that someone will repost and then get a lot of attention.
In any regard, this resonated with the judges not only for its design consistency and technical complexity but also, like the others, had a huge adventure component to it, like the colosseum, water bridge, and dark forest etc. which are all very common tropes associated with adventure, danger, and mystery all intended to evoke emotional responses.
There is also something they all share in common, and that it’s a 3D website. Since most websites are 2D, seeing 3D in a website inherently has a “wow” factor to it. To a more technical demographic, like gamers, they might not be as impressed, but once they learn it’s a website it typically has a larger impact than if you told them it was a standalone downloadable game. Of course, to people that work in this field, they’ve probably become desensitized to the “wow” factor.
Now you might be reading my analysis and think it applies to your website too, e.g., “I’ve got cute things too like low-poly models, why am I not getting attention?” Well, the difference there is probably the fact that you don’t know how to convey the emotions effectively. It’s a pretty common pattern known as the Dunning Kruger effect. You don’t know what you don’t know so you think yours is as good as theirs. This was me for a long time, and still today in the areas I’m not good at, so I always specifically look for that gap in my knowledge. The answer to find that gap is to that question is to observe more work and try and identify more patterns (more details in Section 1.3).
You might also think this is a post-hoc analysis and I’m making up things. That it’s easy to look at well-received projects in retrospect. That may be partially true, but this is also how we analyze things after finishing completed projects to see what we should continue doing or not. It also informs future design choices. We do this all the time which why many creatives are so consistent, we do a post-hoc analysis to predict future outcomes for future works. In the next section, I do an analysis before anyone has seen the website and I’m confident in that analysis and its outcome.
Try and discover what you don’t know. Maybe your design isn’t consistent or you didn’t know you should round the corners of your 3D models to make it even cuter. Or you rounded the corners too much and it looks chaotic rather than cute. When we learn design/art principles/fundamentals, we’re just learning applied psychology and describing patterns that others have already discovered about our species as humans. So you can learn the fundamentals, but also develop your own awareness of patterns across well-received projects. In a way, you create your own sense, intuition, and set of fundamentals to work from which is honestly pretty cool. I talk about this in the next section.
1.3 How to make things emotionally resonate by focusing on universal human emotions/experiences & develop your creative intuition with exercises (AKA starting a bit reductive and mechanical in order to eventually be intuitive and unique)
While we’re all unique in our own ways, we share some fundamental universal experiences and emotions. Those core feelings are exactly what you want to identify and invoke when working on your projects. We have so many terms for this like “UI design,” “3D artist,” “UX researcher,” but really at the end of the day it’s about your emotions and how you make people feel about your stuff. You’re not a “designer” or a “developer,” you’re a person who creates things that invoke emotions in yourself and others. Even a UX researcher just focuses on how to make a user less frustrated. Frustration is the core emotion of why they do the work they do. Again, as a society we just like to simplify and label things. These job titles artificially constrain you to what you think you are capable of (even if subconsciously). They constrain you to a set of practices within that established “domain” and don’t encourage out-of-domain thinking and cross pollination. Think outside of your domain and more universally.
I breakdown the emotional design components of the demo scenes for this article below to hopefully show that focusing on the core fundamental concepts leads to a lot of shared patterns. I am not focusing on the obvious idea that they’re personalized for Codrops which causes an emotional impact, just broadly applicable design patterns.
There are three key factors I want to point out (there are many others I want to include, but for the sake of simplicity, let’s focus on these). These factors contribute how emotionally impactful something you create would be, for example if it feels completed, full, original and filled with emotional artifacts people will recognize the effort and the thoughtfulness.
Completion – how much percentage of the scene is done. Of course this metric is very subjective. For example, if you’re doing something standalone rather than a full scene, that emotional context is different. Sometimes “less is more.” But let’s keep it simple for now.
Time spent tweaking – how “original” you could probably say it was relative to my amount of copying from references/inspiration.
Universal Emotions – the (broader/high-level) emotions that each scene is intended to invoke.
Notice how all of these scenes are different styles, but the key factors are pretty similar. This suggests that the overall emotional impact of all of these scenes is pretty similar even if that impact is appealing to different audience demographics due to stylistic and theming preferences. In other words, some people might like one style over the other (toonish 2.5D vs stylistic 3D vs realism paper) or the general idea better (like if you like food you’d prefer the sushi shop, or if you prefer adventure you’d like the paper world), but no matter which demographic it appeals to, the appeal is likely equal.
That impact is as follows: enough to be inspirational, but not enough to be as emotionally impactful as more polished projects can. So lets go one by one on these factors for each of these scenes to see why that’s their resulting impact as well as uncover some emotional design patterns.
For the Paper Pirate One
Completion(5/10) – This scene is far from complete. It’s missing quite a few details like clouds, sun rotating, birds moving etc. It could also use better animations on-scroll rather than a slight move left to right. For example, when I enter the scene all the puppet sticks could animate in from the top and bottom respectively or Miffy’s arm could be slightly moving and maybe on click of Miffy, Miffy will jump and take a swing at the Codrops Sea Monster in which the Sea Monster will bounce back with a little bit before returning to fight making the scene much more engaging. Similarly, I could click on Panda Boris and he might tag team jump with Miffy, etc.
Time spent tweaking (5/10) – For this idea, I’ve seen a lot of online puppet shows (albeit with wood) that have very similar concepts which is how I came up with the idea. It’s pretty non-original except instead of using wood I decided to use paper. Even though my original inspiration was from wood puppet shows, I later discovered paper puppet shows already exist too. Now everyone who knows about paper puppet shows thinks I’m unoriginal and probably copied those even when I didn’t (and that’s kind of beautiful at the same time). The characters are just adjusted copies of graphics online with different outfits (Original Miffy art and Boris art here). Both pirate outfits are super common online too. So technically I didn’t do anything special what-so-ever. The most “unique” thing in this scene was the Codrops Sea Monster and that was inspired by Sid from Ice Age.
Universal Emotions (Cute, Playful, Adventure) –
Cute – The characters themselves, overly rounded cutouts, and exaggerated proportions (like the Codrops Sea Monster’s Eyes or the ships sail) = soft and round like plushies or bears, but conveyed through paper.
Playful – These are children’s characters dressing up as pirates which is inherently playful. There’s also the element of using notebook paper, taking something mundane and turning it as a source of joy that feels playful.
Adventure – Adventure isn’t technically a “universal emotion” but it’s an adjective that contains an experience or set of universal human emotions like fear and excitement etc. So you could break it down further into those core emotions if you want to, but for simplicity let’s use this adjective and call it a universal experience. There are many elements of adventure here, the idea of traveling on the open sea, fighting a fantasy monster, and being a pirate likely infers more adventures and treasures etc. It’s also a “safe danger” medium in the sense that you’re never actually going to fight a sea monster like this because it is digital. It’s the same way if you’re around an insect expert who knows which insects are dangerous or not. If you’re usually afraid of the woods because of insects, having that expert near you will make you feel safer and want to go into the woods and feel that adventure and the thrill of “safe danger.”
For the Sushi & Ramen RestaurantOne
Completion(5/10) – Again, this scene is far from complete. There’s not much detail in the restaurant and not much story telling around the shop and Pusheen seems to be just placed there with no real context other than minimal contribution to the cuteness factor. Quite honestly, if Pusheen was by herself it might have more of an emotional impact than the entire scene has collectively because it would be in a different frame of context compared to a whole scene. Also the colors aren’t quite done as they feel a bit rushed like the plant pot and the informational sign upfront just uses white bars rather than something cooler like characters/shapes of food in a more playful way.
Time spent tweaking (5/10) – If you look at the original scene I was inspired from, you can see the idea is pretty much the same, cute animal, slight handpainted shine and colorful mixing. The only difference I did was adapt the characters to a new style and add a bunch of food stuff.
Universal Emotions (Cute, Playful, Craving) –
Cute – Again, very rounded characters, bright colors.
Playful – It’s inherently playful having characters like a rabbit or panda cooking. Especially since they’re kids and the restaurant is in the shape of the Codrops logo, it feels more like engaging in a dress-up pretend activity rather than running a real restaurant.
Craving – Okay, need I say more? FOOD!!!! 😋😋😋😋😋😋That moment when you wanna eat something you love and find delicious, pure euphoria.
For Snow Scene One
Completion(5/10) – Yes, this scene is far from complete as well; missed opportunity to add more tree decorations, have them swaying/bouncing to the music. Could’ve added some cute presents and snow bunnies roaming around etc.
Time spent tweaking (5/10) – Look at the original scene I was inspired by. I didn’t really do anything new and the outfits were copies from official Miffy videos.
Universal Emotions (Cute, Playful, Mischievous) –
Cute – Like the other two, very round-like and using stylized textures rather than realism ones for the wood, stone, tree etc.
Playful – It’s a snowball fight with a snowman and outdoor winter activities.
Mischievous – There’s a “no codrops” sign there, for whatever reason I don’t know, but just the fact is there adds to the rebellious vibe. Most importantly though you can see Miffy throwing snowballs at the house which is mischievous.
Of course, there are a lot of other factors, such as who created the scene, the purpose of the scene, how familiar people are with 3D art/websites, when the website was posted, where it was posted, etc. that all contribute to the emotional impact. However, this section is just focused on getting someone to think about emotional design (i.e., the core of why we do what we do) rather than just metrics (e.g., how many views/likes you’ll get). The moment you start creating things while focusing on the emotion behind the scenes is how you become better at observing and identifying your knowledge gaps. Notice how all three scenes are in three different styles yet all feel cute? Once you identify and internalize what evokes the cuteness emotional feeling, it will apply to whatever you decide to execute with that emotion.
Take a look at the art below. The primary emotion/experience is cute. Think about why, notice the gradients, the color mixing and color palette, the faces on the characters, the use of miniatures to signify smallness, all the round stuff, and the handpainted highlights etc. You’ll see these patterns repeated across cute works in a variety of different styles. It’s all very similar principles just in a different style. You can also see how so many different artists land on very similar styles independently or get inspired from each other ALL the time. It’s just like how two people independently discovered calculus or how programmers copy and tweak open-source code repos. We all share universal human emotions and experiences, they are bound to be repeated. All you have to do is identify those emotional design patterns. It’s not much different from relating to someone who got a paper cut when you get a paper cut. That is a universal emotional pattern just like these art pieces of cuteness.
Guess where else these emotional design patterns exist? You’re absolutely correct! UI designs, typography, in real life, etc.! Take a look at the following, all very roundish again. You intuitively know it your entire life, but hopefully putting it side by side shows how similar everything really is. It’s not magic, it’s observation.
Random images of cute things I found online. They seem disconnected from each other, but they’re all so consistently round and puffy (which are the exact factors that contribute to the universal emotional design pattern)!
You don’t have to be a 3D artist, UX researcher, UI designer, a game developer, a chef, or an animal expert to recognize all these things make you feel cuteness. That universal emotion pattern is consistent across all these “fields”/”domains.”
If this is so “obvious” then why am I not super rich and famous like these other artists? Likewise, why aren’t the creativity and cognitive science researchers rich and famous if they “know” what creativity is? Why not just create a complete project, go viral, and make a lot of money? Well, because we’re humans and we each have our own limitations and personal goals.
For me specifically, I’m a teacher. I can guide someone in a direction, but it doesn’t necessarily mean I’m the “best” at that direction. It’s like saying all high-school math teachers should stop teaching math because they’re not innovative in their math field. I’m just a teacher, not a standout top-tier practitioner. My main source of emotional satisfaction is from inspiring beginner creatives with concept websites rather than spending the extra days/weeks polishing a project for maximum impact among more experienced individuals.
Of course, the opposite is true as well. Just because someone is a standout top-tier practitioner does not mean they feel fulfilled from teaching and can teach well. Someone can be highly creative without being self-aware enough to break down how they developed their creativity in easily digestible pieces of information.
1.4 Applying what we learned with creativity exercises
Talk is cheap, so let’s put the things discussed in this article into practice. If you want, open up a design tool like Figma to follow along. You don’t need to be creative or artistic at all to follow along, which is the whole point of this article.
Emotional design principles + copying and tweaking = “new” art
Take a look at the image directly above, let me walk you through these steps that you can try on your own. We’re basically copying the two existing art works and combining them to make something “new” with emotional design tweaks.
Step 1 – Make a rectangle.
Step 2 – Round the corners to suggest softness [cute emotional design pattern applied]
Step 3 – Make the stroke width thicker to suggest thickness and plumpiness [cute emotional design pattern applied]
Step 4 – Round and bloat the whole entire shape to signify plumpness [cute emotional design pattern applied]
Step 5 – Copy the face from the pink pixel art character and add another box for the straw detail [copy real-life juice boxes and artist].
Step 6 – Thicken the outline just like the body [cute emotional design pattern applied]
Step 7 – Round the straw just like the body [cute emotional design pattern applied]
Step 8 – Add a hole for the straw to make it blend in and copy the diamond stars from Levi’s art [copy real-life juice boxes and artist]
Step 9 – Copy the diamond stars from Levi’s art [copy artist]
In probably a minute or two, you’ve just created a cute juice box character 🥳🥳🥳!!! You should be really proud of yourself and I’m proud of you 😊!! Obviously, it’s nothing that will stand out, but that’s how we all start. You might feel like you just copied those two artists, but that’s exactly what creativity is: copying and tweaking!!! You are ALWAYS the sum of the world around you, so lean into that when you make things. Now you can just copy these principles to any sort of object you want, like a cute rock character! The more you practice, the better your intuition will be and the faster you get at tweaking!
Literally a random rock character made in 10 seconds with the copy and pasted face + diamond stars
So what to do next? Well, just keep practicing. Maybe take four reference images and copy something you like from each of those references to create something “new.” Like you could even copy me and extend it, why not make a rock shaped juice box cute character? WHO’S STOPPING US FROM MAKING A ROCK SHAPED JUICE BOX MWHAHAAHAHAHAHAHAHA 😈😈😈😈. And of course, observe more. Did you take a look at the ghost’s face in the Tea Bag by JZ in the image above? Doesn’t it look very similar to the character we copied from? The mouth is just closer to the eyes and elongated! The face is also missing the blush, but we can keep that for our ghost versions!
Another exercise is practicing medium transfer. The video below is a PowerPoint presentation I made two years ago for a college class. You could recreate something similar on a website! Copy it and tweak it with HTML/CSS/JS. Make a reusable case file component. Of course, you don’t have to use what I did. Just take something from one medium that you like and put it into a different medium. In this case, it went from real-life looking case files -> PowerPoint presentation -> website interaction. Notice the job titles and mediums: FBI agent (real case files), a designer (PowerPoint), and a programmer (website implementation). Be the bridge between mediums. Or should I say, be the medium between the mediums haha.
There’s so many other ways you can use this same exact FBI context, for example:
Case files are secretive, so why not add an easter egg on your website that is secretive?
You could add a secret code, letters you can click on to discover and unscramble to unlock a hidden portion of your website.
Crime’s emotions/experiences are dark, intense, suspicious, and moody, think about what kind of color palette is associated with that.
The last exercise I’ll give is literally just to trial and error random stuff. Don’t even think about what you’re doing. Don’t look at the clock, just take a reference and run with it quickly. Don’t worry about if it’s a “good” reference or anything like that at all. If it ends up being fun then you can continue! Creativity is just as much trial and error as coding or anything else you’re learning. You can see below I googled a random architecture image online and used that to design a graphic using the same exact copy and pasted face from our juice box character, just with added eyebrows. The character shape is from the image, and the “beard” is just the stair railings. Everything is source material if you want it to be.
Just some random copying and tweaking. Let yourself go, remove the pressure of creating something cool. Just make something and have fun when you do it. Stop thinking how good it is or what’s the purpose. The only purpose is to have fun.
You can also seem “deep” and make up stuff in your existing works, like my secret hidden message is “LOVE.” It wasn’t intended at all, but I’ll pretend that it was intentional and I totally didn’t just discover this looking in retrospect! The point isn’t to seem deep to others, but to discover unseen patterns in your own works! This way, when you are inspired by something, your brain will naturally start looking for ways to incorporate actual deep hidden meanings in your works. Look for meanings when there are no meanings, exactly as I did here.
Randomly discovering a secret word (“LOVE”) in my scenes in retrospect for fun.
In closing, don’t just stop at the feeling that you’re feeling. Ask yourself “why” you feel the way that you do and why others feel the way they do. What is it about that thing that makes you and others feel that way? Develop that self-awareness and empathy. You’ll discover so many patterns and the exceptions too, like making cute things with sharp objects instead of rounded ones. Once you understand how to convey emotions, you can bend the rules and emotions you evoke in any way you want to. You’ll eventually tweak so much and end up developing your own style before you even realize it! People will ask you to make something and you can quickly do so even without looking at a reference! Of course, that doesn’t mean give up references, but it does mean you’ve finally developed that ability and intuition.
Analyzing emotions is not meant to take away the innocence of our spontaneous and authentic feelings. If anything, being aware of them make us feel them deeper and warmer. It’s like knowing how your favorite food is made. If anything, it just makes you appreciate your favorite food more.
1.5 Pattern matching outside of art
I hope this article makes it clear that pattern matching is basically just your intuition and exists elsewhere outside of analyzing art. You actually do it every single day whether you realize it or not (e.g., when you’re trying to read/guess other people’s intentions). This article just makes it more explicit by taking a look at the intuitive brain of a creative person.
Bringing your subconscious processes to your conscious brain feels unnatural, but it gets easier over time. It’s just developing self-awareness; like when you were a toddler you weren’t really self-aware, but as you get older, you discover more parts of yourself. Some people never work on self-awareness and they peak emotionally, that’s why you have abusive parents who are 50+ years old. Working on yourself is always a choice.
You can see extreme forms of pattern matching like what we did outside of the art field. For example, this famous YouTuber can quickly identify locations based on just a sky or ground! It seems bizarre, but if you break it down into patterns, it actually makes sense on how someone is capable of doing something that amazing. Like certain countries have certain trees, certain clouds, certain skies, etc. Most people don’t see these patterns. They just think sky = sky, rather than sky = gradient + colors + type of cloud + direction of gradient + certain skies + is it night/time day time + weather assosiated with type of cloud/sky + which countries have certain weathers more likely to produce that kind of cloud/sky. He sees all those patterns that others don’t.
It’s also partly the fact that games like GeoGuessr aren’t updated constantly with new images of places so when you guess on photos that aren’t pure skies, you somewhat memorize intuitvely what kind of skies are matched with what kind of places. In other words, if you look at the same 10,000 images 100 times, then even if you don’t pay attention to the skies in those 10,000 images, your brain already by default picked up subconcious patterns and intuition you can tap into later when you need them.
Pattern matching for him is like “Okay this image has type A trees which means XYZ countries, and it has type B concrete which means XZ countries, and it has type C clouds which means it likely has weather type G which means it’s in the northern hemisphere so it’s likely country Z.” That’s how it works when you make art too! More on emotional pattern matching and similar topics in the future articles!
2. Technical Implementation
This section will just briefly talk about some technical details of this project. I didn’t do many new things in this article compared to the one I wrote here (just make sure to check the ReadMe file on GitHub for the corrections to that article as well). This project is also mainly coded with AI generated code so don’t look at the code for any inspiration there 😅. This section is not beginner friendly and assumes knowledge of Blender and programming concepts.
2.1 Created a Blender Python Script using AI to select all objects and add a second UV Map named “SimpleBake”
For the SimpleBake Blender addon, there’s an option that allows you to use a pre-existing UV Maps named “SimpleBake.” it’s super tedious to manually select each object and create that UV Map so I asked ChatGPT to generate me a script that does it automatically.
import bpy
# Loop through all mesh objects in the scene
for obj in bpy.data.objects:
if obj.type == 'MESH':
uv_layers = obj.data.uv_layers
# Add "SimpleBake" UV map if it doesn't exist
if "SimpleBake" not in uv_layers:
new_uv = uv_layers.new(name="SimpleBake")
print(f"Added 'SimpleBake' UV map to: {obj.name}")
else:
new_uv = uv_layers["SimpleBake"]
print(f"'SimpleBake' UV map already exists in: {obj.name}")
# Set "SimpleBake" as the active (selected) UV map — but not the render UV map
uv_layers.active = new_uv # SELECTED in the UI
2.2 Created a Blender Addon with AI to export curve as JSON or a three.js curve
Basically the title, I created this with Claude AI with three prompts. The first was creating the plugin that could export a curve as points, then asking it to only export the control points not sampled points, and the third prompt was to put it in three.js curve format and update the coordinate system. With better prompting you could probably do it with one prompt.
bl_info = {
"name": "Curve to Three.js Points Exporter",
"author": "Claude",
"version": (1, 0),
"blender": (3, 0, 0),
"location": "File > Export > Curve to Three.js Points",
"description": "Export curve points for Three.js CatmullRomCurve3",
"warning": "",
"doc_url": "",
"category": "Import-Export",
}
import bpy
import bmesh
from bpy.props import StringProperty, IntProperty, BoolProperty
from bpy_extras.io_utils import ExportHelper
from mathutils import Vector
import json
import os
class ExportCurveToThreeJS(bpy.types.Operator, ExportHelper):
"""Export curve points for Three.js CatmullRomCurve3"""
bl_idname = "export_curve.threejs_points"
bl_label = "Export Curve to Three.js Points"
filename_ext = ".json"
filter_glob: StringProperty(
default="*.json",
options={'HIDDEN'},
maxlen=255,
)
# Properties
sample_count: IntProperty(
name="Sample Count",
description="Number of points to sample from the curve",
default=50,
min=3,
max=1000,
)
export_format: bpy.props.EnumProperty(
name="Export Format",
description="Choose export format",
items=[
('JSON', "JSON", "Export as JSON file"),
('JS', "JavaScript", "Export as JavaScript file"),
],
default='JSON',
)
point_source: bpy.props.EnumProperty(
name="Point Source",
description="Choose what points to export",
items=[
('CONTROL', "Control Points", "Use original curve control points"),
('SAMPLED', "Sampled Points", "Sample points along the curve"),
],
default='CONTROL',
)
include_tangents: BoolProperty(
name="Include Tangents",
description="Export tangent vectors at each point",
default=False,
)
def execute(self, context):
return self.export_curve(context)
def export_curve(self, context):
# Get the active object
obj = context.active_object
if not obj:
self.report({'ERROR'}, "No active object selected")
return {'CANCELLED'}
if obj.type != 'CURVE':
self.report({'ERROR'}, "Selected object is not a curve")
return {'CANCELLED'}
# Get curve data
curve = obj.data
# Sample points along the curve
points = []
tangents = []
if self.point_source == 'CONTROL':
# Extract control points directly from curve
for spline in curve.splines:
if spline.type == 'NURBS':
# NURBS curve - use control points
for point in spline.points:
# Convert homogeneous coordinates to 3D
world_pos = obj.matrix_world @ Vector((point.co[0], point.co[1], point.co[2]))
# Convert Blender (Z-up) to Three.js (Y-up): X, Z, -Y
points.append([world_pos.x, world_pos.z, -world_pos.y])
elif spline.type == 'BEZIER':
# Bezier curve - use control points
for point in spline.bezier_points:
world_pos = obj.matrix_world @ point.co
# Convert Blender (Z-up) to Three.js (Y-up): X, Z, -Y
points.append([world_pos.x, world_pos.z, -world_pos.y])
elif spline.type == 'POLY':
# Poly curve - use points
for point in spline.points:
world_pos = obj.matrix_world @ Vector((point.co[0], point.co[1], point.co[2]))
# Convert Blender (Z-up) to Three.js (Y-up): X, Z, -Y
points.append([world_pos.x, world_pos.z, -world_pos.y])
else:
# Sample points along the evaluated curve
depsgraph = context.evaluated_depsgraph_get()
eval_obj = obj.evaluated_get(depsgraph)
mesh = eval_obj.to_mesh()
if not mesh:
self.report({'ERROR'}, "Could not convert curve to mesh")
return {'CANCELLED'}
# Create bmesh from mesh
bm = bmesh.new()
bm.from_mesh(mesh)
# Get vertices (points along the curve)
if len(bm.verts) == 0:
self.report({'ERROR'}, "Curve has no vertices")
bm.free()
return {'CANCELLED'}
# Sample evenly distributed points
for i in range(self.sample_count):
# Calculate interpolation factor
t = i / (self.sample_count - 1)
vert_index = int(t * (len(bm.verts) - 1))
# Get vertex position
vert = bm.verts[vert_index]
world_pos = obj.matrix_world @ vert.co
# Convert Blender (Z-up) to Three.js (Y-up): X, Z, -Y
points.append([world_pos.x, world_pos.z, -world_pos.y])
if self.include_tangents:
world_normal = obj.matrix_world.to_3x3() @ vert.normal
# Convert normal to Three.js coordinate system
tangents.append([world_normal.x, world_normal.z, -world_normal.y])
bm.free()
if len(points) == 0:
self.report({'ERROR'}, "No points found in curve")
return {'CANCELLED'}
# Prepare export data
export_data = {
"points": points,
"count": len(points),
"curve_name": obj.name,
"blender_version": bpy.app.version_string,
}
if self.include_tangents:
export_data["tangents"] = tangents
# Export based on format
if self.export_format == 'JSON':
self.export_json(export_data)
else:
self.export_javascript(export_data)
self.report({'INFO'}, f"Exported {len(points)} points from curve '{obj.name}'")
return {'FINISHED'}
def export_json(self, data):
"""Export as JSON file"""
with open(self.filepath, 'w') as f:
json.dump(data, f, indent=2)
def export_javascript(self, data):
"""Export as JavaScript file with Three.js code"""
# Change file extension to .js
filepath = os.path.splitext(self.filepath)[0] + '.js'
with open(filepath, 'w') as f:
f.write("// Three.js CatmullRomCurve3 from Blender\n")
f.write("// Generated by Blender Curve to Three.js Points Exporter\n")
f.write("// Coordinates converted from Blender (Z-up) to Three.js (Y-up)\n\n")
f.write("import * as THREE from 'three';\n\n")
# Write points array
f.write("const curvePoints = [\n")
for point in data["points"]:
f.write(f" new THREE.Vector3({point[0]:.6f}, {point[1]:.6f}, {point[2]:.6f}),\n")
f.write("];\n\n")
# Write curve creation code
f.write("// Create the CatmullRomCurve3\n")
f.write("const curve = new THREE.CatmullRomCurve3(curvePoints);\n")
f.write("curve.closed = false; // Set to true if your curve should be closed\n\n")
# Write usage example
f.write("// Usage example:\n")
f.write("// const points = curve.getPoints(100); // Get 100 points along the curve\n")
f.write("// const geometry = new THREE.BufferGeometry().setFromPoints(points);\n")
f.write("// const material = new THREE.LineBasicMaterial({ color: 0xff0000 });\n")
f.write("// const line = new THREE.Line(geometry, material);\n")
f.write("// scene.add(line);\n\n")
f.write("export { curve, curvePoints };\n")
def menu_func_export(self, context):
self.layout.operator(ExportCurveToThreeJS.bl_idname, text="Curve to Three.js Points")
def register():
bpy.utils.register_class(ExportCurveToThreeJS)
bpy.types.TOPBAR_MT_file_export.append(menu_func_export)
def unregister():
bpy.utils.unregister_class(ExportCurveToThreeJS)
bpy.types.TOPBAR_MT_file_export.remove(menu_func_export)
if __name__ == "__main__":
register()
How the addon looks and works! Select the curve object, File > Export > Addon > Choose Control Points and format as JavaScript.
2.3 A boat load of conditional rendering
There were no complex render targets or anything like that for scene transitions, it was just pre-positioned 3D objects toggling its visibility on and off with conditional rendering based on the progress value the camera is along the curve. It’s not really a good practice for more complex scenes like these as it can cause crashes if you conditionally render a ton at a time, but works for a demo on most desktop/laptops at least.
How the models were setup in Blender
2.4 Creating invisible bounding boxes for SVGs with Figma
When I wanted to make sleeping Miffy and Panda Boris for the nighttime ship scene, I did not design them with the same size as their day versions. That means when I replaced the image textures with the night versions, the default UV map no longer looked good with them. While I could adjust the UV or position of the plane with code, it’s easier just to create an invisible bounding box with the same width and height as the day characters in Figma and have the nighttime characters fit within that bounding box.
Sleeping Boris character grouped together with a bounding box.
Final Words
I’m not a programmer, an artist, or a UI designer. I’m someone who creates things.
I’m not a creative. I’m a copier who tweaks things.
I’m not talented. I’m an observer recognizing emotions.
You can call yourself a programmer, an artist, a creative, or whatever you want if the time calls for it, but don’t let these words define you and your capabilities. The only way to stay relevant with AI in the picture is by incorporating cross-domain thinking beyond labels. Become interdisciplinary. It sounds daunting, but if you have the right learning systems in place, you can somewhat learn multiple domains in roughly the same time it would take you to learn one domain with ineffective learning systems (e.g., spending 1000 hours in tutorial hell in one domain vs spending 1000 hours pattern matching across multiple domains). Effective learning systems will show you connections and parallels between fields of study, speeding up your learning process. It’s quite similar to how we identified a core emotional design pattern that shows up in real-life, 3D art, 2D art, and UI designs.
Yes, this article does have elements of survivorship bias, as there are many people who create round things and don’t end up creating cute things that spark emotional resonance because there are way more factors to creating something cute than just making round things, but the purpose was to show a path that many creative people take to become more creative rather than showing every last step of intuition development and every single observation and design choice. In the future articles, I’ll be addressing more components on how to make the “tweaking” phase more effective.
As humans, we like to take complex arguments and simplify them with our pre-existing biases and treat those simplifcations as fundamentally true when they’re just partial truths. Simplifications like those in this article are not truths, they’re building blocks to help guide someone to a specific view (in this case, the view is that creativity is learnable). This article provided a highly reductive and systematic/analytical system for creativity that I hope will naturally lead someone to develop creative intuition and spontaneous insight.
If you look at your life, there are probably so many moments you thought something was too difficult at first until you realized it wasn’t, whether that be getting in a relationship, public speaking, calculus, 3D art, programming, or literally anything you used to be afraid of and now aren’t. Treat creativity just like those things. Just another thing you think is difficult but know you’ll get better at with time.
Anyway, I hope this article unlocked some potential cognitive blockers you have and made you realize that you’ve got hidden skills inside of you. Growth is slow and quite painful at times. Take your time! Or maybe you’re perfectly happy where you’re at and don’t really want to change, which is totally okay as well. Like I said, never judge yourself and I’m not going to judge or pressure you either. You’re special in your own way. Your interpretation of this article, whether you think it’s good or bad, helpful or not helpful, that’s what makes you special.
Don’t judge, just reflect and seek to understand. Time will show you your values.
Hi, I’m Daiki Fujita, a designer based in Tokyo, Japan. In this case study, I’ll walk you through the making of my 2025 portfolio.
Background
This project began with two motivations: reaching my 10-year milestone as a designer, and wanting to create a platform to showcase my work more openly.
When I thought about my roots as a designer, I looked back to my childhood. My family ran a small electronics shop, and I was given a PC at an early age. I remember spending hours drawing with the Paint tool on Windows 95. That sense of joy and excitement—being able to make pictures on a computer—stayed with me. For this site, I wanted to capture that feeling and connect it to the concept of “Abstract & Concrete.”
Overview
In today’s world, where digital technology evolves so quickly and information is consumed in an instant, I wanted to focus on communicating only the essentials. That became the axis of the concept: balancing abstraction and concreteness.
To embody this visually, I kept the design minimal: only two colors, and elements based on points and planes. These became the foundation for three expressive styles—particles, pixel art, and mosaic art—unifying the atmosphere of the site and creating an immersive experience.
For this site, I decided to experiment with Framer, which I had been curious about for some time. The effects and animations were developed as original code components in React.
Design Approach
Particle
To express the idea of “seeing, touching, and feeling” each project, I used particle-based interactions. For every work, I created a key object and transformed it into particles.
These particle elements were built with an originally developed code component. Attributes such as particle count, size, color, position, and the degree and range of mouse pointer interaction can all be adjusted—and many other properties as well—through the GUI. Adding or updating works is designed to be simple—just upload an SVG.
This site is my personal portfolio, and each project featured here is a crystallization of my own work, expressed through the morphing of key objects. In addition, I enhanced the sense of immersion by adding a background effect where a particle-constructed space seems to warp dimensions as you scroll.
2D Graphic Effects
To reinforce the visual identity, I incorporated graphical effects made of planes. These appear during page landings and transitions, giving the site a consistent atmosphere.
Mosaic Effects
For project content, I used a pixel-reveal effect. By gradually visualizing the work, it sparks curiosity and invites viewers to stop and engage more deeply.
Subliminal Elements
The elements that flash randomly for a split second are inorganic in shape. They don’t carry meaning on their own, but they’re meant to raise a question: “In an age where information disappears in an instant, are we really grasping its essence?”
Hidden Details
I didn’t want the site to just feel sleek and stylish. So I added playful touches—like eyes that follow the cursor, or elements that fall asleep if left idle. I’m always sleepy.
The Tech Stack
Frontend: Framer, React
CMS: Framer CMS
Design: Figma, Framer
Closing
Thanks so much for reading!
Creating this portfolio allowed me to reconnect with the same joy and excitement I felt as a kid, drawing on a computer for the first time. I poured that feeling into the site, and if visitors can feel even a little of that joy through this website, I would be truly happy!
Senders and Receivers handle errors on Azure Service Bus differently. We’ll see how to catch them, what they mean and how to fix them. We’ll also introduce Dead Letters.
Table of Contents
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
In this article, we are gonna see which kind of errors you may get on Azure Service Bus and how to fix them. We will look at simpler errors, the ones you get if configurations on your code are wrong, or you’ve not declared the modules properly; then we will have a quick look at Dead Letters and what they represent.
This is the last part of the series about Azure Service Bus. In the previous parts, we’ve seen
For this article, we’re going to introduce some errors in the code we used in the previous examples.
Just to recap the context, our system receives orders for some pizzas via HTTP APIs, processes them by putting some messages on a Topic on Azure Service Bus. Then, a different application that is listening for notifications on the Topic, reads the message and performs some dummy operations.
Common exceptions with .NET SDK
To introduce the exceptions, we’d better keep at hand the code we used in the previous examples.
Let’s recall that a connection string has a form like this:
To send a message in the Queue, remember that we have 3 main steps:
create a new ServiceBusClient instance using the connection string
create a new ServiceBusSender specifying the name of the queue or topic (in our case, the Topic)
send the message by calling the SendMessageAsync method
awaitusing (ServiceBusClient client = new ServiceBusClient(ConnectionString))
{
ServiceBusSender sender = client.CreateSender(TopicName);
foreach (var order in validOrders)
{
/// Create Bus Message ServiceBusMessage serializedContents = CreateServiceBusMessage(order);
// Send the message on the Busawait sender.SendMessageAsync(serializedContents);
}
}
To receive messages from a Topic, we need the following steps:
create a new ServiceBusClient instance as we did before
create a new ServiceBusProcessor instance by specifying the name of the Topic and of the Subscription
Of course, I recommend reading the previous articles to get a full understanding of the examples.
Now it’s time to introduce some errors and see what happens.
No such host is known
When the connection string is invalid because the host name is wrong, you get an Azure.Messaging.ServiceBus.ServiceBusException exception with this message: No such host is known. ErrorCode: HostNotFound.
What is the host? It’s the first part of the connection string. For example, in a connection string like
So we can easily understand why this error happens: that host name does not exist (or, more probably, there’s a typo).
A curious fact about this exception: it is thrown later than I expected. I was expecting it to be thrown when initializing the ServiceBusClient instance, but it is actually thrown only when a message is being sent using SendMessageAsync.
You can perform all the operations you want without receiving any error until you really access the resources on the Bus.
Put token failed: The messaging entity X could not be found
Another message you may receive is Put token failed. status-code: 404, status-description: The messaging entity ‘X’ could not be found.
The reason is pretty straightforward: the resource you are trying to use does not exist: by resource I mean Queue, Topic, and Subscription.
Again, that exception is thrown only when interacting directly with Azure Service Bus.
Put token failed: the token has an invalid signature
If the connection string is not valid because of invalid SharedAccessKeyName or SharedAccessKey, you will get an exception of type System.UnauthorizedAccessException with the following message: Put token failed. status-code: 401, status-description: InvalidSignature: The token has an invalid signature.
The best way to fix it is to head to the Azure portal and copy again the credentials, as I explained in the introductory article.
Cannot begin processing without ProcessErrorAsync handler set.
Let’s recall a statement from my first article about Azure Service Bus:
The PizzaItemErrorHandler, however, must be at least declared, even if empty: you will get an exception if you forget about it.
That’s odd, but that’s true: you have to define handlers both for manage success and failure.
If you don’t, and you only declare the ProcessMessageAsync handler, like in this example:
and acts as a catch block for the receivers: all the errors we’ve thrown in the first part of the article can be handled here. Of course, we are not directly receiving an instance of Exception, but we can access it by navigating the arg object.
As an example, let’s update again the host part of the connection string. When running the application, we can see that the error is caught in the PizzaItemErrorHandler method, and the arg argument contains many fields that we can use to handle the error. One of them is Exception, which wraps the Exception types we’ve already seen.
This means that in this method you have to define your error handling, add logs, and whatever may help your application managing errors.
The same handler can be used to manage errors that occur while performing operations on a message: if an exception is thrown when processing an incoming message, you have two choices: handle it in the ProcessMessageAsync handler, in a try-catch block, or leave the error handling on the ProcessErrorAsync handler.
In the above picture, I’ve simulated an error while processing an incoming message by throwing a new DivideByZeroException. As a result, the PizzaItemErrorHandler method is called, and the arg argument contains info about the thrown exception.
I personally prefer separating the two error handling situations: in the ProcessMessageAsync method I handle errors that occur in the business logic, when operating on an already received message; in the ProcessErrorAsync method I handle error coming from the infrastructure, like errors in the connection string, invalid credentials and so on.
Dead Letters: when messages become stale
When talking about queues, you’ll often come across the term dead letter. What does it mean?
Dead letters are unprocessed messages: messages die when a message cannot be processed for a certain period of time. You can ignore that message because it has become obsolete or, anyway, it cannot be processed – maybe because it is malformed.
Messages like these are moved to a specific queue called Dead Letter Queue (DLQ): messages are moved here to avoid making the normal queue full of messages that will never be processed.
You can see which messages are present in the DLQ to try to understand the reason they failed and put them again into the main queue.
in the above picture, you can see how the DLQ can be navigated using Service Bus Explorer: you can see all the messages in the DLQ, update them (not only the content, but even the associated metadata), and put them again into the main Queue to be processed.
Wrapping up
In this article, we’ve seen some of the errors you can meet when working with Azure Service Bus and .NET.
We’ve seen the most common Exceptions, how to manage them both on the Sender and the Receiver side: on the Receiver you must handle them in the ProcessErrorAsync handler.
Finally, we’ve seen what is a Dead Letter, and how you can recover messages moved to the DLQ.
This is the last part of this series about Azure Service Bus and .NET: there’s a lot more to talk about, like dive deeper into DLQ and understanding Retry Patterns.
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
Imagine this: you have created a method that creates a new user in your system, like this:
void CreateUser(string username)
{
if (string.IsNullOrEmpty(username))
thrownew ArgumentException("Username cannot be empty");
CreateUserOnDb(username);
}
void CreateUserOnDb(string username)
{
Console.WriteLine("Created");
}
It looks quite safe, right? Is the first check enough?
Let’s try it: CreateUser("Loki") prints Created, while CreateUser(null) and CreateUser("") throw an exception.
What about CreateUser(" ")?
Unfortunately, it prints Created: this happens because the string is not actually empty, but it is composed of invisible characters.
The same happens with escaped characters too!
To avoid it, you can replace String.IsNullOrEmpty with String.IsNullOrWhiteSpace: this method performs its checks on invisible characters too.
Do you have to replace all String.IsNullOrEmpty with String.IsNullOrWhiteSpace?Probably yes, unless you have a specific reason to consider the latest three values in the table as valid characters.
I’m Oliver Muñoz, the founder of Uncommon, a digital studio based in Melbourne. These days, I focus less on fine pixels myself and more on leading teams across time zones to do their best work.
After more than a decade freelancing, I decided I wanted to spend more time with my family and less in front of the computer. My first son was about to be born, and I knew I had to make a choice: keep designing every detail myself, or step into leadership and create more space to be present at home. That decision to delegate and trust others was the moment I gave creative leadership a real go.
This story is not about pixels, code, or prototypes; it is about what it takes to lead creatives across time zones and cultures toward a shared vision that wins awards.
Origins of leadership
I always wanted to lead by example, but during my agency years, the opportunity never quite came. It could be because I was freelancing, maybe it was my craft, or perhaps it was the fact that I was an immigrant. At times, I felt I had to work double to get half as far.
One pivotal moment came after contracting for a global agency for twelve months. The design director offered me a full-time role as a Senior Designer, but I only agreed on the condition that she would mentor me into a Design Lead role within six months. She could not commit, so I declined on the spot. That was when I realised leadership was not something I would be handed; I had to create the opportunity myself.
Building a global team
At Uncommon, I believe in bringing in the right experts for each project, no matter where they are in the world. The foundation is always the same: communication, collaboration and clarity. Those three pillars do not just apply to us internally; they extend to our clients and their teams as well.
We rely on all the usual communication tools, but with one rule: every project discussion must live in the dedicated Slack channel. That way time zones do not become bottlenecks; someone in Europe can wake up and skim through everything discussed in Australia the previous day without losing context.
The other challenge is culture. Many of my team members do not speak English as their first language (mine is Español/Spanish), so sometimes feedback can come across as blunt or even harsh when literally translated. Part of my job as a leader is to read between the lines and make sure nothing gets lost or misinterpreted in translation.
Every project begins with a strategy workshop with the client. Because of geography, not everyone can join live, so we document everything and share it back with the team. From there, each creative gets space to explore, research and design independently. A few days later, we regroup online, share progress and spark new ideas off each other’s work.
I encourage the team to seek inspiration outside the obvious. If we are designing a healthcare booking system, do not just look at other healthcare apps; look at how airlines handle complex flows, or how Airbnb structures information. Borrow what works and apply it in unexpected places.
Inevitably, different perspectives lead to different opinions. When we hit a deadlock, I return to the brief and the workshop findings to guide us. Often, it comes down to cultural context; the way something works in the U.S. is not necessarily right for Australia. Luckily, I tend to choose collaborators who are already a few steps ahead of the brief, so real deadlocks are rare.
Remote leadership means I cannot control the environment in which my team works. Distractions happen. Sometimes it is tempting to accept the first idea for a small component and move on. When that happens, I ask the team to park the safe option and keep searching for something more inventive. It is not always popular in the moment; people can get frustrated with me, but when the work earns recognition from peers or even industries outside our own, the team sees the value in going the extra mile.
I have also learned I do not need to have all the answers. Initially, I attempted to solve everything on my own. Now, when in doubt, I let the team debate and find their way forward. They are the experts. My job is to steer, not dictate. Sometimes the best leadership move is simply to pause, take a breath, and let go.
Leading for outcomes
Awards were never the goal. They are a pat on the back, not the finish line. At the end of the day, an award is just the result of votes from people you have probably never met. What matters more is that the work solved the client’s problem in a way that surprised them and us.
That said, awards do have a practical benefit. Clients discover us through those platforms, and it helps attract the kind of people who value craft. So while they are not everything, they have become part of our strategy for growth.
I do not see myself as a director with a rigid script, but more as a coach who sets the stage for others to shine. Part of my job is to recognise strengths, knowing who will thrive on a marketing website versus who will excel in product design, and put people in the right role.
My non-negotiables are openness and empathy. I need to stay open to better ideas than my own, and I need to understand when life outside of work affects someone’s pace.
Humility, to me, means surrounding myself with people who are better than I am. If I am consistently producing more or better work than my team, then I have hired the wrong people. The best sign that I am doing my job well is being the worst designer in the room.
Every project brings challenges, distance, culture, and deadlines, but the hardest moments are usually about trust. Trusting the team to explore without me hovering, trusting myself to step back and let them solve problems. The lesson I keep coming back to is that leadership is less about control and more about creating the conditions for trust to grow.
Inspiration and advice
Early in my career, after a failed internship, the Creative Director pulled me aside and said, “I have been to your country, eaten your food, talked to the locals. You need to embrace who you are and where you come from; that is how you will succeed.” That advice has stuck with me. Play to your strengths. Do not try to be something you are not.
For anyone leading a globally distributed team, my advice is simple: have cultural context. Your experiences are not the same as your team’s. Take time for casual, human conversations that are not about deadlines. Asking about someone’s cat or weekend can go further than you think.
Looking ahead, I hope leadership becomes more relaxed, more human. Less about the suit, more about the fun. We all need to remember why we started doing this in the first place.
Closing
This project proved to me that creativity does not live in a single city or time zone. It thrives when people from different backgrounds rally around a shared vision. Leadership, in this context, is about orchestrating that energy, not controlling it.
I am not here to sell a course or a product. But if you would like to follow along as I keep exploring what it means to lead and create in a global, digital-first world, you can find me on LinkedIn or Instagram. I share the wins, the lessons, and sometimes even the doubts, because that is all part of the journey.