
Codrops’ “design” has been long overdue for a refresh. I’ve had ideas for a new look floating around for ages, but actually making time to bring them to life has been tough. It’s the classic shoemaker’s shoes problem: I spend my days answering emails, editing articles and (mostly) managing Codrops and the amazing contributions from the community, while the site itself quietly gathers dust 😂
Still, the thought of reimagining Codrops has been sitting in the back of my mind. I’d already been eyeing Anima as a tool that could make the process faster, so I reached out to their team. They were kind enough to support us with this review (thank you so much!) and it’s a true win-win: I get to finally test my idea for Codrops, and you get a good look at how the tool holds up in practice 🤜🤛
So, Anima is a platform made to bridge the gap between design and development. It allows you to take an existing website, either one of your own projects or something live on the web, and bring it into a workspace where the layout and elements can be inspected, edited, and reworked. From there, you can export the result as clean, production-ready code in React, HTML/CSS, or Tailwind. In practice, this means you can quickly prototype new directions, remix existing layouts, or test ideas without starting completely from scratch.
Obviously, you should not use this to copy other people’s work, but rather to prototype your own ideas and remix your projects!
Let me take you along on a little experiment I ran with it.
Getting started

Anima Link to Code was introduced in July this year and promises to take any design or web page and transform it into live editable code. You can generate, preview, and export production ready code in React, TypeScript, Tailwind CSS, or plain HTML and CSS. That means you can start with a familiar environment, test an idea, and immediately see how it holds up in real code rather than staying stuck in the design stage. It also means you can poke around, break things, and try different directions without manually rebuilding the scaffolding each time. That kind of speed is what usually makes or breaks whether I stick with an experiment or abandon it halfway through.
To begin, I decided to use the Codrops homepage as my guinea pig. I have always wondered how it would feel reimagined as a bento style grid. Normally, if I wanted to try that, I would either spend hours rewriting markup and CSS by hand or rely on an AI prompt that would often spiral into unrelated layouts and syntax errors. It would be already a great help if I could envision my idea and play with it bit!
After pasting in the Codrops URL, this is what came out. A React project was generated in seconds.

The first impression was surprisingly positive. The homepage looked recognizable and the layout did not completely collapse. Yes, there was a small glitch where the Webzibition box background was not sized correctly, but overall it was close enough that I felt comfortable moving on. That is already more than I can say for many auto generation tools where the output is so mangled that you do not even know where to start.
Experimenting with a bento grid
Now for the fun part. I typed a simple prompt that said, “Make a bento grid of all these items.” Almost immediately I hit an error. My usual instinct in this situation is to give up since vibe coding often collapses the moment an error shows up, and then it becomes a spiral of debugging someone else’s half generated mess. But let’s try this instead of quitting right away 🙂 The fix worked and I got a quirky but functioning bento grid layout:

The result was not exactly what I had in mind. Some elements felt off balance and the spacing was not ideal. Still, I had something on screen to iterate on, which is already a win compared to starting from scratch. So I pushed further. Could I bring the Creative Hub and Webzibition modules into this grid? A natural language prompt like “Place the Creative Hub box into the bento style container of the articles” felt like a good test.
And yes, it actually worked. The Creative Hub box slipped into the grid container:

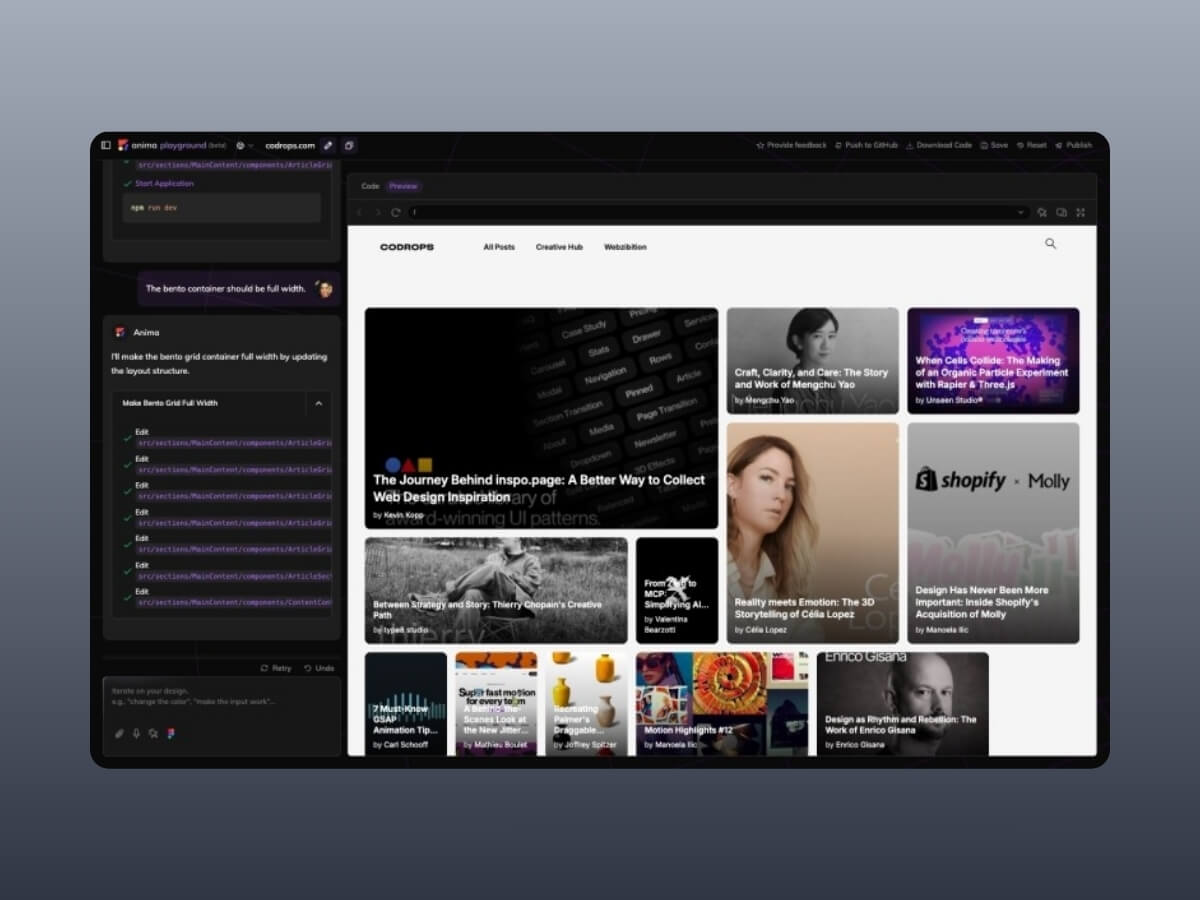
The layout was starting to look cramped, so I tried another prompt. I asked Anima to also move the Webzibition box into the same container and to make it span full width. The generation was quick with barely a pause, and suddenly the page turns into this:

This really showed me what it’s good at: iteration is fast. You don’t have to stop, rethink the grid, or rewrite CSS by hand. You just throw an idea in, see what comes back, and keep moving. It feels more like sketching in a notebook than carefully planning a layout. For prototyping, that rhythm is exactly what I want. Really into this type of layout for Codrops!
Looking under the hood
Visuals are only half the story. The bigger question is what kind of code Anima actually produces. I opened the generated React and Tailwind output, fully expecting a sea of meaningless divs and tangled class names.

To my surprise, the code was clean. Semantic elements were present, the structure was logical, and everything was just readable. There was no obvious divitis, and the markup did not feel like something I would want to burn and rewrite from scratch. It even got me thinking about how much simpler maintaining Codrops might be if it were a lean React app with Tailwind instead of living inside the layers of WordPress 😂

There is also a Chrome extension called Web to Code, which lets you capture any page you are browsing and instantly get editable code. With this it’s easy to capture and generate inner pages like dashboards, login screens, or even private areas of a site you are working on could be pulled into a sandbox and played with directly.

Pros and cons
- Pros: Fast iteration, surprisingly clean code, easy setup, beginner-friendly, genuinely fun to experiment with.
- Cons: Occasional glitches, exported code still needs cleanup, limited customization, not fully production-ready.
Final thoughts
Anima is not magic and it is not perfect. It will not replace deliberate coding, and it should not. But as a tool for quick prototyping, remixing existing designs, or exploring how a site might feel with a new structure, it is genuinely fun and surprisingly capable. The real highlight for me is the speed of iteration: you try an idea, see the result instantly, and either refine it or move on. That rhythm is addictive for creative developers who like to sketch in code rather than commit to heavy rebuilds from scratch.
Verdict: Anima shines as a playground for experimentation and learning. If you’re a designer or developer who enjoys fast iteration, you’ll likely find it inspiring. If you need production-ready results for client work, you’ll still want to polish the output or stick with more mature frameworks. But for curiosity, prototyping, and a spark of creative joy, Anima is worth your time and you might be surprised at how much fun it is to remix the web this way.