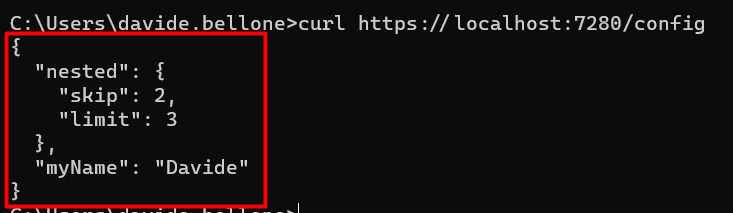
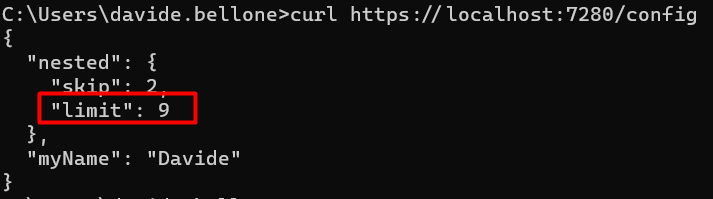
DRY is a fundamental principle in software development. Should you apply it blindly?
Table of Contents
Just a second! 🫷
If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .If you want to support this blog, please ensure that you have disabled the adblocker for this site.
I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.Thank you for your understanding.
– Davide
You’ve probably heard about the DRY principle: Don’t Repeat Yourself.
Does it really make sense? Not always.
When to DRY
Yes, you should not repeat yourself if there is some logic that you can reuse. Take this simple example:
public class PageExistingService
{
public async Task<string> GetHomepage()
{
string url = "https://www.code4it.dev/";
var httpClient = new HttpClient();
var result = await httpClient.GetAsync(url);
if (result.IsSuccessStatusCode)
{
return await result.Content.ReadAsStringAsync();
}
return "";
}
public async Task<string> GetAboutMePage()
{
string url = "https://www.code4it.dev/about-me";
var httpClient = new HttpClient();
var result = await httpClient.GetAsync(url);
if (result.IsSuccessStatusCode)
{
return await result.Content.ReadAsStringAsync();
}
return "";
}
}
As you can see, the two methods are almost identical: the only difference is with the page that will be downloaded.
pss: that’s not the best way to use an
HttpClient! Have a look at this article
Now, what happens if an exception is thrown? You’d better add a try-catch to handle those errors. But, since the logic is repeated, you have to add the same logic to both methods.
That’s one of the reasons you should not repeat yourself: if you had to update a common functionality, you have to do that in every place it is used.
You can then refactor these methods in this way:
public class PageExistingService
{
public Task<string> GetHomepage() => GetPage("https://www.code4it.dev/");
public Task<string> GetAboutMePage() => GetPage("https://www.code4it.dev/about-me");
private async Task<string> GetPage(string url)
{
var httpClient = new HttpClient();
var result = await httpClient.GetAsync(url);
if (result.IsSuccessStatusCode)
{
return await result.Content.ReadAsStringAsync();
}
return "";
}
}
Now both GetHomepage and GetAboutMePage use the same logic defined in the GetPage method: you can then add the error handling only in one place.
When NOT to DRY
This doesn’t mean that you have to refactor everything without thinking of the meanings.
You should not follow the DRY principle when
- the components are not referring to the same context
- the components are expected to evolve in different ways
The two points are strictly related.
A simple example is separating the ViewModels and the Database Models.
Say that you have a CRUD application that handles Users.
Both the View and the DB are handling Users, but in different ways and with different purposes.
We might have a ViewModelUser class used by the view (or returned from the APIs, if you prefer)
class ViewModelUser
{
public string Name { get; set; }
public string LastName { get; set; }
public DateTime RegistrationDate {get; set; }
}
and a DbUser class, similar to ViewModelUser, but which also handles the user Id.
class DbUser
{
public int Id { get; set; }
public string Name { get; set; }
public string LastName { get; set; }
public DateTime RegistrationDate {get; set; }
}
If you blinldy follow the DRY principle, you might be tempted to only use the DbUser class, maybe rename it as User, and just use the necessary fields on the View.
Another step could be to create a base class and have both models inherit from that class:
public abstract class User
{
public string Name { get; set; }
public string LastName { get; set; }
public DateTime RegistrationDate {get; set; }
}
class ViewModelUser : User
{
}
class DbUser : User
{
public int Id { get; set; }
}
Sounds familiar?
Well, in this case, ViewModelUser and DbUser are used in different contexts and with different purposes: showing the user data on screen and saving the user on DB.
What if, for some reason, you must update the RegistrationDate type from DateTime to string? That change will impact both the ViewModel and the DB.
There are many other reasons this way of handling models can bring more troubles than benefits. Can you find some? Drop a comment below 📧
The solution is quite simple: duplicate your code.
In that way, you have the freedom to add and remove fields, add validation, expose behavior… everything that would’ve been a problem to do with the previous approach.
Of course, you will need to map the two data types, if necessary: luckily it’s a trivial task, and there are many libraries that can do that for you. By the way, I prefer having 100% control of those mappings, also to have the flexibility of changes and custom behavior.
Further readings
DRY implies the idea of Duplication. But duplication is not just “having the same lines of code over and over”. There’s more:
🔗 Clean Code Tip: Avoid subtle duplication of code and logic | Code4IT
As I anticipated, the way I used the HttpClient is not optimal. There’s a better way:
🔗 C# Tip: use IHttpClientFactory to generate HttpClient instances | Code4IT
This article first appeared on Code4IT
Wrapping up
DRY is a principle, not a law written in stone. Don’t blindly apply it.
Well, you should never apply anything blindly: always consider the current and the future context.
Happy coding!
🐧