Forged is a creative studio based in Orange County, California, built at the intersection of art, code, and AI.
We craft immersive digital experiences that blend cinematic design, real-time rendering, and emerging technology from interactive websites and installations to generative storytelling, AR, and VR.
At the center of everything we make is a custom WebGPU engine, designed for high-end rendering, AI integration, and seamless cross-platform interactivity.
Whether the project lives in a browser, a physical space, or a multiplayer world, the same framework powers it; keeping creative intent perfectly aligned from concept to execution.
Learn modern web animation using GSAP 3 with 34 hands-on video lessons and practical projects — perfect for all skill levels.
Forged was founded by Michael Modena, an industry veteran who set out to build a studio that could move as fast as technology itself.
What started as a six-week experiment quickly became a new model for how a creative team could operate: small, adaptable, and obsessed with precision.
The goal wasn’t to rebuild what already existed, but to rethink it: What would a future-facing studio look like if we built it from scratch today?
The early days were defined by rhythm, mornings spent building the technical foundation, afternoons spent creating. That balance between engineering and artistry became our DNA.
The first major milestone was the creation of our own WebGPU renderer, capable of delivering film-quality lighting inside a browser. From there, Forged grew into a creative engine that now powers projects across web, physical, and immersive spaces.
Showcase
Hall of Flowers: Collective Bloom
For Hall of Flowers 2025, we created The Collective Bloom, an interactive installation powered by over 4.5 million real-time particles rendered in WebGPU. Attendees used their phones to place digital flowers into a living sculpture inspired by the Statue of Liberty, each bloom joining a growing field of color that evolved over the two-day event. What started as a simple gesture became a massive, ever-changing artwork; a collective expression of creativity brought to life through cutting-edge graphics and shared participation.
NEFT: Frozen Barrel AR
At Formula D, NEFT’s drift car giveaway became a small piece of theater: we turned their signature barrel into an AR activation. Fans entered to win, then scanned the real barrel to watch it ice over in real time and were invited to break the ice for a shot at bonus prizes. A simple giveaway transformed into a shareable, story-driven brand moment that felt as satisfying as cracking open the win.
Aura Vinyl: Color Explorer
The Aura Color Explorer reimagines how people shop for vinyl wrap. Built with real-time 3D rendering, it lets users rotate, light, and explore over a dozen vehicle models to see how each film behaves under true-to-life lighting. It’s Need for Speed in your browser. It’s become the centerpiece of Aura’s online experience, helping shoppers spend more time exploring and making confident, inspired choices.
The Trevor Project: What Hope Looks Like
What Hope Looks Like is an AI-guided meditation on hope and resilience. Led by Sol, a calm, reflective AI presence, users are invited into a short conversation that turns their words into living watercolor art, painted in real time by Google’s Imagen model. Built with custom watercolor shaders and particle systems, the experience blurs the line between human emotion and machine expression; culminating in a shared gallery of glowing lanterns, each carrying someone’s personal reflection. Created in support of The Trevor Project, it transforms a moment of introspection into a collective act of hope.
Culture & Team
Forged is intentionally small: a workshop, not a factory. Everyone is a maker. We value taste, precision, and originality over scale.
Our culture runs on rhythm and trust. AI plays a role in nearly everything we do, but never replaces the human hand. We work remotely, but share one philosophy: Everything should feel crafted not manufactured.
The name Forged isn’t metaphorical. It’s our process. We heat, hammer, and shape every idea until it’s perfect.
Are Getters and Setters the correct way to think of abstraction? What are pro and cons of OOP and Procedural programming? And, in the OOP world, how can you define objects?
Table of Contents
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
This is the third part of my series of tips about clean code.
In this article, I’m going to explain how to define classes in order to make your code extensible, more readable and easier to understand. In particular, I’m going to explain how to use effectively Abstraction, what’s the difference between pure OOP and Procedural programming, and how the Law of Demeter can help you structure your code.
The real meaning of abstraction
Some people think that abstraction is nothing but adding Getters and Setters to class properties, in order to (if necessary) manipulate the data before setting or retrieving it:
interfaceIMixer_A{
void SetVolume(intvalue);
int GetVolume();
int GetMaxVolume();
}
classMixer_A : IMixer_A
{
privateconstint MAX_VOLUME = 100;
privateint _volume = 0;
void SetVolume(intvalue) { _volume = value; }
int GetVolume() { return _volume; }
int GetMaxVolume() { return MAX_VOLUME; }
}
This way of structuring the class does not hide the implementation details, because any client that interacts with the Mixer knows that internally it works with integer values. A client should only know about the operations that can be performed on a Mixer.
Let’s see a better definition for an IMixer interface:
With this version, we can perform all the available operations without knowing the internal details of the Mixer. Some advantages?
We can change the internal type for the _volume field, and store it as a ushort or a float, and change the other methods accordingly. And no one else will know it!
We can add more methods, for instance a SetVolumeToPercentage(float percentage) without the risk of affecting the exposed methods
We can perform additional checks and validation before performing the internal operations
It can help you of thinking classes as if they were real objects you can interact: if you have a stereo you won’t set manually the volume inside its circuit, but you’ll press a button that increases the volume and performs all the operations for you. At the same time, the volume value you see on the display is a “human” representation of the internal state, not the real value.
Procedural vs OOP
Object-oriented programming works the best if you expose behaviors so that any client won’t have to access any internal properties.
The focus of procedural programming is to break down a programming task into a collection of variables, data structures, and subroutines, whereas in object-oriented programming it is to break down a programming task into objects that expose behavior (methods) and data (members or attributes) using interfaces. The most important distinction is that while procedural programming uses procedures to operate on data structures, object-oriented programming bundles the two together, so an “object”, which is an instance of a class, operates on its “own” data structure.
To see the difference between OO and Procedural programming, let’s write the same functionality in two different ways. In this simple program, I’m going to generate the <a> tag for content coming from different sources: Twitter and YouTube.
Nice and easy: the classes don’t expose any behavior, but only their properties. So, a client class (I’ll call it LinkCreator) will use their properties to generate the HTML tag.
publicstaticclassLinkCreator{
publicstaticstring CreateAnchorTag(IContent content)
{
switch (content)
{
case Tweet tweet: return$"<a href=\"{tweet.Url}\"> A post by {tweet.Author}</a>";
case YouTubeVideo yt: return$"<a href=\"{yt.Url}\"> A video by {yt.ChannelName}</a>";
default: return"";
}
}
}
We can notice that the Tweet and YouTubeVideo classes are really minimal, so they’re easy to read.
But there are some downsides:
By only looking at the IContent classes, we don’t know what kind of operations the client can perform on them.
If we add a new class that inherits from IContent we must implement the operations that are already in place in every client. If we forget about it, the CreateAnchorTag method will return an empty string.
If we change the type of URL (it becomes a relative URL or an object of type System.Uri) we must update all the methods that reference that field to propagate the change.
❗Procedural or OOP? 1️⃣/2️⃣
With Procedural all the operations are managed by LinkCreator.
PRO: you can add new functions to LinkCreator without affecting the Content subclasses.
If we add a new IContent type, we must implement every method explicitly (or, at least, leave a dummy implementation)
If we expose a new method on IContent, we must implement it in every subclass, even when it’s not required (should I care about the total video duration for a Twitter channel? Of course no).
It’s harder to create easy-to-maintain classes hierarchies
❗Procedural or OOP? 2️⃣/2️⃣
With OOP & polymorphism, each class implements its methods knowing the internal details of itself.
PRO: it’s easy to add new Content classes w/o affecting the siblings
CONS: if you need to expose a new method, you need to add it to all the siblings
— Davide Bellone | Code4it.dev | Microsoft MVP (@BelloneDavide) August 20, 2020
So what?
Luckily we don’t live in a world in black and white, but there are other shades: it’s highly unlikely that you’ll use pure OO programming or pure procedural programming.
So, don’t stick too much to the theory, but use whatever fits best to your project and yourself.
Understand Pro and Cons of each type, and apply them wherever is needed.
Objects vs Data structure – according to Uncle Bob
❓ “Objects hide their data behind abstractions and expose functions that operate on that data. Data structure expose their data and have no meaningful functions”
For me, a data structure (eg: linked list) exposes the operations, not the internals. What do you think?#cleancode
— Davide Bellone | Code4it.dev | Microsoft MVP (@BelloneDavide) August 22, 2020
There’s a statement by the author that is the starting point of all his following considerations:
Objects hide their data behind abstractions and expose functions that operate on that data. Data structure expose their data and have no meaningful functions.
Personally, I disagree with him. For me it’s the opposite: think of a linked list.
A linked list is a data structure consisting of a collection of nodes linked together to form a sequence. You can perform some operations, such as insertBefore, insertAfter, removeBefore and so on. But they expose only the operations, not the internal: you won’t know if internally it is built with an array, a list, or some other structures.
On the contrary, a simple class used just as DTO or as View Model creates objects, not data structures.
classPerson{
public String FirstName { get; set; }
public String LastName { get; set; }
public DateTime BirthDate { get; set; }
}
Regardless of the names, it’s important to know when one type is preferred instead of the other. Ideally, you should not allow the same class to expose both properties and methods, like this one:
— Davide Bellone | Code4it.dev | Microsoft MVP (@BelloneDavide) August 30, 2020
The Law of Demeter is a programming law that says that a module should only talk to its friends, not to strangers. What does it mean?
Say that you have a MyClass class that contains a MyFunction class, which can accept some arguments. The Law of Demeter says that MyFunction should only call the methods of
MyClass itself
a thing created within MyFunction
every thing passed as a parameter to MyFunction
every thing stored within the current instance of MyClass
This is strictly related to the fact that things (objects or data structures – it depends if you agree with the Author’s definitions or not) should not expose their internals, but only the operations on them.
Here’s an example of what not to do:
classLinkedListClient{
ILinkedList linkedList;
publicvoid AddTopic(Node nd){
// do something linkedList.NodesList.Next = nd;
// do something else }
}
What happens if the implementation changes or you find a bug on it? You should update everything. Also, you are coupling too much the two classes.
A problem with this rule is that you should not refer the most common operations on base types too:
Here, the GetCount method is against the Law of Demeter, because it is performing operations on the array type returned by GetList. To solve this problem, you have to add the GetCount() method to the ILinkedList class and call this method on the client.
When it’s a single method, it’s acceptable. What about operations on strings or dates?
Take the Person class. If we exposed the BirthDate properties as a method (something like GetBirthDate), we could do something like
classPersonExample{
void DoSomething(Person person){
var a = person.GetBirthDate().ToString("yyyy-MM-dd");
var b = person.GetBirthDate().AddDays(52);
}
}
which is perfectly reasonable. But it violates the law of Demeter: you can’t perform ToString and AddDays here, because you’re not using only methods exposed by the Person class, but also those exposed by DateTime.
A solution could be to add new methods to the Person class to handle these operations; of course, it would make the class bigger and less readable.
Therefore, I think that this law of Demeter is a good rule of thumb, but you should consider it only as a suggestion and not as a strict rule.
We’ve seen that it’s not so easy to define which behaviors a class should expose. Do we need pure data or objects with a behavior? And how can abstraction help us hiding the internals of a class?
Also, we’ve seen that it’s perfectly fine to not stick to OOP principles strictly, because that’s a way of programming that can’t always be applied to our projects and to our processes.
Three years ago, I began developing a lightweight interpolation library called Interpol, a low-level engine for handling value tweening and smooth motion on the web. You may have already come across it on my social channels, where I’ve shared a few experiments. In this article, I’ll explain the origins of the library and how it’s become a key part of my animation workflow.
Interpol usage examples
Three years ago, I began developing a lightweight interpolation library called @wbe/interpol. Interpol is designed to interpolate sets of values using a GSAP-like API. Its main distinction is that it isn’t a “real” animation library, it’s an interpolation engine.
My observation was that in many projects, I didn’t need all the power of GSAP or anime.js, but just a simple function to interpolate values and import a much lighter library. This is a mechanism that I recreated several times by hand, so I decided to make a library out of it.
Learn modern web animation using GSAP 3 with 34 hands-on video lessons and practical projects — perfect for all skill levels.
Lightweight: the bundle size has to be around 3.5kB
Low-level: for being maintainable and predictable, no magic, no DOM API, only interpolation of values
Performant: Interpol instances should be batched and updated on a single Ticker loop instance
Multiple interpolations: need to interpolate a set of values per instance, not only one
Chaining interpolations: need to create Timelines, with instance offsets
Close to the GSAP and anime.js API: should look like what I’m already used to, in order to not have to adapt myself to a new API
Strongly typed: written in TypeScript with strong types
Optional RAF: Give the possibility to not use the internal requestAnimationFrame. The global update logic should be possible to call manually in a custom loop
Interpolation, what are we talking about?
To summarize, a linear interpolation (called lerp) is a mathematical function that finds a value between two others. It returns an average of the two values depending on a given amount:
function lerp(start: number, end: number, amount: number): number {
return start + (end - start) * amount
}
For now, nothing special. The magic happens when we use it in a loop: The master feature we can exploit from the browser API for creating animations is the requestAnimationFrame function that we call “RAF”. With a strong knowledge of RAF, we can do wonderful things. And with RAF and lerp combined, we can create smoothy-floppy-buttery-coolify-cleanex transitions between two values (yes, all of that).
The most classic usages of lerp in a RAF are the lerp damping and the tweening. Interpol is time-based interpolation engine, so it is a tweening approach. Its time value will be normalized between 0 and 1 and that is what represents the progression of our interpolation.
const loop = (): void => {
const value = lerp(from, to, easing((now - start) / duration))
// Do something with the value...
requestAnimationFrame(loop)
}
requestAnimationFrame(loop)
All this logic is essentially the same as that used by animation libraries like GSAP or anime.js. Many other features are added to those libraries, of course, but this constitutes the core of a tween engine.
Tweening vs Damping
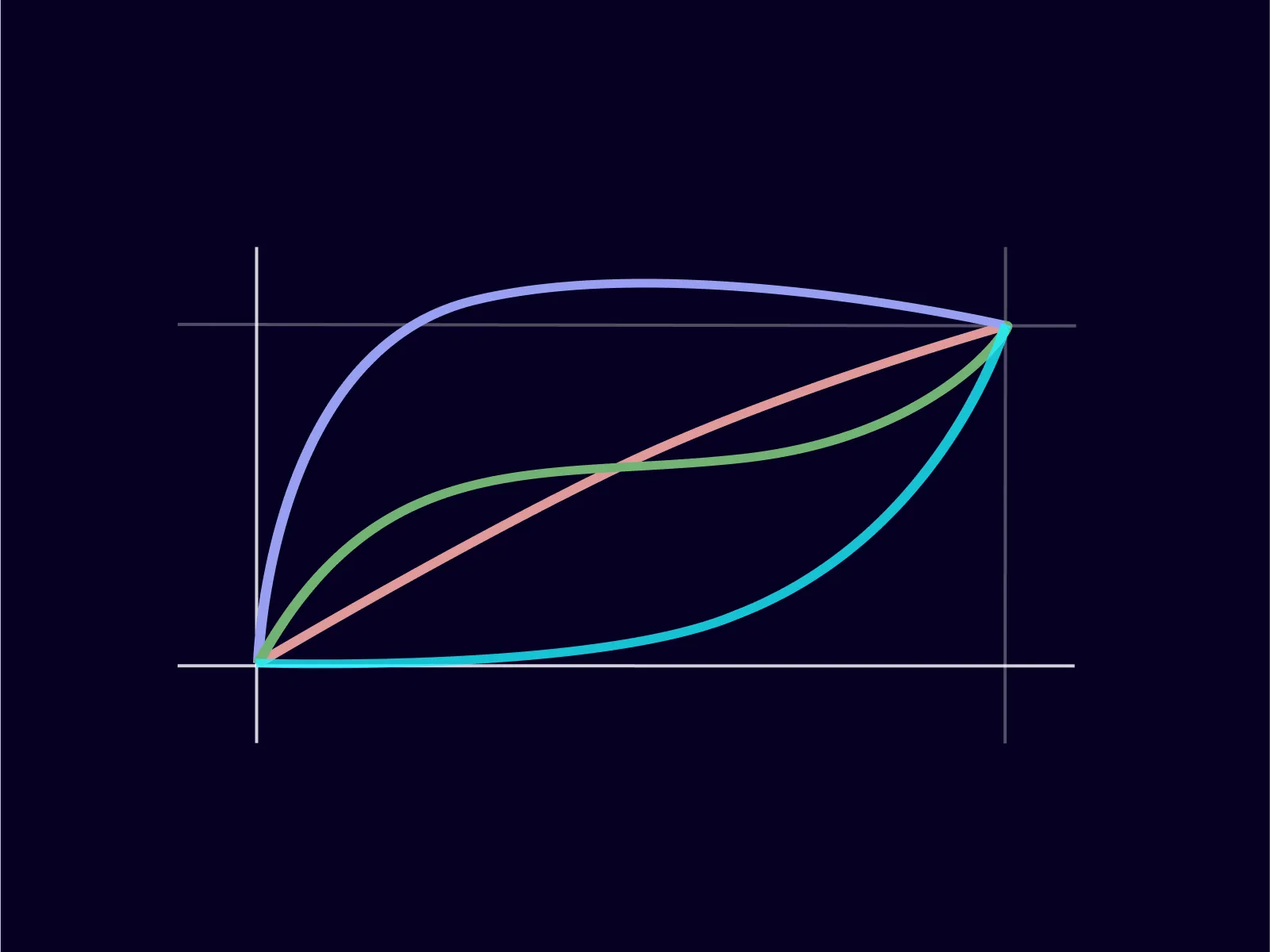
A brief detour on this subject which seems important to me to understand well before going further. Initially, it took me some time to build a mental model of how lerp function works in the context of tweening versus damping. I finally found a way to explain it as in these graphs.
Tweening
With tweening, interpolation is strictly time-bound. When we tween a value over 1000ms, that duration defines an absolute boundary. The animation completes precisely at that moment.
In a second time, we can add an easing function that controls how the value progresses within that fixed window, but the window itself remains constant. Each colored curve represents an interpolation of our value, from 0 to 100, in 1000ms, with a different easing function.
const from = 0
const to = 100
const duration = 1000
const easing =
const progress = easing((now - start) / duration)
// in a tween context
// we update the progress/amount/speed param
✅
const value = lerp(from, to, progress)
Damping
When we talk about “lerp”, we often refer to the “damping lerp” approach. However, this is not how Interpol works, since its interpolations are time-based. With “damped lerp” (or “damping lerp”), there is no concept of time involved. It’s purely frame-based. This technique updates values on each frame, without considering elapsed time. See the graph below for a visual explanation.
let current = 0
let target = 100
let amount = 0.05
// in a damping lerp
// we update the current value on each frame
⬇️ ✅
current = lerp(current, target, amount)
I intentionally renamed the properties passed to the lerp function to make it fit better in the context. Here, it’s better to refer to current and target, since these are values that will be mutated.
To conclude this aside, the lerp function is the basis for several web animation techniques. Lerp can be used on its own, while tweening is a technique dependent on the lerp function. This distinction took me a while to formulate and I felt it was important to share.
That being said, let’s return to Interpol (a tween library if we can say). What does the API for this tool looks like?
Dive inside the API
Interpol constructor
Here is the constructor of an Interpol instance:
import { Interpol } from "@wbe/interpol"
new Interpol({
x: [0, 100],
y: [300, 200],
duration: 1300,
onUpdate: ({ x, y }, time, progress, instance) => {
// Do something with the values...
},
})
First, we define a set of values to interpolate. Keynames can be anything (x, y, foo, bar, etc.). Because we’re not referencing any DOM element, we need to explicitly define “where we start” and “where we want to go”. This is the first main difference with animations libraries that can hold information which comes from the DOM, and implicitly define the from value.
// [from, to] array
x: [0, 100],
// Use an object instead of an array (with optional specific ease)
foo: { from: 50, to: 150, ease: "power3.in" }
// Implicite from is 0, like [0, 200]
bar: 200
// use computed values that can be re-evaluated on demand
baz: [100, () => Math.random() * 500]
In a second step, we define options like the common duration, paused on init, immediateRender & ease function.
// in ms, but can be configured from the global settings
duration: 1300,
// start paused
paused: true,
// Execute onUpdate method once when the instance is created
immediateRender: true
// easing function or typed string 'power3.out' etc.
ease:
Then, we have callbacks that are called at different moments of the interpolation lifecycle. The most important one is onUpdate. This is where the magic happens.
onUpdate: ({ x, y }, time, progress, instance) => {
// Do something with the x and y values
// time is the elapsed time in ms
// progress is the normalized progress between 0 to 1
},
onStart: ({ x, y }, time, progress, instance) => {
// the initial values
},
onComplete: ({ x, y }, time, progress, instance) => {
// done!
}
In terms of developer experience, I feel better merging props, options & callbacks at the same level in the constructor object. It reduces mental overhead when reading an animation, especially in a complex timeline. On the other hand, the web animation API separates keyframes & options ; motion.dev did something similar. It’s probably to stay as close as possible to the native API, which is a smart move too.
It’s just a matter of getting used to it, but it’s also the kind of question that keeps library developers awake at night. Once the API is set, it’s difficult to reverse it. In the case of Interpol, I don’t have this kind of problem, as long as the library remains relatively niche. But for API design issues, and because I like to procrastinate on these kind of details, these are important questions.
Interpol methods
Now, what about methods? I kept the API surface to a minimum and explained below why I did so.
The GUI works thanks to computed properties defined as functions that return new GUI_PARAMS.value values each time you update the x or scale sliders during the animation.
const itp = new Interpol({
x: [0, ()=> GUI_PARAMS.x]
})
// call refresh to recompute all computed values
itp.refresh()
So far there shouldn’t be any surprise if you are used to animation libraries. The best is coming with Timelines.
Timeline & algorithm
Interpolating a set of values is one thing. Building a sequencing engine on top of it is a completely different challenge. The constructor and methods look like what we already know:
import { Timeline } from "@wbe/interpol"
const tl = new Timeline()
// Pass Interpol constructor to the add()
tl.add({
x: [-10, 100],
duration: 750,
ease: t => t * t
onUpdate: ({ x }, time, progress) => {},
})
tl.add({
foo: [100, 50],
bar: [0, 500],
duration: 500,
ease: "power3.out"
onUpdate: ({ foo, bar }, time, progress) => {},
})
// Second possibility: Set a callback function parameter
tl.add(() => {
// Reach this point at 50ms via the absolute offset
}, 50)
tl.play(.3) // start at 30% of the timeline progress, why not?
This API allows us to sequence Interpol instances via add() methods. It’s one of the most challenging part of the library because it requires to maintain an array of Interpol instances internally, with some programmatic properties, like their current position, current progress, duration of the current instance, their possible offset etc.
In the Timeline algorithm, we basically can’t call the play() method of each “add”, It would be a nightmare to control. On the other hand, we have the possibility to calculate a timeline progress (our percent) as long as we know the time position of each of the Interpol instances it holds. This algorithm is based on the fact that a progress lower than 0 or higher than 1 is not animated. In this case, the Interpol instance is not playing at all, but “progressed” lower than 0 or higher than 1.
Take this screen capture: it displays four animated elements in four adds (meaning Interpol instances in the Timeline).
As said before, we calculate a global timeline progress used to modify the progression value of each internal Interpol. All adds are impacted by the global progress, even if it is not yet their turn to be animated. For example, we know that the green square should start its own interpolation at a relative timeline progress .15 (approximately) or 15% of the total timeline, but will be asked to progress since the Timeline is playing.
updateAdds(tlTime: number, tlProgress: number) {
this.adds.forEach((add) => {
// calc a progress between 0 and 1 for each add
add.progress.current = (tlTime - add.time.start) / add.instance.duration
add.instance.progress(add.progress.current)
})
}
tick(delta) {
// calc the timeline time and progress spend from the start
// and update all the interpolations
this.updateAdds(tlTime, tlProgress)
}
It’s then up to each add.interpol.progress() to handle its own logic, to execute its own onUpdate() when needed. Check logs on the same animation: onUpdate is called only during the interpolation, and it’s what we want.
Try it by yourself!
Offsets
Another topic that is of particular interest to me is offsets. In fact, when animating something with a timeline, we always need this functionality. It consists in repositioning a tween, relatively from its natural position or absolutely, in the timeline. All timelines examples below use them in order to superimpose instances. Too many sequential animations feel weird to me.
Technically offsets are about recalculating all adds starts and ends, depending of their own offset.
tl.add({}, 110) // start absolutely at 110ms
tl.add({}, "-=110") // start relatively at -110ms
tl.add({}, "+=110") // start relatively at +110ms
The main difficulty I encountered with this topic was testing. To ensure the offset calculations work correctly, I had to write numerous unit tests. This was far from wasted time, as I still refer to them today to remember how offset calculations should behave in certain edge cases.
Example: What happens if an animation is added with a negative offset and its start is positioned before the timeline’s start? All answers to this kind of questions have been covered in this timeline.offset.test.
it("absolute offset should work with number", () => {
return Promise.all([
// when absolute offset of the second add is 0
/**
0 100 200 300
[- itp1 (100) -]
[ ------- itp2 (200) -------- ]
^
offset start at absolute 0 (number)
^
total duration is 200
*/
testTemplate([[100], [200, 0]], 200),
})
When properly written, tests are my guarantee that my code aligns with my project’s business rules. This is a crucial point for a library’s evolution. I could also say that I’ve learned to protect myself from myself by “fixing” strict rules through tests, which prevent me from breaking everything when trying to add new features. And when you need to cover multiple topics in your API, this allows to breathe.
Make choices & find some workarounds
Back to the “lightweight library” topic, which required me to make several choices: first, by not developing any functionality that I don’t currently need; and second, by filtering out API features that I can already express using existing tools.
For example, there’s no repeat feature in Interpol. But we can simply implement it by calling start in a loop, as long as the method returns a promise:
const repeat = async (n: number): void => {
for (let i = 0; i < n; i++) await itp.play();
};
Another example is about the missing seek method, that allows to move the animation to a specific point via a duration parameter; example: “Move directly to 1,4s of the animation”. I mostly use the same type of method with a streamlined percentage parameter like progress that allows me to move “relatively” across the entire animation, rather than depending on a time factor. But if needed, it remains easy to “seek” with progress as follow:
const duration = 1430 // ms
const itp = new Interpol({
duration,
//...
})
// We want to move the animation at 1000ms
const targetTime = 1000
const percent = targetTime / duration // 0.69...
// progress take a value between 0 and 1
itp.progress(percent)
And about staggers? Again, we can use delay for Interpol, or offsets for Timeline to cover this need.
for (let i = 0; i < elements.length; i++) {
const el = elements[i];
const itp = new Interpol({
// create the stagger with a relative delay
delay: i * 20,
x: [innerWidth / 2, () => random(0, innerWidth)],
y: [innerHeight / 2, () => random(0, innerHeight)],
scale: [0, 5],
onUpdate: ({ x, y, scale, opacity }) => {
el.style.transform = `translate3d(${x}px, ${y}px, 0px) scale(${scale})`
el.style.opacity = `${opacity}`
},
});
}
Similarly, we can easily create our own yoyo function and control what happens on each recursive call. The refresh() method is invoked each time we play the Interpol again to recompute all dynamic values.
And here, an example of what we can achieve by combining these two last technics.
Digging on performance questions
Batching callbacks
The first major optimization for this kind of library is to batch all callback (onUpdate) executions into a single sequential queue. A naive implementation would trigger a separate requestAnimationFrame (RAF) for each instance. Instead, the most performant approach is to externalize and globalize a single RAF, to which all Interpol instances subscribe.
// Global Ticker instance (which contains the unique RAF)
// Used by all Interpol & Timeline instances
const ticker = new Ticker()
class Interpol {
// ...
play() {
ticker.add(this.update)
}
stop() {
this.ticker.remove(this.update)
}
update = () => {
// Do everything you want to do on each frame
}
}
The Ticker instance works like a publish-subscriber pattern, adding and removing callbacks from its own unique RAF. This strategy significantly improves performance, ensuring that all property updates, (whether DOM, GL properties, or others) occur exactly on the same frame.
Batching DOM update
Another important optimization is to batch all DOM writes within the same frame. When multiple elements are updated independently. For example, setting style.transform or style.opacity across different animation instances. Each modification can trigger separate layout and paint operations. By synchronizing all updates through a shared ticker, you ensure that these style changes occur together, minimizing layout thrashing and reducing reflow costs.
This is actually a good example of what Interpol can’t do.
Interpol instances don’t know what happens insider their own onUpdate, unlike a traditional animation library that directly manages DOM targets and can optimize updates globally. On this kind of optimization, Interpol will never be able to compete. It’s part of the “low-level” philosophy of the library. It’s important to keep this in mind.
Stress test
I won’t dive too deep into benchmarks, because in most real-world cases, the difference is barely noticeable in my personal usage. Still, I built a small sandbox to test how different engines behave when animating hundreds of particles on a shared loop. Both GSAP and Interpol stay at a stable 60 FPS in this example with a grid of 6^4 elements. With 7^4, GSAP starts to win. This is purely a stress test because, in a real-world scenario, you wouldn’t build a particle system with DOM elements anyway 🙂
Conclusion
So the final question is: Why use a tool that doesn’t cover every need? And this is a valid question!
Interpol is my personal research project, I use it on my projects even if it’s 50% percent of why I continue to maintain it. The second 50% is that library allows me to ask deep questions about mechanisms, implementation choices, and understand performance issues. It’s a playground that deserves to be explored beyond its simple usefulness and coolness in the world of open-source JS libraries. I will always encourage reinventing the wheel for the purpose of learning and understanding the underlying concepts, this is exactly how I learned to develop.
For sure, I continue to use GSAP and anime.js on many projects for reasons that you know after reading this article. They’re so easy to use, the work is phenomenal.
About me
Because there are humans behind the code, I’m Willy Brauner, senior front-end developer, from Lyon (France). Previously lead front-end developer at Cher-ami, I’m back as a freelancer for almost two years. I Mostly work with agencies on creative projects, building front-end architectures, development workflows, and animations. I write about my research on my journal and publish open-source code on Github. You can reach out to me on Bluesky, Linkedin or email.
MongoDB is a database based on JSON-like documents, but it can be queried using C#. We’ll see how to perform CRUD operations and we’ll create some advanced queries.
Table of Contents
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
MongoDB is one of the most famous document database engine currently available.
A document database is a kind of DB that, instead of storing data in tables, stores them into JSON-like documents. You don’t have a strict format as you would have with SQL databases, where everything is defined in terms of tables and columns; on the contrary, you have text documents that can be expanded as you want without changing all the other documents. You can also have nested information within the same document, for example, the address, info of a user.
Being based on JSON files, you can query the documents using JS-like syntax.
If you want to try MongoDB on your local machine, you can download the Community Editionfrom the project website and install it with a few clicks.
If you’re already used Docker (or if you want to move your first steps with this technology), you can head to my article First steps with Docker: download and run MongoDB locally: in that article, I explained what is Docker, how to install it and how to use it to run MongoDB on your machine without installing the drivers.
Alternatively, if you don’t want to install Mongo on your machine, you can use the cloud version, Mongo Atlas, which offers a free tier (of course with limited resources).
Understanding the structure of a MongoDB database
As we’ve already seen, there are not tables. So how can you organize your data?
The base structure is the document: here you’ll store the JSON structure of your data, with all the nested fields. Documents can be queried by referencing the field names and by applying filters and sorting. On the contrary of real files, documents have no name.
Documents are grouped in collections: they are nothing but a coherent grouping of similar documents; you can think of them as they were folders.
All the collections are stored within a database on which you can apply security rules, perform statistical analysis, and so on.
Finally, of course, all databases will be stored (and exposed) on a host: it’s the endpoint reachable to perform queries. You can structure your hosts to replicate data to split the load between different nodes.
For this article, since I’m going to run MongoDB using Docker, you’ll see that my host is on localhost:27888 (again, to see how I set up the port, have a look at my other article).
Of course, you can use different applications to navigate and interact with MongoDB databases. In this article, I’m going to use MongoDB Compass Community, a tool provided directly by MongoDB.
In the image below you can see the host-database-collection-document structure as displayed by MongoDB Compass.
I’ve created a simple API project with .NET Core 3.1.
To use the C# driver you must install some NuGet packages: MongoDB.Driver, MongoDB.Driver.Core and MongoDB.Bson.
The class we’re going to use is called Game, and has a simple definition:
It’s a POCO class with a few fields. Let’s focus on 3 interesting aspects of this class:
First of all, the Id field is of type ObjectId. This is the default object used by MongoDB to store IDs within its documents.
Second, the id field name is Id: MongoDriver requires that, if not specified, the document entity Id must match with a property of type ObjectId and whose name is Id. If you choose another name or another type for that field you will get this exception:
FormatException: Element ‘_id’ does not match any field or property of class BoardGameAPI.Models.Game.
If you want to use another name for your C# property, you can decorate that field with the BsonId attribute (we’ll see it later).
The last thing to notice is the Name property: do you see the BsonElement attribute? You can use that attribute to map a C# field to a specific property within the document that has a different name. If you look at the screenshot above, you’ll notice the title field: that field will be mapped to the Name property.
Accessing to the DB and the collection
Since this is an API application, we can handle CRUD operations in a Controller. So, in our BoardGameController, we can initialize the connection to the DB and get the reference to the right collection.
privatereadonly MongoClient client;
privatereadonly IMongoDatabase db;
privatereadonly IMongoCollection<Game> dbCollection;
public BoardGameController()
{
client = new MongoClient("mongodb://mongoadmin:secret@localhost:27888/boardgamesdb?authSource=admin");
db = client.GetDatabase("boardgamesdb");
dbCollection = db.GetCollection<Game>("boardgames");
}
Let’s analyze each step:
Initialize a client
The very first step is to create a connection to the DB. The simplest MongoClient constructor requires a connection string to the MongoDB instance. A connection string is made of several parts: protocol, username, password, db host, port, db name and other attributes.
var client = new MongoClient("mongodb://mongoadmin:secret@localhost:27888/boardgamesdb?authSource=admin")
The MongoClient class allows you to perform some operations on the databases stored on that host, like listing their names with ListDatabaseNames and ListDatabaseNamesAsync, or drop one of those DBs with DropDatabase and DropDatabaseAsync.
Behind the scenes, a MongoClient represents a connection pool to the database. As long as you use the same connection string, you can create new MongoClient objects that will still refer to the same connection pool. This means that you can create as many MongoClient instances to the same connection pool without affecting the overall performance.
Connect to the DB
Using the newly created Mongo Client, it’s time to get a reference to the database we’re going to use.
IMongoDatabase db = client.GetDatabase("boardgamesdb");
What if the boardgamesdb does not exist? Well, this method creates it for you and stores the reference in the db variable.
Just like with MongoClient, you can perform operations on the level below; in this case, you operate on collections with methods like ListCollectionNames, GetCollection, CreateCollection, and DropCollection.
Get the reference to the collection
Finally, since we must operate on documents within a collection, we need a reference to that specific collection (or create it if it does not exist)
So now we have an object that maps to all the documents in the boardgames collections to our Game class.
Once we have that collection, we can perform all the queries we want.
Insert operation
If we want to retrieve some data, we have to insert some first. It’s incredibly simple:
[HttpPost]publicasync Task<ActionResult> Add([FromBody] Game newGame)
{
dbCollection.InsertOne(newGame);
return Ok();
}
The Game object comes from the body of my HTTP POST request and gets stored directly in the MongoDB document.
Notice that even though I haven’t defined the ID field in the request, it is autogenerated by MongoDB. So, where does that _id field come from?
How to manage IDs: ObjectId and custom Id
Do you remember how we’ve defined the ID in the Game class?
public ObjectId Id { get; set; }
So, in Mongo, that ObjectId field gets stored in a field called _id with this internal structure:
"_id": {
"$oid": "5f8490cf9c1f367f604e751b"}
What if we wanted to use a custom ID instead of an ObjectId?
First of all, we can remove the Id field as defined before and replace it with whatever we want:
- public ObjectId Id { get; set; }
+ public string AnotherId { get; set; }
And now, for the key point: since Mongo requires to store the Id in the _id field, we must specify which field of our class must be used as an Id. To do that, we must decorate our chosen field with a [BsonId] attribute.
+ [BsonId]
public string AnotherId { get; set; }
So, after all these updates, our Game class will have this form:
publicclassGame{
/** NOTE: if you want to try the native Id handling, uncomment the line below and comment the AnotherId field*/// public ObjectId Id { get; set; } [BsonId]publicstring AnotherId { get; set; }
[BsonElement("title")]publicstring Name { get; set; }
publicint AverageMinutesDuration { get; set; }
publicint MinNumberOfPlayers { get; set; }
publicint MaxNumberOfPlayers { get; set; }
}
Of course, we must update also the Insert operation to generate a new Id. In this case, I chose the use the date of the insertion:
Remember to choose wisely how do you want to store your ID, since if you decide to change your format while your application is already in place, you’ll have trouble to handle both the ID format or to switch from one format to another.
For this article, I’ll stay with our custom Id, since it’s easier to manage. Of course, I have to drop the collection and add new coherent data.
Get
Get all items
To find an item you have to use the Find and FindAsync methods.
The key point is the filter parameter: it is a Filter in the format required by Mongo, which is strictly linked to the Game class, as you can see with var filter = Builders<Game>.Filter. So, in general, to filter for a specific class, you have to define a filter of the related type.
To get all the items, you must define an empty filter. Yes, not a null value, but an empty filter.
What does FindAsync return? The returned type is Task<IAsyncCursor<Game>>, and that means that, once you’ve await-ed it, you can list all the Games by transforming it into a list or by fetching each element using the Current and the MoveNext (or the MoveNextAsync) methods.
A quick note: the ToList method is not the one coming from LINQ, but it’s defined as an extension method for IAsyncCursor.
Get by ID
Most of the time you might want to get only the element with a given Id.
The code is incredibly similar to our GetAll method, except for the definition of a different filter. While in the GetAll we used an empty filter, here we need to create a new filter to specify which field must match a specific condition.
[HttpGet][Route("{id}")]publicasync Task<ActionResult> GetById(string id)
{
var filter = Builders<Game>.Filter;
var eqFilter = filter.Eq(x => x.AnotherId, id);
var game = await dbCollection.FindAsync<Game>(eqFilter).ConfigureAwait(false);
return Ok(game.FirstOrDefault());
}
Here we are receiving an ID from the route path and we are creating an equality filter on the AnotherId field, using filter.Eq(x => x.AnotherId, id).
This is possible because the id variable type matches with the AnotherId field type, since both are strings.
What if we were still in the old version, with the ObjectId type for our IDs?
[HttpGet]
[Route("{id}")]
public async Task<ActionResult> GetById(string id)
{
var filter = Builders<Game>.Filter;
- var eqFilter = filter.Eq(x => x.AnotherId, id);
+ var eqFilter = filter.Eq(x => x.Id, new ObjectId(id));
var game = await dbCollection.FindAsync<Game>(eqFilter).ConfigureAwait(false);
return Ok(game.FirstOrDefault());
}
See, they’re almost identical: the only difference is that now we’re wrapping our id variable within an ObjectId object, which will then be used as a filter by MongoDB.
Get with complex filters
Now I’m interested only in games I can play with 3 friends, so all the games whose minimum number of players is less than 4 and whose max number of players is greater than 4.
To achieve this result we can rely on other kinds of filters, that can also be nested.
First of all, we’ll use Lte to specify a less than or equal filter; then we’ll use Gte to create a greater than or equal filter.
Finally, we’ll join them in an and condition with the And method.
[HttpGet][Route("byplayers/{players}")]publicasync Task<ActionResult> GetByName(int players)
{
var filter = Builders<Game>.Filter;
var minNumberFilter = filter.Lte(x => x.MinNumberOfPlayers, players);
var maxNumberFilter = filter.Gte(x => x.MaxNumberOfPlayers, players);
var finalFilter = filter.And(minNumberFilter, maxNumberFilter);
var game = await dbCollection.FindAsync<Game>(finalFilter).ConfigureAwait(false);
return Ok(game.ToList());
}
If we peek into the definition of the And method, we see this:
public FilterDefinition<TDocument> And(IEnumerable<FilterDefinition<TDocument>> filters);
public FilterDefinition<TDocument> And(params FilterDefinition<TDocument>[] filters);
This means that we can add as many filters we want in the And clause, and we can even create them dynamically by adding them to an IEnumerable of FilterDefinition object.
Of course, the same applies to the Or clause.
Update
Now, it’s time to update an existing field. To keep the example simple, I chose to update only the game name given its Id.
Here we are creating a new object that will build our Update operation, the UpdateDefinitionBuilder<Game>, and creating the rule to apply in order to update the record.
It’s important to see the clear separation of concerns: with one builder, you define which items must be updated, while with the second one you define how those items must be updated.
We are now performing the update operation on the first item that matches the rules defined by the eqFilterDefinition filter. You can of course create a more complex filter definition by using the other constructs that we’ve already discussed.
The returned value is an UpdateResult object, which contains a few fields that describe the status of the operation. Among them, we can see MatchedCount and ModifiedCount.
As usual, to find the items to be deleted we must create the correct FilterDefinition. Then we can execute the DeleteOneAsync method to delete the first one, and finally check how many items have been deleted by accessing the properties exposed by the DeleteResult object.
Conclusion
We’ve seen how to perform some simple operations with C# and MongoDB by creating filters on the collections and performing actions on them.
For most of the methods I used here actually there are different versions to allow both synchronous and asynchronous operations, and to perform operations both on a single and on multiple items. An example is the update operation: depending on your necessities, you can perform UpdateOne, UpdateOneAsync, UpdateMany, UpdateManyAsync.
If you want to have a broader knowledge of how you can use C# to perform operations on MongoDB, you can refer to this MongoDB C# driver cheat sheet which is very complete, but not updated. This article uses operations that now are outdated, like Query<Product>.EQ(p => p.Item, "pen") that has been updated to Builders<Game>.Filter.Eq(p => p.Item, "pen"). By the way, even if that article was published in 2014, it’s still a great resource.
If you prefer a deeper and up-to-date resource, the best thing is to head to the official documentation where you can find lots of examples each with a short explanation.
As usual, you can find the repository I used for this example on GitHub.
Real-time search results power everything from SEO dashboards and product research tools to AI experiments. But collecting that data yourself is messy — scraping, captchas, rotating proxies, and constant HTML changes.
That’s exactly the problem SerpApi, the web Search API set out to solve. It gives developers structured, real-time search data from Google and over 40 other platforms — with a single, consistent API call.
Before diving into code, let’s take a quick look at what makes scraping search engines so frustrating and why it’s worth doing right.
Learn modern web animation using GSAP 3 with 34 hands-on video lessons and practical projects — perfect for all skill levels.
Try scraping Google once, and you’ll quickly see why most people give up. Even good scrapers fail after a few days because search results change constantly and every layer of protection fights automation.
HTML changes all the time: A small update in Google’s structure can break your parser overnight.
Anti-bot walls: Captchas, IP bans, and bot detection require proxies, rotations, and hours of maintenance.
Location matters: The same keyword can show completely different results depending on your region and language.
JavaScript rendering: Modern SERPs — Maps, AI answers, Shopping — load data dynamically inside a browser.
SerpApi handles all of that automatically. Each request runs in a real browser, uses geo-targeted proxies, solves captchas, and returns structured JSON you can plug straight into your code.
What Makes Search Data Worth It
Despite the hassle, search data is gold. It shows what people care about, what products lead the market, and how information surfaces online. With a reliable source like SerpApi, it becomes an instant data feed you can use anywhere.
Web Search API: Automate SERP data collection for SEO tracking, analytics dashboards, and research projects — no captchas or parsing required.
Example: Monitor keyword rankings, featured snippets, and competitor visibility across multiple regions in real time.
AI SearchEngine API: Analyze or visualize how large language models shape Google’s AI Overviews to inform AI analytics and model training.
Example: Build dashboards comparing AI-generated summaries against traditional search listings in real time.
AI SEO (GEO): Use geo-targeted search data to understand how AI answers and SERPs vary by location, device, or language — ideal for localized SEO campaigns.
Example: Measure AI-generated visibility and ranking performance across global markets and devices.
Product Research API: Compare live pricing, reviews, and availability from Amazon and other marketplaces to uncover trends and market gaps.
Example: Identify trending products, compare sellers, and monitor real-time shifts in e-commerce data.
Maps API: Find and filter local businesses from Google Maps with ratings, categories, and contact info for lead generation and local analytics.
Example: Build regional lead lists or power location-based dashboards with verified business data.
AI Training & Data Analytics: Feed structured, real-world search data into models, dashboards, or experiments to enhance machine learning accuracy and insight generation.
Example: Train AI systems or data pipelines with fresh, labeled search and market data.
These use cases show how structured, real-time search data moves far beyond raw scraping, becoming a foundation for analytics, automation, and AI-driven insights across industries.
Next, we’ll look at how this works in practice. We’ll start with the Google Search API, the simplest way to fetch full search results, complete with titles, links, snippets, and rich elements, all in structured JSON.
Google Search API
The Google Search API is SerpApi’s flagship endpoint. It lets you fetch complete Google Search results — including organic listings, featured snippets, images, ads, knowledge graphs, and local packs — in real time.
You can access it from any programming language that supports HTTP requests (e.g., Python, JavaScript, Ruby, Go, or even cURL), since it’s just a standard API call that returns structured JSON. SerpApi also supports no-code tools such as n8n and Make.com, as well as integration with Google Sheets.
Each request follows the same simple pattern. You just need to change the engine parameter to switch between API endpoints, such as engine=google for Google Search or engine=google_ai_mode for Google AI Mode.
You can even send the GET request directly in your browser for quick testing:
Check out more details on how to integrate with Python in this guide.
Response Example
The organic_results field contains the main list of standard Google Search results. Each entry includes structured data such as title, link, snippet, and position, plus optional fields like thumbnails, ratings, and rich snippets.
"organic_results": [
{
"position": 1,
"title": "Best Laptops 2025 - Top Picks and Reviews",
"link": "https://example.com/best-laptops-2025",
"displayed_link": "https://example.com › best-laptops-2025",
"snippet": "Discover the top laptops of 2025, featuring models from Apple, Dell, and Lenovo...",
"sitelinks": {
"inline": [
{ "title": "Apple MacBook Air M3", "link": "https://example.com/apple-macbook-air-m3" },
{ "title": "Dell XPS 13", "link": "https://example.com/dell-xps-13" }
]
}
}
]
This structured output makes it easy to integrate SerpApi into any stack or workflow — from a quick prototype to a large-scale SEO tool or research platform.
💡 Pro Tip: You can use additional parameters like hl (language), gl (country), or start (pagination) to fine-tune your queries and replicate real Google Search behavior precisely.
Common use cases are: rank tracking, SEO monitoring, keyword research, and competitive analysis.
Google’s new AI Mode introduces an experimental search experience powered by large language models — generating summarized, conversational answers above traditional search results.
SerpApi’s Google AI Mode API captures this AI-powered view, returning the generated summaries, text blocks, references, and any inline media in clean JSON format — ready for integration into your own apps or dashboards.
As mentioned before, you can access it from any programming language that supports HTTP requests using the engine=google_ai_mode parameter.
Example in Python
from serpapi import GoogleSearch
params = {
"engine": "google_ai_mode",
"q": "how does solar power work",
"api_key": "YOUR_API_KEY"
}
search = GoogleSearch(params)
results = search.get_dict()
for block in results.get("text_blocks", []):
print(block.get("snippet"))
Response Example
The response includes AI-generated content as structured text blocks, along with supporting references and media. Each text block represents part of Google’s AI-generated summary — a paragraph, heading, list, table, or even embedded code.
{
"text_blocks": [
{
"type": "paragraph",
"snippet": "Solar power works by converting sunlight into electricity using photovoltaic cells, which are typically made from silicon."
},
{
"type": "heading",
"snippet": "Key Components"
},
{
"type": "list",
"list": [
{ "snippet": "Solar panels: capture sunlight and generate direct current (DC)." },
{ "snippet": "Inverter: converts DC into usable alternating current (AC)." },
{ "snippet": "Battery storage: saves excess energy for later use." }
]
}
],
"references": [
{
"title": "How Solar Energy Works - U.S. Department of Energy",
"link": "https://www.energy.gov/solar/how-solar-energy-works",
"source": "energy.gov"
}
]
}
This structured JSON lets developers extract and visualize Google’s AI-generated search summaries, compare them against traditional SERP results, or analyze how AI-mode answers evolve across topics.
Common use cases:
Comparing AI-generated summaries vs. classic search results
Monitoring how Google’s AI cites or links to sources
Building dashboards or trend analysis tools around AI search behavior
Studying how AI overviews structure content by topic
💡 Pro Tip: You can combine google_ai_mode results with classic google or google_news results to track how AI responses evolve alongside traditional organic search visibility.
The Google Maps API from SerpApi lets you extract live business listings, ratings, reviews, and location data directly from Google Maps — all returned as structured JSON you can query or visualize instantly.
This is especially useful for local SEO monitoring, lead generation, competitor research, or building location-based apps without needing to maintain complex scraping infrastructure.
The API replicates any Maps search you’d perform manually — like “coffee near me” — and returns business details such as name, address, rating, hours, and coordinates.
Example in Python
from serpapi import GoogleSearch
params = {
"engine": "google_maps",
"q": "coffee",
"ll": "@40.7455096,-74.0083012,14z", # New York City
"type": "search",
"api_key": "YOUR_API_KEY"
}
search = GoogleSearch(params)
results = search.get_dict()
for shop in results.get("local_results", []):
print(f"{shop['position']}. {shop['title']} – {shop.get('rating', 'N/A')}⭐")
Response Example
The API returns a local_results array containing detailed business data from Google Maps.
Each result includes the business’s name, category, rating, total reviews, hours, address, phone, and coordinates, along with structured subfields for operating hours, service options, order links, and photos.
Common Parameters
Parameter
Description
q
Search query (e.g. "pizza", "coffee in Paris")
ll
Latitude, longitude, and zoom (e.g. @40.7455096,-74.0083012,14z)
type
Set to "search" for listings or "place" for a specific business
hl
Language (e.g. en, es, fr)
gl
Country code (e.g. us, uk, ca)
api_key
Your SerpApi key
Use Cases
Local SEO tracking: Monitor top businesses for target keywords in specific cities or zip codes.
Lead generation: Collect names, phone numbers, and websites of local businesses automatically.
Market intelligence: Compare ratings and review counts for competitors.
Mapping & visualization: Combine gps_coordinates data with GIS or mapping tools.
💡 Pro Tip: Results may vary slightly depending on map zoom (z value) and Google’s local ranking logic. For more structured business details like reviews or photos, you can combine this with the Google Maps Reviews API or Photos API.
The Amazon Search API lets you fetch structured product data directly from Amazon’s search results — including titles, prices, ratings, delivery info, and seller details.
Instead of parsing HTML manually, SerpApi returns everything in clean JSON, so you can focus on analyzing data rather than maintaining scrapers. It’s ideal for price comparison tools, market research, competitive intelligence, or e-commerce analytics.
The organic_results array contains structured product listings from Amazon’s search results. Each item includes key details like title, price, rating, and thumbnail.
This structured format makes it easy to compare prices, extract product data, or monitor competitors at scale.
Use Cases
Price comparison – Track product pricing across time or categories
Market research – Analyze competitor offerings or discover emerging brands
E-commerce analytics – Monitor best sellers and review trends
Product catalog enrichment – Automatically collect product info for listings
💡 Pro Tip: You can refine results using additional parameters such as page, amazon_domain (e.g., amazon.co.uk), or sort (price-asc-rank, price-desc-rank, review-rank, etc.) to target specific regions or sorting orders.
You can explore these APIs in action using SerpApi’s interactive Playground, where you can test queries and instantly see structured JSON results.
Demo
Description
Example Query
Google Search API
Live search → JSON results
best laptops 2025
Google AI Mode API
Capture AI Overview output
how does solar power work
Google Maps API
Extract local business data
coffee shops in Austin
Amazon Search API
Product pricing data
wireless headphones
Conclusion
Scraping search data doesn’t need to be complicated, unreliable, or risky. With SerpApi, you can access structured, real-time results from Google, Amazon, Maps, and dozens of other engines — all with a single, consistent API call.
Whether you’re building SEO tools, analyzing markets, or powering AI systems, SerpApi gives you accurate data from real browser sessions, at scale, and without the hassle.
How to effectively ping an endpoint in C#? Don’t use the HttpClient, when .NET provides a Ping class to perform all these operations.
Table of Contents
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
How would you know if a remote endpoint is up and running? When you use the command line, you can run the ping command and see the result, like this:
❯ ping code4it.dev
Pinging code4it.dev [165.22.65.139] with 32 bytes of data:
Reply from 165.22.65.139: bytes=32 time=17ms TTL=51
Reply from 165.22.65.139: bytes=32 time=20ms TTL=51
Reply from 165.22.65.139: bytes=32 time=15ms TTL=51
Reply from 165.22.65.139: bytes=32 time=16ms TTL=51
Ping statistics for 165.22.65.139:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 15ms, Maximum = 20ms, Average = 17ms
But what if you need to fetch that result programmatically with C#?
HttpClient – a bad idea
The first approach you can think of is to send an HTTP request to that endpoint and to see if you receive some response.
privatestaticasync Task<bool> PingWithHttpClient()
{
string hostUrl = "https://www.code4it.dev/";
var httpClient = new HttpClient();
HttpRequestMessage request = new HttpRequestMessage
{
RequestUri = new Uri(hostUrl),
Method = HttpMethod.Head
};
var result = await httpClient.SendAsync(request);
return result.IsSuccessStatusCode;
}
Notice that I don’t request the whole content, but I perform a HEAD operation to get only the response headers. To know more about this HTTP method, check out the MDN documentation.
So, what can we say about this snippet of code? Does it work? Yes. Is it the best choice? No. Why?
There are at least 2 cases that will show you why you shouldn’t use it.
What if the whole site is under authentication? Well, the site would be actually reachable, but since we are not including authentication headers or cookies, the IsSuccessStatusCode will return false. You can try it by setting https://httpstat.us/401 as hostUrl.
Also, let’s think about Web APIs. Usually, the root does not represent a valid endpoint. So, you will get a 404 instead of the expected response even if the system is working correctly.
Ping class: a better idea
The best and simples way to perform ping operations is relying on the Ping class on the System.Net.NetworkInformation namespace. This class allows you to ping an endpoint and to check all the values that you usually get when you run this command on the command line.
privatestaticasync Task<bool> PingAsync()
{
var hostUrl = "www.code4it.dev";
Ping ping = new Ping();
PingReply result = await ping.SendPingAsync(hostUrl);
return result.Status == IPStatus.Success;
}
Yes, that’s as simple as it appears! But let’s have a look at each line.
var hostUrl = "www.code4it.dev";
Here I’m defining which host must be checked. As you already do with the command line, you have to exclude both the protocol (http and https) and every following path and query string.
Simply, we are creating a new Ping object. No parameters in the constructor, no overloads. Easy-peasy.
PingReply result = await ping.SendPingAsync(hostUrl);
Here I’m performing the ping operation in the simplest way, by specifying only the destination host.
Some other overloads allow you, for instance, to specify a timeout (in milliseconds) for the request.
Once you retrieve the PingReply object you can get some useful info:
public IPAddress Address { get; }
publicbyte[] Buffer { get; }
public PingOptions Options { get; }
publiclong RoundtripTime { get; }
public IPStatus Status { get; }
With the Address field, you can perform lots of operations, like mapping that IP address to an IPv4 or IPv6 address and get some advanced properties, like the AddressFamily. Or, simply, you might want to print the IP value, and you can do it with a simple ToString.
Of course, you can also get the RTT (round-trip time) expressed in milliseconds.
The last thing to check is the actual status.
return result.Status == IPStatus.Success;
IPStatus is an enum with lots of different values. Among them, we can find
We’ve seen how to ping an endpoint asynchronously. What if we need the synchronous way?
Well, there is also this possibility, but with a method called Send. I won’t repeat the example, it’s almost identical to the one we’ve already seen.
I just want to point out that the library has a small discrepancy in the names for the methods.
The asynchronous method that we’ve used before is called SendPingAsync, but the synchronous method is called Send. Where is the SendPing method? It doesn’t exist. And what about SendAsync? Well, it actually exists, but it requires different parameters and, even worse, it returns null instead of a PingReply object.
Bonus tip: how to get the Hostname for a URL
As I said, to perform a ping request you need to use only the hostname, and remove all the other parts of the URL, like the protocol, the query string and so on.
If you don’t pass the correct value to the SendPingAsync method, you will get a System.Net.NetworkInformation.PingException exception with the message No such host is known.
How can you get only the hostname? You could parse the string, extract only the parts that you need using a regex or something similar. Or you can simply transform your URL into a System.Uri object and extract the host property.
var fullUrl = new Uri("https://www.code4it.dev/blog/openapi-code-generation-vs2019");
var host = fullUrl.Host; // www.code4it.dev
Easy, right?
Wrapping up
In my experience, I’ve rarely seen this way to ping an endpoint. In most of the projects I’ve worked on, we used the HttpClient way. But it was only because we didn’t know of the existence of this class.
Also, remember that you can’t run the ping command on Azure App Service. If you are interested, have a look at this article where I explain why and how you can perform a similar operation.