TLDR: Need to see how your site or app works on Android without buying a phone? Fire up a free online Android emulator at browserling.com/android. The emulator runs right in your browser – no downloads, no installs, no setup.
What’s an Online Android Emulator?
An Android emulator is like a “phone inside your computer”. It runs on a server in the cloud, and you control it through your browser. You can tap, swipe, and test apps or websites exactly like you would on a real phone.
Is It Safe to Use?
Yep! The emulator runs remotely, so anything you test stays contained. You don’t risk messing up your computer or your personal phone. Even if an app has bugs or hidden malware, it can’t escape the emulator.
Can I Test My Mobile Website?
Absolutely. Just load your site inside the emulator and see how it looks on an Android device. You’ll notice if text is too small, buttons don’t line up, or if your layout breaks on different screen sizes.
What About Cross-Browser Testing?
You can use the emulator to try your site in Chrome for Android, Firefox for Android, and other mobile browsers. It’s super handy for web developers who need to make sure their site works everywhere, not just on desktop.
Can I Use It for App Testing?
Yes! You can install APK files and see how your app behaves. This helps developers and testers find bugs before shipping updates to real users. It’s also great for QA teams who need to check features across different Android versions.
Do I Need to Download Anything?
Nope. Just open the browserling.com/android in your browser. It works with HTML5, JavaScript, and WebSockets to stream the Android screen to you. No software, no setup, no stress.
Does It Work on Any Computer?
Yep. Since everything runs in your browser, you can use it on Windows, Mac, Linux, or even a Chromebook. No need for special hardware or software.
Can I Share My Test Sessions?
Totally. You can grab screenshots or record short clips right from the emulator. This makes it easy to share bugs with your team or show clients how their site looks on Android.
Can I Try Different Android Versions?
Totally. You can switch between Android versions and devices to see how your app or site looks on older and newer phones. This is useful for compatibility testing and catching weird bugs that only show up on certain systems.
Is It Free?
There’s a free Android emulator version with limited time. If you need longer sessions, more devices, or advanced features, there are paid plans available. The paid plans are built for developers, QA teams, and anyone doing serious testing.
What Is Browserling?
Browserling is a free online Android emulator and browser testing platform. It lets you run Android phones and web browsers straight from the cloud, right inside your browser. No downloads, no setup, no extra devices. Developers use it to test websites, QA teams use it to check mobile apps, and everyday users try it out to see how things look on Android without needing an actual phone.
Who Uses Browserling?
Web developers, mobile app testers, QA teams, and even governments use Browserling’s emulators. Big companies trust it for cross-device testing. It’s super handy if you’d rather test in the cloud than keep an Android lab on your desk.
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
One of the most common issues we face when developing applications is handling dates, times, and time zones.
Let’s say that we need the date for January 1st, 2020, exactly 30 minutes after midnight. We would be tempted to do something like:
var plainDate = new DateTime(2020, 1, 1, 0, 30, 0);
It makes sense. And plainDate.ToString() returns 2020/1/1 0:30:00, which is correct.
But, as I explained in a previous article, while ToString does not care about time zone, when you use ToUniversalTime and ToLocalTime, the results differ, according to your time zone.
Let’s use a real example. Please, note that I live in UTC+1, so pay attention to what happens to the hour!
var plainDate = new DateTime(2020, 1, 1, 0, 30, 0);
Console.WriteLine(plainDate); // 2020-01-01 00:30:00Console.WriteLine(plainDate.ToUniversalTime()); // 2019-12-31 23:30:00Console.WriteLine(plainDate.ToLocalTime()); // 2020-01-01 01:30:00
This means that ToUniversalTime considers plainDate as Local, so, in my case, it subtracts 1 hour.
On the contrary, ToLocalTime considers plainDate as UTC, so it adds one hour.
So what to do?
Always specify the DateTimeKind parameter when creating DateTimes__. This helps the application understanding which kind of date is it managing.
var specificDate = new DateTime(2020, 1, 1, 0, 30, 0, DateTimeKind.Utc);
Console.WriteLine(specificDate); //2020-01-01 00:30:00Console.WriteLine(specificDate.ToUniversalTime()); //2020-01-01 00:30:00Console.WriteLine(specificDate.ToLocalTime()); //2020-01-01 00:30:00
As you see, it’s always the same date.
Ah, right! DateTimeKind has only 3 possible values:
publicenum DateTimeKind
{
Unspecified,
Utc,
Local
}
So, my suggestion is to always specify the DateTimeKind parameter when creating a new DateTime.
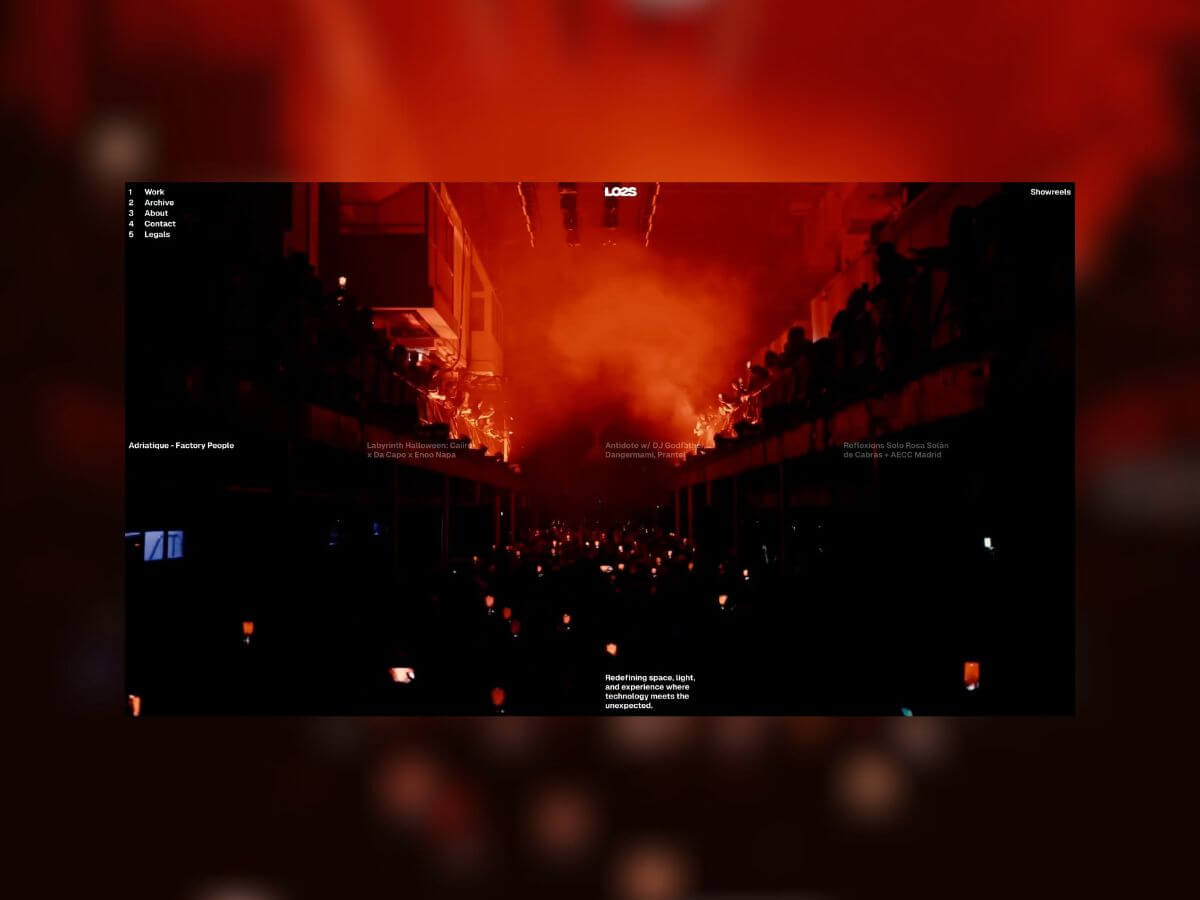
LO2S approached SNP & DashDigital with the ambition to build a website that didn’t just present their services but embodied their fast-paced, movement-driven ethos. They wanted users to feel the energy of their work as they navigated the site. For us, this meant leaning into full-screen video, fluid transitions, and interactive motion as core building blocks. The challenge wasn’t just visual polish, it was making sure these elements stayed performant and seamless under the hood.
Technologies and Tools
We built the site on a fairly standard stack — Next.js (Page Router), GSAP, Strapi, AWS, CloudFront, with one key addition: OGL.
Why OGL?
It’s lightweight compared to three.js.
It gives maximum rendering control.
It’s ideal when you don’t need heavy model support (GLTF/OBJ/FBX).
This was our first time implementing OGL in production. The LO2S site didn’t need complex 3D assets, so OGL was a natural choice for performant, interactive visuals without extra overhead.
Key Features
Immersive Landing Experience A full-screen video serves as the entry point, with a four-grid hover navigation exposing featured projects. This setup made it simple for users to dive directly into the work while keeping the landing visually impactful.
Dual Work Views The Work page offers two ways to explore:
A list view for quick navigation.
A dynamic card layout, where projects animate forward and off-screen. It creates a browsing rhythm that feels closer to a cinematic sequence than a typical index page.
Infinite 3D Gallery with Blur We implemented an infinite gallery using transform3d and vanilla JS instead of WebGL. This kept the build light, while still supporting background blur. Blur often raises performance red flags, but careful optimisation keeps the effect stable across devices.
Interactive Logo Shader We built a custom shader (inspired by Studio 27b) to make the logo feel aligned to the brand essence. On hover, characters shift and blend, creating a sense of connection reminiscent of light patterns at live events.
Technical Refinement Our first text distortion tests looked jagged. We solved this with a custom aastep function for programmatic antialiasing. It analyses texture gradients and smooths pixel transitions, ensuring the typography scales cleanly and looks sharp even under distortion.
Visual & Interactive Elements
Some of the smaller but critical pieces that shaped the experience:
Page transitions tied to the logo for continuity.
Distortion shader applied to text for responsive motion.
Dynamic content modules that adapt layouts in real time.
Animated preloader to set the tone from first load.
Architecture and Structure
Fast content delivery was a non-negotiable requirement. We tackled it in two ways:
CDN Delivery: Media is served via AWS CloudFront, with Strapi configured to push assets to an S3 bucket automatically.
Video optimisation: We provided the client with bash ffmpeg scripts to batch-optimise video files, balancing quality with load speed.
Reflection & Learnings
Every build is an opportunity to refine our process and build strategy. For LO2S, we initially relied on Strapi’s Sharp integration for image cropping, which raised two pain points:
Uploading raw 4K images slowed the pipeline and occasionally failed.
Sharp auto-generated multiple image sizes, many of which were unnecessary.
After the project, we tested imgproxy and found it better suited to our needs:
Works seamlessly with CDNs and caching.
Isolates processing from the main app.
Lets you configure image formats per use case.
Delivered 620+ requests/sec with ~12.8ms latency in benchmarks.
For us, that’s the direction forward, a cleaner, faster, and more reliable image workflow.
You should not add the caching logic in the same component used for retrieving data from external sources: you’d better use the Decorator Pattern. We’ll see how to use it, what benefits it brings to your application, and how to use Scrutor to add it to your .NET projects.
Table of Contents
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
When fetching external resources – like performing a GET on some remote APIs – you often need to cache the result. Even a simple caching mechanism can boost the performance of your application: the fewer actual calls to the external system, the faster the response time of the overall application.
We should not add the caching layer directly to the classes that get the data we want to cache, because it will make our code less extensible and testable. On the contrary, we might want to decorate those classes with a specific caching layer.
In this article, we will see how we can use the Decorator Pattern to add a cache layer to our repositories (external APIs, database access, or whatever else) by using Scrutor, a NuGet package that allows you to decorate services.
Before understanding what is the Decorator Pattern and how we can use it to add a cache layer, let me explain the context of our simple application.
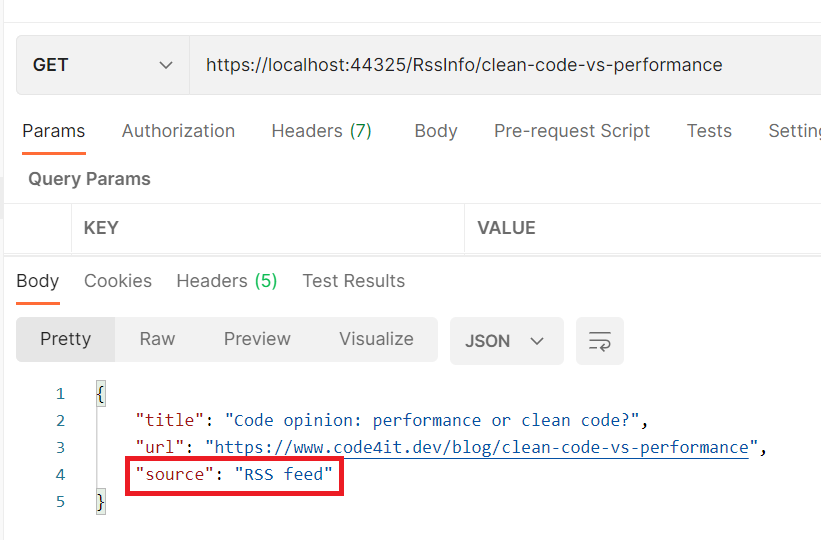
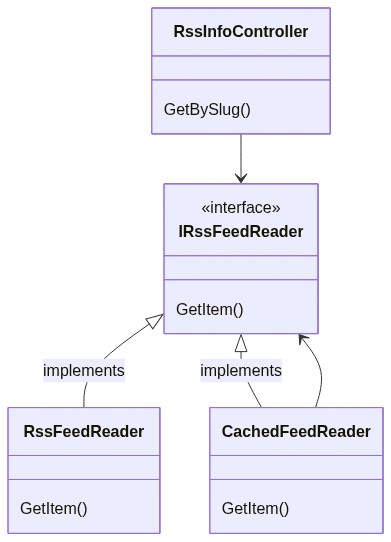
We are exposing an API with only a single endpoint, GetBySlug, which returns some data about the RSS item with the specified slug if present on my blog.
That interface is implemented by the RssFeedReader class, which uses the SyndicationFeed class (that comes from the System.ServiceModel.Syndication namespace) to get the correct item from my RSS feed:
publicclassRssFeedReader : IRssFeedReader
{
public RssItem GetItem(string slug)
{
var url = "https://www.code4it.dev/rss.xml";
using var reader = XmlReader.Create(url);
var feed = SyndicationFeed.Load(reader);
SyndicationItem item = feed.Items.FirstOrDefault(item => item.Id.EndsWith(slug));
if (item == null)
returnnull;
returnnew RssItem
{
Title = item.Title.Text,
Url = item.Links.First().Uri.AbsoluteUri,
Source = "RSS feed" };
}
}
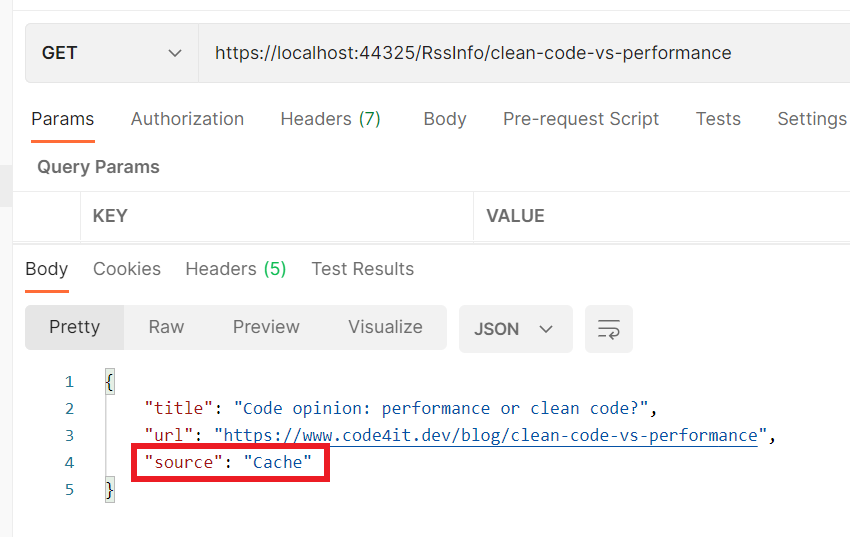
When we run the application and try to find an article I published, we retrieve the data directly from the RSS feed (as you can see from the value of Source).
The application is quite easy, right?
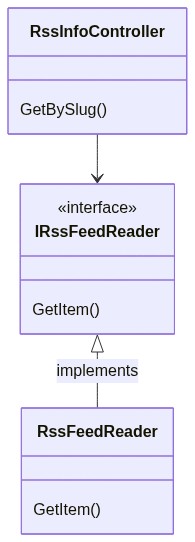
Let’s translate it into a simple diagram:
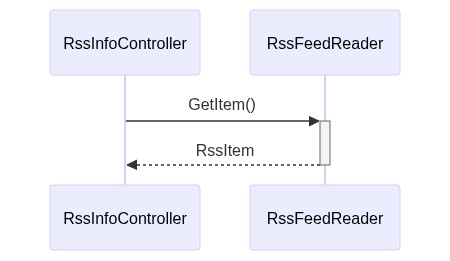
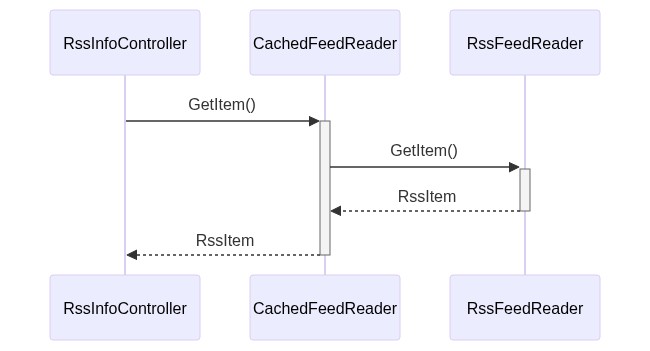
The sequence diagram is simple as well- it’s almost obvious!
Now it’s time to see what is the Decorator pattern, and how we can apply it to our situation.
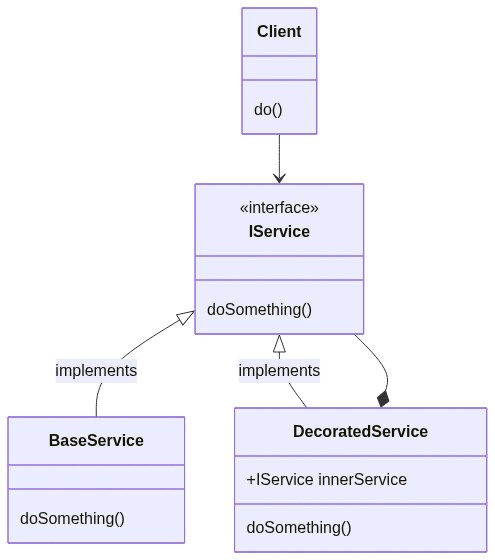
Introducing the Decorator pattern
The Decorator pattern is a design pattern that allows you to add behavior to a class at runtime, without modifying that class. Since the caller works with interfaces and ignores the type of the concrete class, it’s easy to “trick” it into believing it is using the simple class: all we have to do is to add a new class that implements the expected interface, make it call the original class, and add new functionalities to that.
Quite confusing, uh?
To make it easier to understand, I’ll show you a simplified version of the pattern:
In short, the Client needs to use an IService. Instead of passing a BaseService to it (as usual, via Dependency Injection), we pass the Client an instance of DecoratedService (which implements IService as well). DecoratedService contains a reference to another IService (this time, the actual type is BaseService), and calls it to perform the doSomething operation. But DecoratedService not only calls IService.doSomething(), but enriches its behavior with new capabilities (like caching, logging, and so on).
In this way, our services are focused on a single aspect (Single Responsibility Principle) and can be extended with new functionalities (Open-close Principle).
Enough theory! There are plenty of online resources about the Decorator pattern, so now let’s see how the pattern can help us adding a cache layer.
Ah, I forgot to mention that the original pattern defines another object between IService and DecoratedService, but it’s useless for the purpose of this article, so we are fine anyway.
Implementing the Decorator with Scrutor
Have you noticed that we almost have all our pieces already in place?
If we compare the Decorator pattern objects with our application’s classes can notice that:
Client corresponds to our RssInfoController controller: it’s the one that calls our services
IService corresponds to IRssFeedReader: it’s the interface consumed by the Client
BaseService corresponds to RssFeedReader: it’s the class that implements the operations from its interface, and that we want to decorate.
So, we need a class that decorates RssFeedReader. Let’s call it CachedFeedReader: it checks if the searched item has already been processed, and, if not, calls the decorated class to perform the base operation.
There are a few points you have to notice in the previous snippet:
this class implements the IRssFeedReader interface;
we are passing an instance of IRssFeedReader in the constructor, which is the class that we are decorating;
we are performing other operations both before and after calling the base operation (so, calling _rssFeedReader.GetItem(slug));
we are setting the value of the Source property to Cache if the object is already in cache – its value is RSS feed the first time we retrieve this item;
Open your project and install it via UI or using the command line by running dotnet add package Scrutor.
Now head to the ConfigureServices method and use the Decorate extension method to decorate a specific interface with a new service:
services.AddSingleton<IRssFeedReader, RssFeedReader>(); // this one was already presentservices.Decorate<IRssFeedReader, CachedFeedReader>(); // add a new decorator to IRssFeedReader
… and that’s it! You don’t have to update any other classes; everything is transparent for the clients.
If we run the application again, we can see that the first call to the endpoint returns the data from the RSS Feed, and all the followings return data from the cache.
We can now update our class diagram to add the new CachedFeedReader class
And, of course, the sequence diagram changed a bit too.
Benefits of the Decorator pattern
Using the Decorator pattern brings many benefits.
Every component is focused on only one thing: we are separating responsibilities across different components so that every single component does only one thing and does it well. RssFeedReader fetches RSS data, CachedFeedReader defines caching mechanisms.
Every component is easily testable: we can test our caching strategy by mocking the IRssFeedReader dependency, without the worrying of the concrete classes called by the RssFeedReader class. On the contrary, if we put cache and RSS fetching functionalities in the RssFeedReader class, we would have many troubles testing our caching strategies, since we cannot mock the XmlReader.Create and SyndicationFeed.Load methods.
We can easily add new decorators: say that we want to log the duration of every call. Instead of putting the logging in the RssFeedReader class or in the CachedFeedReader class, we can simply create a new class that implements IRssFeedReader and add it to the list of decorators.
An example of Decorator outside the programming world? The following video from YouTube, where you can see that each cup (component) has only one responsibility, and can be easily decorated with many other cups.
In this article, we’ve seen that the Decorator pattern allows us to write better code by focusing each component on a single task and by making them easy to compose and extend.
We’ve done it thanks to Scrutor, a NuGet package that allows you to decorate services with just a simple configuration.
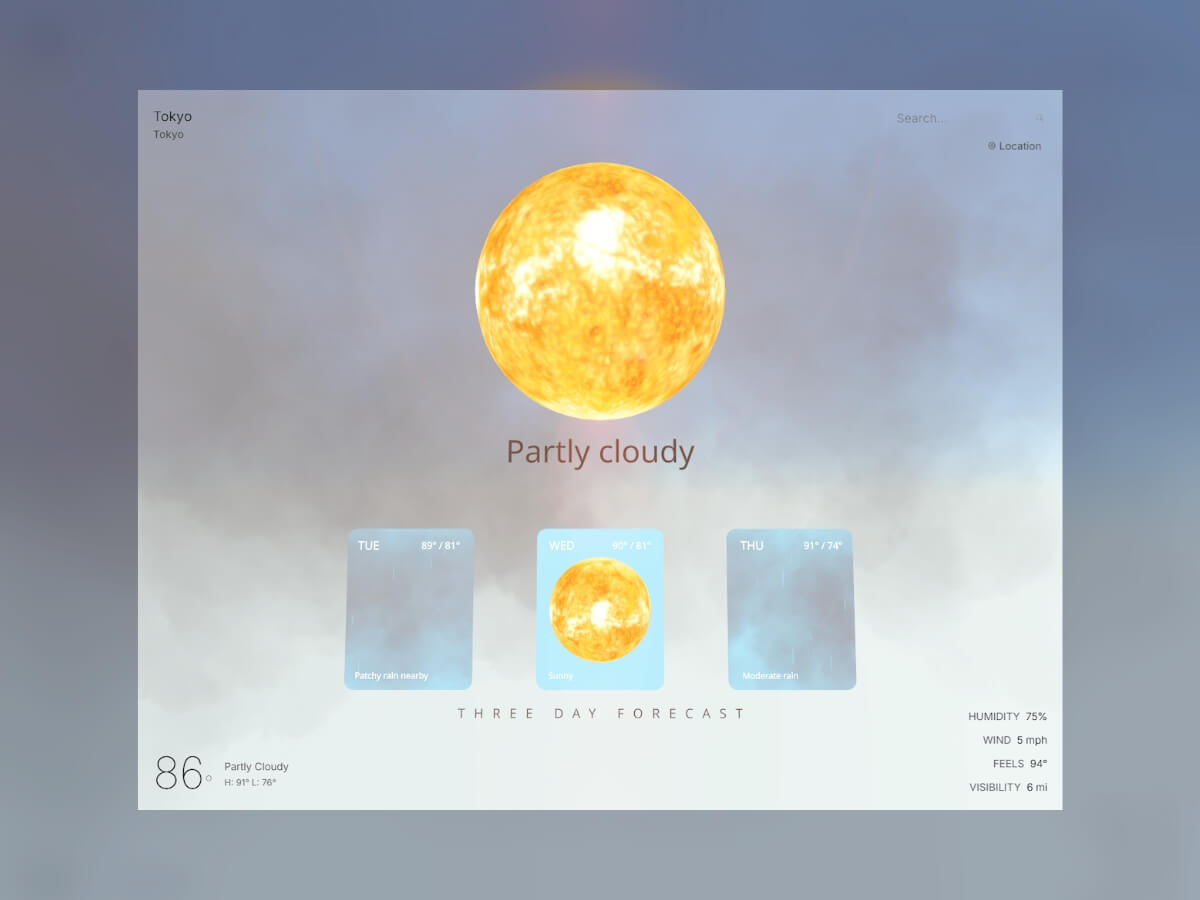
I’ve always been interested in data visualization using Three.js / R3F, and I thought a weather web app would be the perfect place to start. One of my favorite open-source libraries, @react-three/drei, already has a bunch of great tools like clouds, sky, and stars that fit perfectly into visualizing the weather in 3D.
This tutorial explores how to transform API data into a 3D experience, where we add a little flair and fun to weather visualization.
The Technology Stack
Our weather world is built on a foundation of some of my favorite technologies:
Weather Components
The heart of our visualization lies in conditionally showing a realistic sun, moon, and/or clouds based on the weather
results from your city or a city you search for, particles that simulate rain or snow, day/night logic, and some fun
lighting effects during a thunderstorm. We’ll start by building these weather components and then move on to displaying
them based on the results of the WeatherAPI call.
Sun + Moon Implementation
Let’s start simple: we’ll create a sun and moon component that’s just a sphere with a realistic texture wrapped
around it. We’ll also give it a little rotation and some lighting.
// Sun.js and Moon.js Component, a texture wrapped sphere
import React, { useRef } from 'react';
import { useFrame, useLoader } from '@react-three/fiber';
import { Sphere } from '@react-three/drei';
import * as THREE from 'three';
const Sun = () => {
const sunRef = useRef();
const sunTexture = useLoader(THREE.TextureLoader, '/textures/sun_2k.jpg');
useFrame((state) => {
if (sunRef.current) {
sunRef.current.rotation.y = state.clock.getElapsedTime() * 0.1;
}
});
const sunMaterial = new THREE.MeshBasicMaterial({
map: sunTexture,
});
return (
<group position={[0, 4.5, 0]}>
<Sphere ref={sunRef} args={[2, 32, 32]} material={sunMaterial} />
{/* Sun lighting */}
<pointLight position={[0, 0, 0]} intensity={2.5} color="#FFD700" distance={25} />
</group>
);
};
export default Sun;
I grabbed the CC0 texture from here. The moon component is essentially the same; I used this image. The pointLight intensity is low because most of our lighting will come from the sky.
Rain: Instanced Cylinders
Next, let’s create a rain particle effect. To keep things performant, we’re going to use instancedMesh instead of creating a separate mesh component for each rain particle. We’ll render a single geometry (<cylinderGeometry>) multiple times with different transformations (position, rotation, scale). Also, instead of creating a new THREE.Object3D for each particle in every frame, we’ll reuse a single dummy object. This saves memory and prevents the overhead of creating and garbage-collecting a large number of temporary objects within the animation loop. We’ll also use the useMemo hook to create and initialize the particles array only once when the component mounts.
When a particle reaches a negative Y-axis level, it’s immediately recycled to the top of the scene with a new random horizontal position, creating the illusion of continuous rainfall without constantly creating new objects.
Snow: Physics-Based Tumbling
We’ll use the same basic template for the snow effect, but instead of the particles falling straight down, we’ll give them some drift.
The horizontal drift uses Math.sin(state.clock.elapsedTime + i), where state.clock.elapsedTime provides a continuously increasing time value and i offsets each particle’s timing. This creates a natural swaying motion in which each snowflake follows its own path. The rotation updates apply small increments to both the X and Y axes, creating the tumbling effect.
Storm System: Multi-Component Weather Events
When a storm rolls in, I wanted to simulate dark, brooding clouds and flashes of lightning. This effect requires combining multiple weather effects simultaneously. We’ll import our rain component, add some clouds, and implement a lightning effect with a pointLight that simulates flashes of lightning coming from inside the clouds.
The lightning system uses a simple ref-based cooldown mechanism to prevent constant flashing. When lightning triggers, it creates a single bright flash with random positioning. The system uses setTimeout to reset the light intensity after 400ms, creating a realistic lightning effect without complex multi-stage sequences.
Clouds: Drei Cloud
For weather types like cloudy, partly cloudy, overcast, foggy, rainy, snowy, and misty, we’ll pull in our clouds component. I wanted the storm component to have its own clouds because storms should have darker clouds than the conditions above. The clouds component will simply display Drei clouds, and we’ll pull it all together with the sun or moon component in the next section.
Now that we’ve built our weather components, we need a system to decide which ones to display based on real weather data. The WeatherAPI.com service provides detailed current conditions that we’ll transform into our 3D scene parameters. The API gives us condition text like “Partly cloudy,” “Thunderstorm,” or “Light snow,” but we need to convert these into our component types.
// weatherService.js - Fetching real weather data
const response = await axios.get(
`${WEATHER_API_BASE}/forecast.json?key=${API_KEY}&q=${location}&days=3&aqi=no&alerts=no&tz=${Intl.DateTimeFormat().resolvedOptions().timeZone}`,
{ timeout: 10000 }
);
The API request includes time zone information so we can accurately determine day or night for our Sun/Moon system. The days=3 parameter grabs forecast data for our portal feature, while aqi=no&alerts=no keeps the payload lean by excluding data we don’t need.
Converting API Conditions to Component Types
The heart of our system is a simple parsing function that maps hundreds of possible weather descriptions to our manageable set of visual components:
// weatherService.js - Converting weather text to renderable types
export const getWeatherConditionType = (condition) => {
const conditionLower = condition.toLowerCase();
if (conditionLower.includes('sunny') || conditionLower.includes('clear')) {
return 'sunny';
}
if (conditionLower.includes('thunder') || conditionLower.includes('storm')) {
return 'stormy';
}
if (conditionLower.includes('cloud') || conditionLower.includes('overcast')) {
return 'cloudy';
}
if (conditionLower.includes('rain') || conditionLower.includes('drizzle')) {
return 'rainy';
}
if (conditionLower.includes('snow') || conditionLower.includes('blizzard')) {
return 'snowy';
}
// ... additional fog and mist conditions
return 'cloudy';
};
This string-matching approach handles edge cases gracefully—whether the API returns “Light rain,” “Heavy rain,” or “Patchy light drizzle,” they all map to our rainy type and trigger the appropriate 3D effects. This way, we can reuse our main components without needing a separate component for each weather condition.
Conditional Component Rendering
The magic happens in our WeatherVisualization component, where the parsed weather type determines exactly which 3D components to render:
// WeatherVisualization.js - Bringing weather data to life
const renderWeatherEffect = () => {
if (weatherType === 'sunny') {
if (partlyCloudy) {
return (
<>
{isNight ? <Moon /> : <Sun />}
<Clouds intensity={0.5} speed={0.1} />
</>
);
}
return isNight ? <Moon /> : <Sun />;
} else if (weatherType === 'rainy') {
return (
<>
<Clouds intensity={0.8} speed={0.15} />
<Rain count={800} />
</>
);
} else if (weatherType === 'stormy') {
return <Storm />; // Includes its own clouds, rain, and lightning
}
// ... additional weather types
};
This conditional system ensures we only load the particle systems we actually need. A sunny day renders just our Sun component, while a storm loads our complete Storm system with heavy rain, dark clouds, and lightning effects. Each weather type gets its own combination of the components we built earlier, creating distinct visual experiences that match the real weather conditions.
Dynamic Time-of-Day System
Weather isn’t just about conditions—it’s also about timing. Our weather components need to know whether to show the sun or moon, and we need to configure Drei’s Sky component to render the appropriate atmospheric colors for the current time of day. Fortunately, our WeatherAPI response already includes the local time for any location, so we can extract that to drive our day/night logic.
The API provides local time in a simple format that we can parse to determine the current period:
// Scene3D.js - Parsing time from weather API data
const getTimeOfDay = () => {
if (!weatherData?.location?.localtime) return 'day';
const localTime = weatherData.location.localtime;
const currentHour = new Date(localTime).getHours();
if (currentHour >= 19 || currentHour <= 6) return 'night';
if (currentHour >= 6 && currentHour < 8) return 'dawn';
if (currentHour >= 17 && currentHour < 19) return 'dusk';
return 'day';
};
This gives us four distinct time periods, each with different lighting and sky configurations. Now we can use these periods to configure Drei’s Sky component, which handles atmospheric scattering and generates realistic sky colors.
Dynamic Sky Configuration
Drei’s Sky component is fantastic because it simulates actual atmospheric physics—we just need to adjust atmospheric parameters for each time period:
// Scene3D.js - Time-responsive Sky configuration
{timeOfDay !== 'night' && (
<Sky
sunPosition={(() => {
if (timeOfDay === 'dawn') {
return [100, -5, 100]; // Sun below horizon for darker dawn colors
} else if (timeOfDay === 'dusk') {
return [-100, -5, 100]; // Sun below horizon for sunset colors
} else { // day
return [100, 20, 100]; // High sun position for bright daylight
}
})()}
inclination={(() => {
if (timeOfDay === 'dawn' || timeOfDay === 'dusk') {
return 0.6; // Medium inclination for transitional periods
} else { // day
return 0.9; // High inclination for clear daytime sky
}
})()}
turbidity={(() => {
if (timeOfDay === 'dawn' || timeOfDay === 'dusk') {
return 8; // Higher turbidity creates warm sunrise/sunset colors
} else { // day
return 2; // Lower turbidity for clear blue sky
}
})()}
/>
)}
The magic happens in the positioning. During dawn and dusk, we place the sun just below the horizon (-5 Y position) so Drei’s Sky component generates those warm orange and pink colors we associate with sunrise and sunset. The turbidity parameter controls atmospheric scattering, with higher values creating more dramatic color effects during transitional periods.
Nighttime: Simple Black Background + Stars
For nighttime, I made a deliberate choice to skip Drei’s Sky component entirely and use a simple black background instead. The Sky component can be computationally expensive, and for nighttime scenes, a pure black backdrop actually looks better and performs significantly faster. We complement this with Drei’s Stars component for that authentic nighttime atmosphere:
Drei’s Stars component creates 5,000 individual stars scattered across a 100-unit sphere with realistic depth variation. The saturation={0} keeps them properly desaturated for authentic nighttime visibility, while the gentle speed={1} creates subtle movement that simulates the natural motion of celestial bodies. Stars only appear during nighttime hours (7 PM to 6 AM) and automatically disappear at dawn, creating a smooth transition back to Drei’s daytime Sky component.
This approach gives us four distinct atmospheric moods—bright daylight, warm dawn colors, golden dusk tones, and star-filled nights—all driven automatically by the real local time from our weather data.
Forecast Portals: Windows Into Tomorrow’s Weather
Like any good weather app, we don’t want to just show current conditions but also what’s coming next. Our API returns a three-day forecast that we transform into three interactive portals hovering in the 3D scene, each one showing a preview of that day’s weather conditions. Click on a portal and you’re transported into that day’s atmospheric environment.
Building Portals with MeshPortalMaterial
The portals use Drei’s MeshPortalMaterial, which renders a complete 3D scene to a texture that gets mapped onto a plane. Each portal becomes a window into its own weather world:
The roundedPlaneGeometry from the maath library gives our portals those smooth, organic edges instead of sharp rectangles. The [2, 2.5, 0.15] parameters create a 2×2.5 unit portal with 0.15 radius corners, providing enough rounding to look visually appealing.
Interactive States and Animations
Portals respond to user interaction with smooth state transitions. The system tracks two primary states: inactive and fullscreen:
// ForecastPortals.js - State management and blend animations
const ForecastPortal = ({ position, dayData, isActive, isFullscreen, onEnter }) => {
const materialRef = useRef();
useFrame(() => {
if (materialRef.current) {
// Smooth blend animation - only inactive (0) or fullscreen (1)
const targetBlend = isFullscreen ? 1 : 0;
materialRef.current.blend = THREE.MathUtils.lerp(
materialRef.current.blend || 0,
targetBlend,
0.1
);
}
});
// Portal content and UI elements hidden in fullscreen mode
return (
<group position={position}>
<mesh onClick={onEnter}>
<roundedPlaneGeometry args={[2, 2.5, 0.15]} />
<MeshPortalMaterial ref={materialRef}>
<PortalScene />
</MeshPortalMaterial>
</mesh>
{!isFullscreen && (
<>
{/* Temperature and condition text only show in preview mode */}
<Text position={[-0.8, 1.0, 0.1]} fontSize={0.18} color="#FFFFFF">
{formatDay(dayData.date, index)}
</Text>
</>
)}
</group>
);
};
The blend property controls how much the portal takes over your view. At 0 (inactive), you see the portal as a framed window into the weather scene. At 1 (fullscreen), you’re completely transported inside that day’s weather environment. The THREE.MathUtils.lerp function creates smooth transitions between these two states when clicking in and out of portals.
Fullscreen Portal Experience
When you click a portal, it fills your entire view with that day’s weather. Instead of looking at tomorrow’s weather through a window, you’re standing inside it:
In fullscreen mode, the portal weather data drives the entire scene: the Sky component, lighting, and all weather effects now represent that forecasted day. You can orbit around inside tomorrow’s storm or bask in the gentle sunlight of the day after. When you exit (click outside the portal), the system smoothly transitions back to the current weather conditions.
The key insight is that each portal runs our same WeatherVisualization component but with forecast data instead of current conditions. The portalMode={true} prop optimizes the components for smaller render targets—fewer particles, simpler clouds, but the same conditional logic we built earlier.
Now that we’ve introduced portals, we need to update our weather components to support this optimization. Going back to our conditional rendering examples, we add the portalMode prop:
And our Clouds component is updated to render fewer, simpler clouds in portal mode:
// Clouds.js - Portal optimization
const Clouds = ({ intensity = 0.7, speed = 0.1, portalMode = false }) => {
if (portalMode) {
return (
<DreiClouds material={THREE.MeshLambertMaterial}>
{/* Only 2 centered clouds for portal preview */}
<Cloud segments={40} bounds={[8, 3, 3]} volume={8} position={[0, 4, -2]} />
<Cloud segments={35} bounds={[6, 2.5, 2.5]} volume={6} position={[2, 3, -3]} />
</DreiClouds>
);
}
// Full cloud system for main scene (6+ detailed clouds)
return <group>{/* ... full cloud configuration ... */}</group>;
};
This dramatically reduces both particle counts (87.5% fewer rain particles) and cloud complexity (a 67% reduction from 6 detailed clouds to 2 centered clouds), ensuring smooth performance when multiple portals show weather effects simultaneously.
Integration with Scene3D
The portals are positioned and managed in our main Scene3D component, where they complement the current weather visualization:
// Scene3D.js - Portal integration
<>
{/* Current weather in the main scene */}
<WeatherVisualization
weatherData={weatherData}
isLoading={isLoading}
/>
{/* Three-day forecast portals */}
<ForecastPortals
weatherData={weatherData}
isLoading={isLoading}
onPortalStateChange={handlePortalStateChange}
/>
</>
When you click a portal, the entire scene transitions to fullscreen mode, showing that day’s weather in complete detail. The portal system tracks active states and handles smooth transitions between preview and immersive modes, creating a seamless way to explore future weather conditions alongside the current atmospheric environment.
The portals transform static forecast numbers into explorable 3D environments. Instead of reading “Tomorrow: 75°, Partly Cloudy,” you see and feel the gentle drift of cumulus clouds with warm sunlight filtering through.
Adding Cinematic Lens Flares
Our Sun component looks great, but to really make it feel cinematic, I wanted to implement a subtle lens flare effect. For this, I’m using the R3F-Ultimate-Lens-Flare library (shoutout to Anderson Mancini), which I installed manually by following the repository’s instructions. While lens flares typically work best with distant sun objects rather than our close-up approach, I still think it adds a nice cinematic touch to the scene.
The lens flare system needs to be smart about when to appear. Just like our weather components, it should only show when it makes meteorological sense:
The key parameters create a realistic lens flare effect: glareSize and flareSize both at 1.68 give prominent but not overwhelming flares, while ghostScale={0.03} adds subtle lens reflection artifacts. The haloScale={3.88} creates that large atmospheric glow around the sun.
The lens flare connects to our weather system through a visibility function that determines when the sun should be visible:
// weatherService.js - When should we show lens flares?
export const shouldShowSun = (weatherData) => {
if (!weatherData?.current?.condition) return true;
const condition = weatherData.current.condition.text.toLowerCase();
// Hide lens flare when weather obscures the sun
if (condition.includes('overcast') ||
condition.includes('rain') ||
condition.includes('storm') ||
condition.includes('snow')) {
return false;
}
return true; // Show for clear, sunny, partly cloudy conditions
};
// Scene3D.js - Combining weather and time conditions
const showLensFlare = useMemo(() => {
if (isNight || !weatherData) return false;
return shouldShowSun(weatherData);
}, [isNight, weatherData]);
This creates realistic behavior where lens flares only appear during daytime clear weather. During storms, the sun (and its lens flare) is hidden by clouds, just like in real life.
Performance Optimizations
Since we’re rendering thousands of particles, multiple cloud systems, and interactive portals—sometimes simultaneously—it can get expensive. As mentioned above, all our particle systems use instanced rendering to draw thousands of raindrops or snowflakes in single GPU calls. Conditional rendering ensures we only load the weather effects we actually need: no rain particles during sunny weather, no lens flares during storms. However, there’s still a lot of room for optimization. The most significant improvement comes from our portal system’s adaptive rendering. We already discussed decreasing the number of clouds in portals above, but when multiple forecast portals show precipitation simultaneously, we dramatically reduce particle counts.
This prevents the less-than-ideal scenario of rendering 4 × 800 = 3,200 rain particles when all portals show rain. Instead, we get 800 + (3 × 100) = 1,100 total particles while maintaining the visual effect.
API Reliability and Caching
Beyond 3D performance, we need the app to work reliably even when the weather API is slow, down, or rate-limited. The system implements smart caching and graceful degradation to keep the experience smooth.
Intelligent Caching
Rather than hitting the API for every request, we cache weather responses for 10 minutes:
This gives users instant responses for recently searched locations and keeps the app responsive during API slowdowns.
Rate Limiting and Fallback
When users exceed our 15 requests per hour limit, the system smoothly switches to demo data instead of showing errors:
// weatherService.js - Graceful degradation
if (error.response?.status === 429) {
console.log('Too many requests');
return getDemoWeatherData(location);
}
The demo data includes time-aware day/night detection, so even the fallback experience shows proper lighting and sky colors based on the user’s local time.
Future Enhancements
There’s plenty of room to expand this weather world. Adding accurate moon phases would bring another layer of realism to nighttime scenes—right now our moon is perpetually full. Wind effects could animate vegetation or create drifting fog patterns, using the wind speed data we’re already fetching but not yet visualizing. Performance-wise, the current optimizations handle most scenarios well, but there’s still room for improvement, especially when all forecast portals show precipitation simultaneously.
Conclusion
Building this 3D weather visualization combined React Three Fiber with real-time meteorological data to create something beyond a traditional weather app. By leveraging Drei’s ready-made components alongside custom particle systems, we’ve transformed API responses into explorable atmospheric environments.
The technical foundation combines several key approaches:
Instanced rendering for particle systems that maintain 60fps while simulating thousands of raindrops
Conditional component loading that only renders the weather effects currently needed
Portal-based scene composition using MeshPortalMaterial for forecast previews
Time-aware atmospheric rendering with Drei’s Sky component responding to local sunrise and sunset
Smart caching and fallback systems that keep the experience responsive during API limitations
This was something I always wanted to build, and I had a ton of fun bringing it to life!
Smaller functions help us write better code, but have also a nice side effect: they help us to understand where an exception was thrown. Let’s see how!
Table of Contents
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
Small functions not only improve your code readability but also help to debug faster your applications in case of unhandled exceptions.
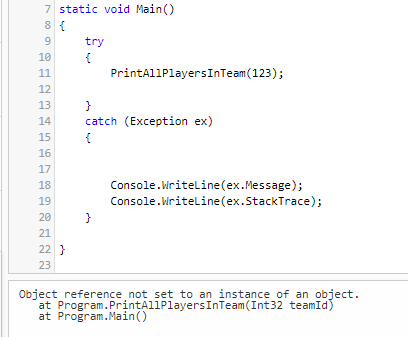
Take as an example the program listed below: what would happen if a NullReferenceException is thrown? Would you be able to easily understand which statement caused that exception?
With one, single, huge function, we lose the context of our exception. The catch block intercepts an error that occurred in the PrintAllPlayersInTeam function. But where? Maybe in teamFeed.Content.ToLower(), or maybe in player.FirstName.ToLower().
Even the exception’s details won’t help!
Object reference not set to an instance of an object.
at Program.PrintAllPlayersInTeam(Int32 teamId)
at Program.Main()
Yes, it says that the error occurred in the PrintAllPlayersInTeam. But where, exactly? Not a clue!
By putting all together inside a single function, PrintAllPlayersInTeam, we are losing the context of our exceptions.
So, a good idea is to split the method into smaller, well-scoped methods:
Of course, this is not a perfect code, but it give you the idea!.
As you can see, I’ve split the PrintAllPlayersInTeam method into smaller ones.
If now we run the code again, we get a slightly more interesting stack trace:
Object reference not set to an instance of an object.
at Program.GetTeamDetails(Int32 teamId)
at Program.PrintAllPlayersInTeam(Int32 teamId)
at Program.Main()
Now we know that the exception is thrown on the GetTeamDetails method, so we reduced the scope of our investigations to the following lines:
Feed teamFeed = _sportClient.GetFeedForTeam(teamId);
Team currentTeam = _feedParser.ParseTeamFeed(teamFeed.Content.ToLower());
return currentTeam;
It’s easy to understand that the most probable culprits are teamFeed and teamFeed.Content!
Of course, you must not exaggerate! Don’t create a method for every single operation you do: in that way, you’ll just clutter the code without adding any value.
Downsides
Yes, adding new functions can slightly impact the application performance. In fact, every time we call a function, a stack operation is performed. This means that the more nested methods we call, the more stack operations we perform. But does it really impact the application performance? Or is it better to write cleaner code, even if we lose some nanoseconds? If you want to see the different standpoints, head to my article Code opinion: performance or clean code?
Conclusion
Writing smaller functions not only boosts the code readability but also helps us debug faster (and smarter). As usual, we must not move every statement in its own function: just find the right level of readability that works for you.
👉 Let’s discuss it on Twitter or on the comment section below!
This summer I created my Personal Project Platform. It wasn’t exactly intentional. When I realised where my process was going, I was already some way along.
Speaking of process, I’m a big fan. When you’re ready to surrender, you’ll find yourself in places you wouldn’t expect. Anyway, two paths came together when I discovered I was working on my Personal Project Platform. Let’s talk about the first one.
Path 1: A Necessary Happy Place
As a designer, or as a human being for that matter, not every day is full of inspiration. Especially when the design-and-AI landscape changes as fast as it does now, it’s sometimes hard to see the big picture.
As a remedy, I started building a moodboard that would serve as my Happy Place. Whenever I came across a reference that made me smile, I put it there. It had sections for my dream office; quotes and thoughts that resonated with me; and random image fragments that, together, felt like me ~ or at least a designer version of me. I started adding my own scribbles, notes and thoughts about purpose: why am I still doing this? What am I looking for as a designer?
One evening in December 2022, I had a drink with a designer friend. We were making random things just for fun. At work, I had shifted into more of a managerial role, and I missed designing.
Then I thought: why not throw it online? So I created an Instagram account and posted my first Processing sketch.
The more I made, the more I wanted to make. Over time, this habit became part of me. Sketches became interactive, but it bothered me they only ran locally ~ I was the only one who could interact with them. I also started sharing quick tutorials, and was amazed by how many positive responses I got from people who felt inspired to make something of their own.
Where the Two Paths Meet
Meanwhile, my “Happy Place” notes grew longer and more intentional. I wanted more people to interact with my sketches. Since I was doing it all for fun, why not share the source code? Why not collect my resources for others to use?
Slowly it became an idea for a platform: one where the intentional and the unexpected coexist, showing new designers ~ especially with AI replacing all the fun ~ that learning a craft, practising, and training your creative muscle still matter.
Now I just had to build it.
I started with just a few basic components in Figma.
Building the Platform
Since we’re on Codrops, let’s talk code. I have a background in PHP and JavaScript ~ old-school, before ES6 or TypeScript, let alone Vue or React. I wanted to use this project to learn something new.
After some research, I decided on Nuxt.js. From what I read, it’s easier to set up than Next.js. And since my platform isn’t likely to scale any time soon, I think it does the job. I had also played with Prismic CMS a few years back. Lightweight, not too many features, but fine for me. So I watched some Nuxt.js+Prismic tutorials, and off I went.
The Hero
I knew I wanted interactive components. Something that gave visitors an immediate sense of my work. Let’s start with the hero.
Finding beauty in friction
With your mouse you draw objects onto the canvas, plain and simple. I wanted the objects to have a link with nature ~ something that grows, can flourish ~ as you would do when you take on lots of personal projects.
In my first sketch the flowers scaled from small to big, literally growing. But then I thought: how many times had I got stuck on a sketch, frustrated over an idea that just wouldn’t work out? So I decided linear growth wouldn’t be honest. Most of the time when I work on my projects my head is all over the place. Things should scale randomly, they don’t even need to match in width and height. I like it like this, it mirrors the tension between control and chaos in my work. Below you’ll find the bit where this is happening.
/**
* Get a portion of the next image
*/
public getPortion(): p5.Image {
// Fetch original
const original = this.getNext();
if (! original) return null;
// Source
const ow = original.width;
const oh = original.height;
const sx = Math.random() * ow;
const sy = Math.random() * oh;
// Remaining part
const loW = ow - sx;
const loH = oh - sy;
let sw = Math.round(loW * Math.random()) + 10;
let sh = Math.round(loH * Math.random()) + 10;
// Destination
const dx = 0;
const dy = 0;
const dw = sw;
const dh = sh;
// Create new image
const copy = this.p.createImage(dw, dh);
copy.copy(original, sx, sy, sw, sh, dx, dy, dw, dh);
return copy;
}
public getRandomSizedPortion(): p5.Image {
// Get portion
const img = this.getPortion();
if (! img) return null;
// Random size
const maxSize = this.p.width * .1;
img.resize(this.p.random(10,maxSize), this.p.random(10,maxSize));
return img;
}
The Footer
To balance the hero, I also made the footer interactive. I used an older sketch as a base, adding depth and texture to make it feel a little like an abstract ocean.
For me, it brings a sense of calm and focus ~ with subtle vertical movement and a tone that changes as you move the mouse along the x-axis. The snippet below should give you an idea of how it works, but the original sketch is available to download on the platform. So if you’re curious, go ahead and play.
/**
* Calculate all data
*/
public update() {
// Animation settings
let duration: number = 128;
let progress: number = this.p.frameCount % duration;
if(progress == 0) this.iteration++;
// Rows and height
let numRowsDrawn: number = this.numRows + 1 + this.iteration;
let colW: number = this.p.width / this.numCols;
let rowH: number = this.p.height / this.numRows;
let count = 0;
// Loop through rows
for (let y: number = this.iteration; y<numRowsDrawn; y++) {
// Calculate y position (start at the bottom)
let targetY: number = this.p.height - (y+1) * rowH + this.iteration * rowH;
// Where are we in the progress
let posY: number = this.p.map(progress, 0, duration, targetY, targetY+rowH);
// Mouse influence
const smoothing = 0.06;
this.currentMouseX += (this.p.mouseX - this.currentMouseX) * smoothing;
const mouseInfluence: number = this.p.map(this.currentMouseX, 0, this.p.width, .8, -.3);
// What is the influence based on the y position
let yInfluence: number = this.p.map(posY / this.numRows, 0, rowH, 1, this.numRows+1) * mouseInfluence;
// Double columns each row
let extraCols: number = Math.exp(yInfluence * Math.LN2);
// Size and position
let currentW: number = colW + extraCols * colW;
// Loop through columns
for (let x:number = 0; x<this.numCols; x++) {
// Calculate x position
let posX: number = x * currentW - (extraCols * yInfluence + 1) * colW;
// Don't draw things out of screen x-axis
if(posX > this.p.width) continue;
if(posX + currentW < 0) continue;
// Draw
this.display(x, y, posX, posY, currentW, rowH);
count++;
}
}
}
The Masonry Grid
I’ve always liked inspiration websites where a lot is going on. You get all sorts of images and videos that are strong on their own, but gain new purpose in a different context. That’s what I wanted for my case overview.
Since I don’t aim for any particular graphical style, I like that it feels more like a collection of references. This is why I decided to go for a masonry grid. I didn’t want to use a plugin, so I built this little CSS/JavaScript thingy where I use CSS Grid rows to distribute the images, and JavaScript to calculate how many rows it should span, depending on the aspect ratio that is set in the CMS. I think there is still room for improvement, but to be honest, I ran low on patience on this one. I decided it does the job for now. Maybe I will get back to it someday to refactor. Below is the snippet where most of the work happens.
function applyMasonry() {
// Fetch grid and items
const grid = document.querySelector('.masonry-grid');
const items = grid?.querySelectorAll('.masonry-item');
// Make sure they’re both loaded
if (!grid || !items) return
// Get properties from CSS
const rowHeight = parseInt(getComputedStyle(grid).getPropertyValue('grid-auto-rows'))
const gap = parseInt(getComputedStyle(grid).getPropertyValue('gap') || 0)
items.forEach(item => {
// Fetch media and info container separately
const media = item.querySelector('.masonry-item__image-container')
const info = item.querySelector('.masonry-item__info-container')
if (!media || !info) return
// Combine them to item height
const mediaHeight = media.getBoundingClientRect().height
const infoHeight = info.getBoundingClientRect().height
const itemHeight = mediaHeight + infoHeight
// Calculate how many rows to span
const rowSpan = Math.ceil((itemHeight + gap) / (rowHeight + gap))
// Apply row span
item.style.gridRowEnd = `span ${rowSpan}`;
item.style.opacity = 1;
})
}
Resources & Code
Since I truly want to encourage people to start their own journey with personal projects, I want to share resources and code examples to get them started.
Of course with the launch of this platform I had to do this retrospectively for more than 20 projects, so in future I’ll probably share more process and behind-the-scenes. Who knows. Anyway, this component gives me a space for anything that might be useful to people who are interested.
Two Weeks Without a Laptop
Then the summer holiday arrived. France. Four days of Disneyland chaos, followed by some peace near the ocean. Days were simple: beach, pool, playgrounds. In between, I picked up a Bon Iver notebook I’d bought back home.
At the time, the platform had a temporary wordmark with my initials “mvds”. But I felt I could spend a little more time and attention crafting something beautiful. So every day I doodled my initials in all sorts of forms. By the end of the holiday I had a pretty good idea of what my logomark should become. Back home, with two more weeks before I needed to get back to work, I started digitising my sketches and tweaking anchor points until I got it right. (Then tweaked a little more, you know how it goes.) This resulted in a logomark I’m quite proud of. So I figured it needed a place on the platform.
P5.js vs Three.js
For the launch of my logomark on Instagram, I created a Processing sketch that placed the logo in a pixelated 3D scene, rotating. I liked that it almost became a sculpture or building of sorts. Now I only needed to build a web version.
Because my Hero and Footer components were both p5.js, this was my first choice. But it was slow ~ I mean like really slow. No matter how I tried to optimise it, the 3D workload killed the performance. I had only worked with Three.js once a few years back, but I remembered it handled 3D pretty well. Not sure you’re going to have the best performing website by using multiple libraries, but since it’s all just for fun, I decided to give it a go. With the Three.js version I could add far more detail to the structure, and it still performed flawlessly compared to the p5.js version. Below you’ll see me looping through all the voxels.
let instanceId: number = 0;
// Loop using voxel resolution (detail), not image resolution
for (let z: number = 0; z < detail; z++) {
for (let y: number = 0; y < detail; y++) {
const flippedY: number = detail - 1 - y;
for (let x: number = 0; x < detail; x++) {
// Sample image using normalized coordinates
const sampleX: number = Math.floor((x / detail) * imgDetail);
const sampleY: number = Math.floor((flippedY / detail) * imgDetail);
const sampleZ: number = Math.floor((z / detail) * imgDetail);
const brightness1: number = getBrightnessAt(imgData, imgDetail, sampleX, sampleY);
const brightness2: number = getBrightnessAt(imgData, imgDetail, sampleZ, sampleY);
if (brightness1 < 100 && brightness2 < 100 && instanceId < maxInstances) {
dummy.position.set(
x * cellSize - (detail * cellSize) / 2,
y * cellSize - (detail * cellSize) / 2,
z * cellSize - (detail * cellSize) / 2
);
dummy.updateMatrix();
mesh.setMatrixAt(instanceId, dummy.matrix);
instanceId++;
}
}
}
}
Wrapping Up
This platform isn’t finished ~ that’s the point. It’s a space to interact with my coded tools, for sketches to be shared for further exploration and for process itself to stay visible. If you’re a designer or coder, I hope it nudges you to start or continue your own side projects. That’s how creativity stays alive. Thank you for reading.
Every time you ask Visual Studio to generate properties for you, it creates them with a simple, default format. But we can customize them by updating some options on our IDE. Let’s learn how!
Table of Contents
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
We, as developers, hate repetitive tasks, isn’t it? In fact, we often auto-generate code by using our IDE’s capabilities. Yet, sometimes the auto-generated code does not follow our team rules or our personal taste, so we have to rename stuff every single time.
For instance, say that your golden rule is to have your readonly properties named with a _ prefix: private readonly IService _myService instead of private readonly IService myService. Renaming the properties every time is… boring!
In this article, you will learn how to customize Visual Studio 2019 to get the most out of the auto-generated code. In particular, we will customize the names of the readonly properties generated when we add a dependency in a class constructor.
The usual autocomplete
If you work properly, you do heavy use of Dependency Injection. And, if you do it, you will often define dependencies in a class’ constructor.
Now, let’s have two simple actors: a class, MyService, and an interface, IMyDependency. We want to inject the IMyDependency service into the MyService constructor.
public MyService(IMyDependency myDependency)
{
}
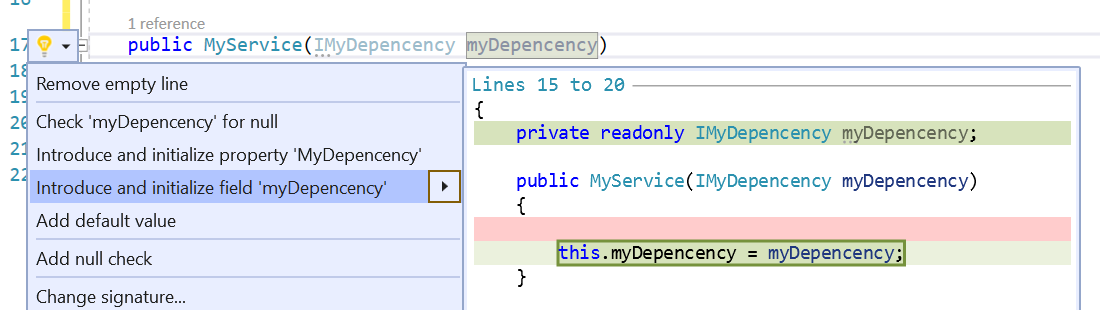
To store somewhere the reference to IMyDependency, you usually click on the lightbulb that appears on the left navigation or hit CTRL+. This command will prompt you with some actions, like creating and initializing a new field:
This automatic task then creates a private readonly IMyDependency myDependency and assigns to this value the dependency defined in the constructor.
Now, let’s say that we want our properties to have an underscore as a prefix: so we must manually rename myDependency to _myDependency. Ok, not that big issue, but we can still save some time just by avoiding doing it manually.
Setting up the right configurations
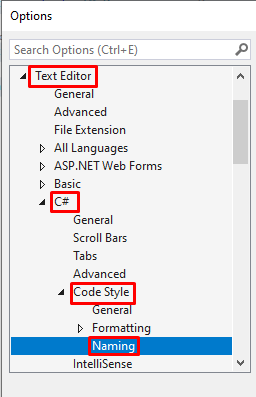
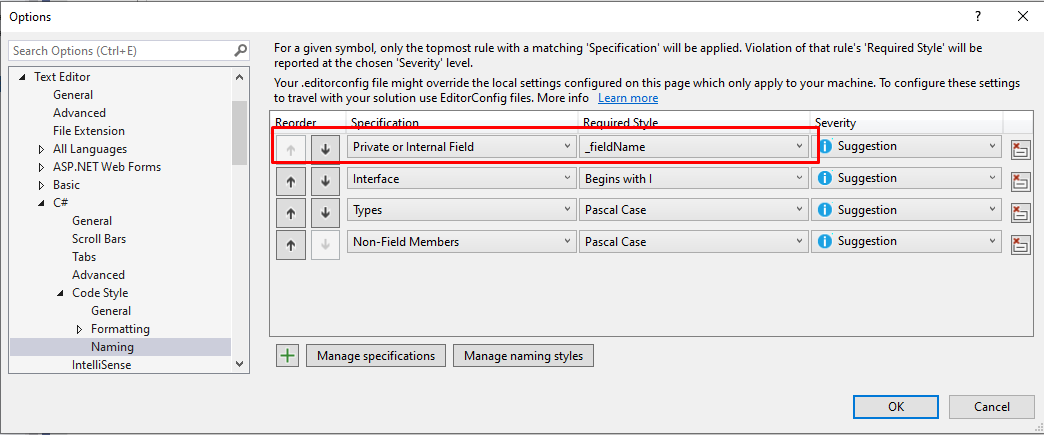
To configure how automatic properties are generated, head to Visual Studio, and, in the top menu, navigate to Tools and then Options.
Then, browse to Text Editor > C# > Code Style > Naming
Here we have all the symbols that we can customize.
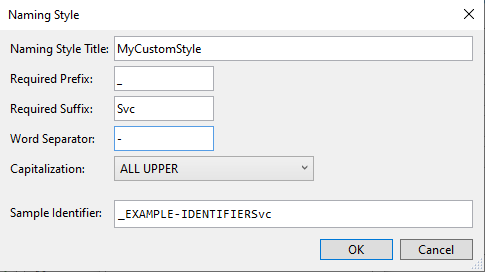
The first thing to do is to create a custom naming style. On the right side of the options panel, click on the “Manage naming styles” button, and then on the “+” button. You will see a form that you can fill with your custom styles; the Sample Identifier field shows you the result of the generated fields.
In the following picture you can see the result you can obtain if you fill all the fields: our properties will have a _ prefix, an Svc suffix, the words will be separated by a - symbol, and the name will be uppercase. As a result, the property name will be _EXAMPLE-IDENTIFIERSvc
Since we’re only interested in adding a _ prefix and making the text in camelCase, well… just add those settings! And don’t forget to specify a style name, like _fieldName.
Close the form, and add a new Specification on the list: define that the new style must be applied to every Private or Internal Field, assign to it the newly created style (in my case, _fieldName). And… we’re done!
Final result
Now that we have everything in place, we can try adding a dependency to our MyService class:
As you can see, now the generated property is named _myDependency instead of myDependency.
And the same happens when you instantiate a new instance of MyService and then you pass a new dependency in the constructor: Visual Studio automatically creates a new constructor with the missing dependency and assigns it to a private property (but, in this case, is not defined as readonly).
Wrapping up
In this article, we’ve learned how to configure Visual Studio 2019 to create private properties in a custom format, like adding a prefix to the property name.
In my opinion, knowing the capabilities and possible customizations of your IDEs is one of the most underrated stuff. We spend most of our time working on an IDE – in my case, Visual Studio – so we should get to know it better to get the best from it and simplify our dev life.
Are there any other smart customizations that you want to share? Tell us about it in the comment section below!
Sometimes we need to use objects with the same name but from different namespaces. How to remove that ambiguity? By Using Aliases!
Table of Contents
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
You may have to reference classes or services that come from different namespaces or packages, but that have the same name. It may become tricky to understand which reference refers to a specific type.
Yes, you could use the fully qualified name of the class. Or, you could use namespace aliases to write cleaner and easier-to-understand code.
It’s just a matter of modifying your using statements. Let’s see how!
The general approach
Say that you are working on an application that receives info about football matches from different sources using NuGet packages, and then manipulates the data to follow some business rules.
Both services, ShinyData and JuanStatistics (totally random names!), provide an object called Match. Of course, those objects live in their specific namespaces.
Since you are using the native implementation you cannot rename the classes to avoid ambiguity. So you’ll end up with code like this:
void Main()
{
var shinyMatch = new ShinyData.Football.Statistics.Match();
var juanMatch = new JuanStatistics.Stats.Football.Objects.Match();
}
Writing the fully qualified namespace every time can easily become boring. The code becomes less readable too!
Luckily we have 2 solutions. Or, better, a solution that we can apply in two different ways.
Namespace aliases – a cleaner solution
The following solution will not work:
using ShinyData.Football.Statistics;
using JuanStatistics.Stats.Football.Objects;
void Main()
{
var shinyMatch = new Match();
var juanMatch = new Match();
}
because, of course, the compiler is not able to understand the exact type of shinyMatch and juanMatch.
But we can use a nice functionality of C#: namespace aliases. It simply means that we can name an imported namespace and use the alias to reference the related classes.
Using alias for the whole namespace
using Shiny = ShinyData.Football.Statistics;
using Juan = JuanStatistics.Stats.Football.Objects;
void Main()
{
var shinyMatch = new Shiny.Match();
var juanMatch = new Juan.Match();
}
This simple trick boosts the readability of your code.
Using alias for a specific class
Can we go another step further? Yes! We can even specify aliases for a specific class!
using ShinyMatch = ShinyData.Football.Statistics.Match;
using JuanMatch = JuanStatistics.Stats.Football.Objects.Match;
void Main()
{
var shinyMatch = new ShinyMatch();
var juanMatch = new JuanMatch();
}
Now we can create an instance of ShinyMatch which, since it is an alias listed among the using statements, is of type ShinyData.Football.Statistics.Match.
Define alias for generics
Not only you can use it to specify a simple class, but only for generics.
Say that the ShinyData namespace defines a generic class, like CustomDictionary<T>. You can reference it just as you did before!
using ShinyMatch = ShinyData.Football.Statistics.Match;
using JuanMatch = JuanStatistics.Stats.Football.Objects.Match;
using ShinyDictionary = ShinyData.Football.Statistics.CustomDictionary<int>;
void Main()
{
var shinyMatch = new ShinyMatch();
var juanMatch = new JuanMatch();
var dictionary = new ShinyDictionary();
}
Unluckily we have some limitations:
we must always specify the inner type of the generic: CustomDictionary<int> is valid, but CustomDictionary<T> is not valid
we cannot use as inner type a class defined with an alias: CustomDictionary<ShinyMatch> is invalid, unless we use the fully qualified name
Conclusion
We’ve seen how we can define namespace aliases to simplify our C# code: just add a name to an imported namespace in the using statement, and reference it on your code.
What would you reference, the namespace or the specific class?
👉 Let’s discuss it on Twitter or on the comment section below.
When the team at Droip first introduced their amazing builder, we received an overwhelming amount of positive feedback from our readers and community. That’s why we’re especially excited to welcome the Droip team back—this time to walk us through how to actually use their tool and bring Figma designs to life in WordPress.
Even though WordPress has powered the web for years, turning a modern Figma design into a WordPress site still feels like a struggle.
Outdated page builders, rigid layouts, and endless back-and-forth with developers, only to end up with a site that never quite matches the design.
Droip is a no-code website builder that takes a fresh approach to WordPress building, giving you full creative control without all the usual roadblocks.
What makes it especially exciting for Figma users is the instant Figma-to-Droip handoff. Instead of handing off your design for a rebuild, you can literally copy from Figma and paste it into Droip. Your structure, layers, and layout come through intact, ready to be edited, extended, and published.
In this guide, I’ll show you exactly how to prep your Figma file and go from a static mockup to a live WordPress site in minutes using a powerful no-code WordPress Builder.
What is Droip?
Making quite a buzz already for bringing the design freedom of Figma and the power of true no-code in WordPress, Droip is a relatively new, no-code WordPress website builder.
It’s not another rigid page builder that forces you into pre-made blocks or bloated layouts. Instead, Droip gives you full visual control over your site, from pixel-perfect spacing to responsive breakpoints, interactions, and dynamic content.
Here’s what makes it different:
Designer-first approach: Work visually like you do in Figma or Webflow.
Seamless Figma integration: Copy your layout from Figma and paste it directly into Droip. Your structure, layers, and hierarchy carry over intact.
Scalable design system: Use global style variables for fonts, colors, and spacing, so your site remains consistent and easy to update.
Dynamic content management: Droip’s Content Manager lets you create custom content types and bind repeated content (like recipes, products, or portfolios) directly to your design.
Lightweight & clean code output: Unlike traditional builders, Droip produces clean code, keeping your WordPress site performant and SEO-friendly.
In short, Droip lets you design a site that works exactly how you envisioned it, without relying on developers or pre-made templates.
Part 1: Prep Your Figma File
Good imports start with good Figma files.
Think of this step like designing with a builder in mind. You’ll thank yourself later.
Step 1: Use Auto Layout Frames for Everything
Don’t just drop elements freely on the canvas; wrap them in Frames with Auto Layout. Auto Layout helps Droip understand how your elements are structured. It improves spacing, alignment, and responsiveness.
So the better your hierarchy, the cleaner your import.
Wrap pages in a frame, set the max width (1320px is my go-to).
Place all design elements inside this Frame.
If you’re using grids, make sure they’re real grids, not just eyeballed. Set proper dimensions in Figma.
Step 2: Containers with Min/Max Constraints
When needed, give Frames min/max width and height constraints. This makes responsive scaling inside Droip way more predictable.
Step 3: Use Proper Elements Nesting & Naming
Droip reads your file hierarchically, so how you nest and name elements in Figma directly affects how your layout behaves once imported.
I recommend using Auto Layout Frames for all structural elements and naming the frames properly.
Buttons with icons: Wrap the button and its icon inside an Auto Layout Frame and name it Button.
Form fields with labels: Wrap each label and input combo in an Auto Layout Frame and name it ‘Input’.
Sections with content: Wrap headings, text, and images inside an Auto Layout Frame, and give it a clear name like Section_Hero or Section_Features.
Pro tip: Never leave elements floating outside frames. This ensures spacing, alignment, and responsiveness are preserved, and Droip can interpret your layout accurately.
Step 4: Use Supported Element Names
Droip reads your Figma layers and tries to understand what’s what, and naming plays a big role here.
If you use certain keywords, Droip will instantly recognize elements like buttons, forms, or inputs and map them correctly during import.
For example: name a button layer “Button” (or “button” / “BUTTON”), and Droip knows to treat it as an actual button element rather than just a styled rectangle. The same goes for inputs, textareas, sections, and containers.
Here are the supported names you can use:
Button: Button, button, BUTTON
Form: Form, form, FORM
Input: Input, input, INPUT
Textarea: Textarea, textarea, TEXTAREA
Section: Section, section, SECTION
Container: Container, container, CONTAINER
Step 5: Flatten Decorative Elements
Icons, illustrations, or complex vector shapes can get messy when imported as-is. To avoid errors, right-click and Flatten them in Figma. This keeps your file lightweight and makes the import into Droip cleaner and faster.
Step 6: Final Clean-Up
Before you hit export, give your file one last polish:
Delete any empty or hidden layers.
Double-check spacing and alignment.
Make sure everything lives inside a neat Auto Layout Frame.
A little housekeeping here saves a lot of time later. Once your file is tidy, you’re all set to import it into Droip.
Prepping Droip Before You Import
So you’ve cleaned up your Figma file, nested your elements properly, and named things clearly.
But before you hit copy–paste, there are a few things to set up in Droip that will save you a ton of time later. Think of this as laying the groundwork for a scalable, maintainable design system inside your site.
Install the Fonts You Used in Figma
If your design relies on a specific font, you’ll want Droip to have it too.
Google Fonts: These are easy, just select from Droip’s font library.
Custom Fonts: If you used a custom font, upload and install it in Droip before importing. Otherwise, your site may fall back to a default font, and all that careful typography work will go to waste.
Create Global Style Variables (Fonts, Sizes, Colors)
Droip gives you a Variables system (like tokens in design systems) that makes your site easier to scale.
Set up font variables (Heading, Body, Caption).
Define color variables for your brand palette (Primary, Secondary, Accent, Background, Text).
Add spacing and sizing variables if your design uses consistent paddings or margins.
When you paste your design into Droip, link your imported elements to these variables. This way, if your brand color ever changes, you update it once in variables and everything updates across the site.
Prepare for Dynamic Content
If your design includes repeated content like recipes, team members, or product cards, you don’t want to hard-code those. Droip’s Content Manager lets you create Collections that act like databases for your dynamic data.
Here’s the flow:
In Droip, create a Collection (e.g., “Recipes” with fields like Title, Date, Image, Ingredients, Description, etc.).
Once your design is imported, bind the elements (like the recipe card in your design) to those fields.
Part 2: Importing Your Figma Design into Droip
Okay, so your Figma file is clean, your fonts and variables are set up in Droip, and you’re ready to bring your design to life. The import process is actually surprisingly simple, but there are a few details you’ll want to pay attention to along the way.
If you don’t have a design ready, no worries. I’ve prepared a sample Figma file that you can import into Droip. Grab the Sample Figma Fileand follow along as we go from design to live WordPress site.
Step 1: Install the Figma to Droip Plugin
First things first, you’ll need the Figma to Droip plugin that makes this whole workflow possible.
Open Figma
Head to the Resources tab in the top toolbar
Search for “Figma to Droip”
Click Install
That’s it, you’ll now see it in your Plugins list, ready to use whenever you need it.
Step 2: Select and Generate Your Design
Now let’s get your layout ready for the jump.
In Figma, select the Frame you want to export.
Right-click > Plugins > Figma to Droip.
The plugin panel will open, and click Generate.
Once it’s done processing, hit Copy.
Make sure you’re selecting a final, polished version of your frame. Clean Auto Layout, proper nesting, and consistent naming will all pay off here.
Step 3: Paste into Droip
Here’s where the magic happens.
Open Droip and create a new page.
Click anywhere on the canvas or workspace.
Paste (Cmd + V on Mac, Ctrl + V on Windows).
Droip will instantly import your design, keeping the layout structure, spacing, styles, groupings, and hierarchy from Figma.
Not only that, Droip automatically converts your Figma layout into a responsive structure. That means your design isn’t just pasted in as a static frame, it adapts across breakpoints right away, even the custom ones.
Best of all, Droip outputs clean, lightweight code under the hood, so your WordPress site stays fast, secure, and SEO-friendly as well.
And just like that, your static design is now editable in WordPress.
Step 4: Refine Inside Droip
The foundation is there, now all you need to do is just add the finishing touches.
After pasting, you’ll want to refine your site and hook it into Droip’s powerful features:
Link to variables: Assign your imported fonts, colors, and sizes to the global style variables you created earlier. This makes your site scalable and future-proof.
Dynamic content: Replace static sections with collections from the Content Manager (think recipes, portfolios, products).
Interactions & animations: Add hover effects, transitions, and scroll-based behaviors, the kind of micro-interactions that bring your design to life.
Media: Swap out placeholder assets for final images, videos, or icons.
Step 5: Set Global Header & Footer
After import, you’ll want your header and footer to stay consistent across every page. The easiest way is to turn them into Global Components.
Select your header in the Layers panel > Right-click > Create Symbol.
Open the Insert Panel > Go to Symbols > Assign it as your Global Header.
Repeat the same steps for your footer.
Now, whenever you edit your header or footer, those changes will automatically sync across your entire site.
Step 6: Preview & Publish
Almost there.
Hit Preview to test responsiveness, check spacing, and see your interactions in action.
When everything feels right, click Publish, and your page is live.
And that’s it. In just a few steps, your Figma design moves from a static mockup to a living, breathing WordPress site.
Wrapping Up: From Figma to WordPress Instantly
What used to take weeks of handoff, revisions, and compromises can now happen in minutes. You still keep all the freedom to refine, extend, and scale, but without the friction of developer bottlenecks or outdated page builders.
So if you’ve ever wanted to skip the “translation gap” between design and development, this is your fastest way to turn Figma designs into live WordPress websites using a no-code WordPress Builder.























{kind=link}