Executive Summary
In early June 2025, Google’s corporate Salesforce instance (used to store contact data for small‑ and medium‑sized business clients) was compromised through a sophisticated vishing‑extortion campaign orchestrated by the threat‑group tracked as UNC6040 & UNC6240 (online cybercrime collective known as “The Com” linked to “ShinyHunters).”
The attackers combined three core vectors:
- Voice‑phishing (vishing) – Impersonating IT staff in a convincing phone call, persuading a Google employee to approve a malicious application connected to Salesforce, a rapid‑reply extortion scheme demanding Bitcoin payments within 72 hrs.
- OAuth app abuse – the deployment of custom Python scripts that emulate Salesforce’s DataLoader, allowing automated bulk exports.
- Anonymity layers – Mullvad VPN‑initiated calls followed by TOR‑based data exfiltration, which anonymized the actors’ true location.
Though Google confirmed that no user passwords were stolen, the breached dataset, included business names, email addresses, phone numbers and related notes. The implications reach far beyond the affected small and medium business customers: while associating compliance, brand integrity, partner security, and regulatory scrutiny of SaaS risk management practices.
Meanwhile, the Salesloft Drift attack orchestrated by UNC6395 has emerged as one of the most significant cyber incidents in late 2025, which compromised the Salesloft Drift (AI chat-bot/assistant) used for its Salesforce integration. The theft of OAuth token appears to have resulted in running SOQL queries on Salesforce databases that held objects such as cases, accounts, users and opportunities. The attack affected hundreds of Salesforce customers, impacting not just Salesforce users but also other third-party integrations. Salesloft said “Initial findings have shown that the actor’s primary objective was to steal credentials, specifically focusing on sensitive information like AWS access keys, passwords and Snowflake-related access tokens”. Google explicitly warned of the breach’s extensive scope beyond its own systems.
Primary Tactics & Attack Vectors:
- Initial Access: Unauthorized OAuth apps installed via trial accounts (using legitimate email domains) and later via compromised accounts from unrelated orgs.
- Vishing, Social Engineering: Voice phishing calls to employees
- Exfiltration: Custom Python scripts that replicate DataLoader operations.
Infrastructure: Initial calls routed via Mullvad VPN IPs; data transfer via TOR exit nodes. - Extortion: Requesting immediate Bitcoin payment.
Threat Attribution
UNC5537, UNC6040 & UNC6240 likely linked with “Scattered LAPSUS$ Hunters” (“Chos hub”) exhibits similar attack patterns.
A Telegram channel called “Scattered LAPSUS$ Hunters”, blending the names of ShinyHunters, Scattered Spider and Lapsus$ groups emerged, which researchers describe as a chaotic hub for leaks and threats. The group focuses in exploiting the human element to gain access to company networks. The channel ran public polls where members voted on which victim’s data to fully dump, advertised zero-day exploits and a supposed new ransomware toolkit, touting the collective’s action.
UNC6395 shared the theme of abusing OAuth mechanisms for Salesforce access via compromised 3rd party integration – evolving their tactics against cloud ecosystems. Meanwhile, UNC6040 uses vishing and OAuth abuse to access Salesforce through social engineering. Overlapping TTPs indicate targeting trusted access applications and the name ShinyHunters appears across these incidents. Al the same time, Google tracks this cluster separately as UNC6395, ShinyHunters extortion group initially told BleepingComputer that they were behind the SalesLoft Drift attack.
Parallel Campaigns
Similar tactics applied in attacks targeting Adidas, Qantas, Allianz Life, LVMH brands (Louis Vuitton, Dior, Tiffany & Co.), Chanel, AT&T, Santander, Starbucks Singapore, Snowflake breach at Ticketmaster, Cisco, Pandora, Bouygues Telecom, Tokopedia, Homechef, Chatbooks, Portail Orange, Farmers Insurance, TransUnion, UK Legal Aid Agency, Gucci, Salesforce, Fairhaven Homes, Workday, Mazars.fr, Adidas, Air France-KLM, Phantom Wallet, Neiman Marcus, Coca-Cola, ZScaler.
- Qantas Airways: Employee credentials & sensitive flight/customer records targeted. Attack blended SIM swapping + SaaS compromise.
- Air France-KLM: Airline loyalty accounts and CRM cloud environment probed.
- Retailers (generalized set) → Used social engineering and SIM-swap vishing to gain access to IT/helpdesk portals.
- Okta: Service provider breach led to downstream impact on multiple clients (identity federation exploited).
- MGM Resorts: Social engineering of IT desk led to ransomware deployment, slot machines & hotel services down for days.
- Caesars Entertainment: Extortion campaign where ransom was allegedly paid; loyalty program records got leaked.
- AT&T: Call metadata (500M+ records, including phone numbers, call/SMS logs) stolen and advertised for sale.
- Ticketmaster (Live Nation): ~560M customer records including event ticketing details, addresses, payment info leaked.
- Advance Auto Parts: Data set of supply chain and retail customer info stolen.
- Santander Bank: Customer financial records compromised; reported 30M records affected.
- LendingTree: Customer PII and loan data exposed.
- Neiman Marcus: Customer loyalty and credit program data targeted.
- Los Angeles Unified School District (LAUSD): Student/employee data exfiltrated from Snowflake environment.
- Pandora, Adidas, LVMH (Louis Vuitton, Chanel, Dior): Retail brand data exposed (customer PII + sales info).
- ZScaler: UNC6395 compromised Salesforce instance through Salesloft Drift and steals customer data
With the attack that involves compromise of the Salesloft Drift AI OAuth token, any data that could potentially be compromised from the databases (that held information on users, accounts, cases, etc,) can be utilized by the attacker in various ways. The stolen data could either be sold to third parties or used to access emails (as reported from a very small number of Google Workspace accounts) launch further credential-reuse attacks on other SaaS accounts.
Indicators of Compromise:
| UNC6040, UNC6240 | UNC6395 |
| 81.17.28.95
31.133.0.210 45.138.16.69 45.90.185.109 45.141.215.19 45.90.185.115 45.90.185.107 37.114.50.27 45.90.185.118 179.43.159.201 38.135.24.30 91.199.42.164 192.159.99.74 |
208.68.36.90
44.215.108.109 154.41.95.2 176.65.149.100 179.43.159.198 185.130.47.58 185.207.107.130 185.220.101.133 185.220.101.143 185.220.101.164 185.220.101.167 185.220.101.169 185.220.101.180 185.220.101.185 185.220.101.33 192.42.116.179 192.42.116.20 194.15.36.117 195.47.238.178 195.47.238.83 |
| shinycorp@tuta[.]com
shinygroup@tuta[.]com shinyhuntersgroups@tutamail[.]com ticket-dior[.]com ticket-nike[.]com ticket-audemarspiguet[.]com |
|
| Salesforce-Multi-Org-Fetcher/1.0
Salesforce-CLI/1.0 python-requests/2.32.4 Python/3.11 aiohttp/3.12.15 |
In both the campaigns Google observed TOR exit nodes being used to access compromised Salesforce accounts.
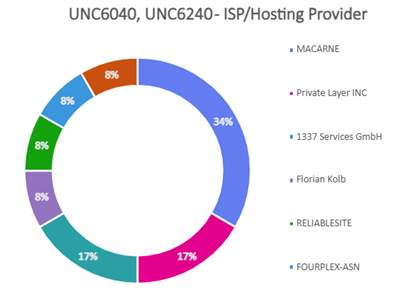
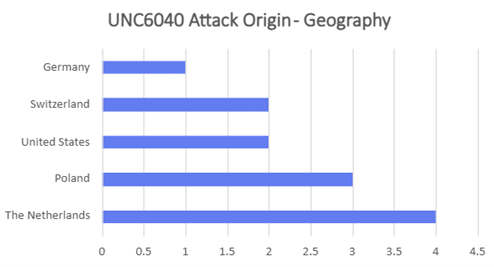
- Majority of attacks orchestrated by UNC6040 and UNC6240 (ShinyHunters) could be traced to originate from TOR exit nodes hosted either in Netherlands or Poland. These were hosted primarily at Macarne or Private Layer INC.
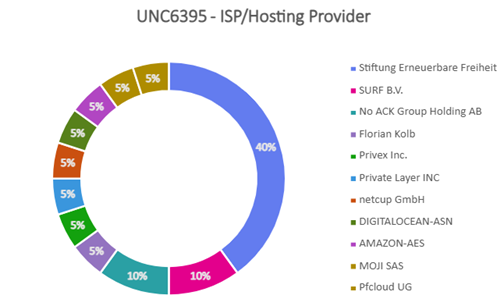
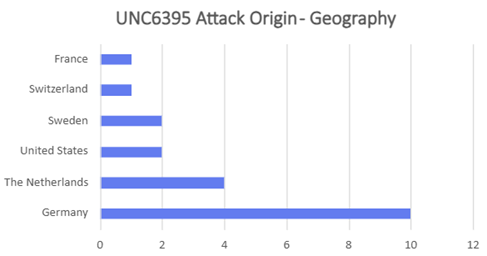
- Attackers were found to blend TOR traffic with legitimate OAuth sessions to obscure origin and make detection harder. Attacks orchestrated by UNC6395 could be traced to originate from TOR exit nodes hosted either in Germany or Netherlands. These were hosted primarily at Stiftung Erneuerbare Freiheit.
- Many suspicious SOQL queries (data exfiltration) and deletion of scheduled jobs were initiated from TOR IP addresses, indicating adversaries were anonymizing data theft operations.
Similarly, Scattered Spider used TOR exit IPs as a cover for account takeovers and extortion activity.
- Attackers combined vishing (helpdesk calls) with credential access, then routed subsequent access through Tor.
- Tor traffic was especially noted when adversaries escalated privileges or accessed sensitive SaaS applications.
- Europe-heavy nodes with a notable U.S. presence.
Common Threads Across Both Campaigns
- TOR IPs as operational cover was consistently used to hide adversary infrastructure.
- Identity-based intrusions by both groups abused identity trust rather than exploiting zero-days.
- Overlap with Scattered Spider tradecraft where both campaigns show attackers mixing social engineering or stolen credentials with TOR.
- TOR exit nodes have different ASNs, but both campaigns leverage NL exit nodes. ASN 58087 (Florian Kolb, DE) overlaps across both the campaigns.
Threat Landscape
Threat actors such as UNC6040 (ShinyHunters-affiliated), Scattered Spider (UNC3944), and UNC5537 have targeted organizations in the hospitality, retail, and education sectors in the Americas and Europe.
Scattered Spider (UNC3944) is known for sophistication and stealth:
- Reliably uses commercial VPN services to mask origin: Mullvad VPN, ExpressVPN, NordVPN, Ultrasurf, Easy VPN, ZenMate.
- Employs Tools and TTPs including disabling Antivirus/EDR, lateral movement via ADRecon, credential dumping with Mimikatz/LaZagne, and persistence via RMM and cloud VMs.
“The Com”, short for The Community, is less a formal hacking group and more a sociopathic cybercriminal subculture:
- Comprised of 1,000+ members and mostly aged 11–25, they operate across Canada, the U.S., and the U.K.
- Engages in SIM swapping, cryptocurrency theft, swatting, sextortion, spear-phishing, and even extreme coercion or violence.
- Intel471 reports that members are recruited via social media/gaming and coerced into crimes ranging from grooming to violent acts; the network has also issued a manual (“The Bible”) detailing techniques such as ATM skimming, IP grabbing, doxxing, extortion, and grooming.

UNC5537 orchestrated a large-scale breach targeting Snowflake customer environments:
- In April–June 2024, accessed over 160 organizations including AT&T, Ticketmaster/Live Nation, Santander, Advance Auto Parts, LendingTree, Neiman Marcus, and LA Unified School District – via stolen credentials, often from infostealers, and constraints due to lack of MFA.
- Data stolen included sensitive PII, event tickets, DEA numbers, and call/text metadata (500M+ records in aggregate).
- Targets were later advertised and extorted through forums.
DataBreaches.net received screenshots of a Telegram message from ShinyHunters claiming to outpace law enforcement, mocking capabilities of agencies like the NSA and stating: “Even the NSA can’t stop or identify us anymore. The FBI… is irrelevant and incompetent…”. In conversation, “Shiny” asserted that Scattered Spider sources voice calls and share access and hinted at a future “Snowflake 3.0” campaign, promising even greater operations ahead.
Cross-Actor Victim Overlaps
- Cloud SaaS as a hub: Salesforce (UNC6040), Okta (Scattered Spider), and Snowflake (UNC5537) breaches show pivot via cloud identity/data platforms.
- Retail & hospitality: Multiple actors target customer/loyalty records
- Scattered Spider targeted casinos.
- UNC6040 targeted retailers.
- UNC5537 targeted luxury brands.
- Education: UNC6040 and UNC5537 both hit educational institutions, stealing student/faculty data.
- Financial institutions: Santander (UNC5537) vs smaller fintech/payment targets by The Com/Scattered Spider (SIM swaps).
Detection & Monitoring Guidance
Additional indicators and associated detection rules for detecting the threat group is made available through STI and SMAP.
What we recommend
- Monitoring Logs
Continuously scan for LOGIN events from unfamiliar IP ranges (especially Mullvad or TOR exit nodes). Flag any API activity exhibiting a high volume of requests every hour. - OAuth App Watch‑list
Maintain a dynamic registry of approved apps. Trigger alerts on new or anomalous app registrations. Enforce a mandatory admin sign‑off workflow. The below detection rule is an example to detect suspicious signin events with OAuth:2.0:
`SigninLogs | where ResultType == “0” | where AuthenticationDetails has “OAuth:2.0” | where AppDisplayName startswith “Salesforce” | summarize count() by UserPrincipalName, AppDisplayName, IPAddress | where count_ > 5` - Vishing Detection
Implement caller‑ID verification, deploy voice‑analytics modules that detect key phrases (eg: “please pay”, “this is Google”) and cross‑reference against known threat‑intelligence feeds. Integrate with your call‑center platform to surface suspicious calls in real time. - Network Traffic Analysis
Inspect outbound traffic for TOR exit nodes and VPN tunnels that deviate from corporate baselines. Use DPI to spot unusually large, encrypted payloads. - Threat‑Intelligence Feeds
Subscribe to the latest ATT&CK and IOC updates for UNC6040/ShinyHunters. Monitor public Telegram channels for freshly disclosed IOCs. - Zero‑Trust IAM to reduce credential‑compromise impact
MFA, least‑privilege, RBAC for all Salesforce users. - OAuth App Governance to stop rogue app installations
Manual approval + periodic review - IP‑Based Restrictions to limit exfiltration paths
Allow only corporate VPN IPs; block TOR exits - Endpoint Security to stop malicious code execution
EDR to detect custom Python scripts - Call‑Center Hardening to mitigate human‑facing social engineering
Caller‑ID verification, recorded scripts, staff training - Data Loss Prevention to detects anomalous data movements
DLP on outbound exports (volume limits + alerts) - Strategic Initiative: SaaS Posture Management – continuous inventory & policy enforcement for third‑party integrations. Early rogue‑app detection is our key takeaway.
- Revoke and rotate tokens/credentials: Immediately revoke OAuth tokens tied to Salesloft Drift and reset all exposed API keys.
- Audit activity logs: Review SOQL queries and job deletions between Aug 8–18, 2025 for suspicious access.
- Limit OAuth permissions: Enforce least privilege, review app scopes regularly, and tighten approval workflows.
- Govern tokens: Ensure short-lived tokens, track their use, and revoke unused ones.
- Secure stored credentials: Move AWS keys, Snowflake tokens, and other secrets out of Salesforce objects into vaults.
- Enhance monitoring: Use UEBA to detect unusual SaaS behavior and consolidate logs across Salesforce, identity providers, and third-party apps.
- Restrict integrations: Apply IP/network restrictions and remove untrusted apps until validated.
Strategic Outlook
- TTP Evolution – The ShinyHunters group hints at a potential pivot towards ransomware‑as‑a‑service (ShinySP1D3R).
- Broader Targeting – High‑profile brands (Adidas, Qantas, Chanel, etc.) demonstrate that the same methodology can be scaled.
- Regulatory Momentum – Expect stricter SaaS risk‑management mandates, amplifying the need for proactive controls.
- Attribution Difficulty – Continued use of VPN/TOR & compromised third‑party accounts will heighten detection complexity; behavioral analytics will become indispensable.
Final Note from Our Research Team
The Google Salesforce breach is a textbook illustration of how modern threat actors blend technical supply‑chain exploitation with fast‑turnover social engineering. For organizations that rely on cloud‑native platforms, we see a critical need to:
- Revisit SaaS integration policies – treat every third‑party app as a potential attack vector.
- Strengthen human‑facing security – call‑center hardening and real‑time vishing detection should become a standard part of the security stack.
- Adopt a data‑centric risk perspective – even smaller datasets can fuel large-scale phishing campaigns.
- Our threat‑intelligence platform remains actively monitoring the ShinyHunters/Tor‑Mullvad threat chain and will update clients with emerging IOCs and risk indicators. We encourage you to integrate these insights into your defensive posture and to collaborate with our team for a tailored, intelligence‑driven response.
Conclusion
The Google internal Salesforce breach orchestrated by UNC6040 (“ShinyHunters”) underscores critical vulnerabilities in modern SaaS environments. The attack demonstrates that even data traditionally considered “low-sensitivity” can be weaponized for targeted phishing and extortion schemes, while also posing significant regulatory, reputational, operational, and financial risks. Organizations must adopt robust Identity & Access Management controls, enforce strict OAuth governance, and integrate comprehensive monitoring to mitigate evolving threats.
The UNC6395 campaign highlights how third-party OAuth integrations can undermine SaaS security. By abusing trusted tokens, attackers bypassed MFA and exfiltrated sensitive data from hundreds of organizations. This attack reinforces SaaS ecosystems and not just core apps as prime targets. Strong governance over OAuth apps, token lifecycles, and SaaS behaviors is critical to reducing risk. Proactive monitoring, least privilege, and credential hygiene are essential to defending against token-based intrusions like this.
Authors
Deepak Thomas Philip
Kartikkumar Jivani
Sathwik Ram Prakki
Subhajeet Singha
Rhishav Kanjilal
Shayak Tarafdar