Revise PowerShell basics with a simple script that opens a browser for each specified URL. We’re gonna cover how to declare variables, define arrays, concatenate strings and run CMD commands.
Table of Contents
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
Say that your project is already deployed on multiple environments: dev, UAT, and production; now you want to open the same page from all the environments.
You could do it manually, by composing the URL on a notepad. Or you could create a PowerShell script that opens them for you.
In this article, I’m going to share with you a simple script to open multiple browsers with predefined URLs. First of all, I’ll show you the completed script, then I’ll break it down to understand what’s going on and to brush up on some basic syntax for PowerShell.
Understanding the problem: the full script
I have a website deployed on 3 environments: dev, UAT, and production, and I want to open all of them under the same page, in this case under “/Image?w=60”.
So, here’s the script that opens 3 instances of my default browser, each with the URL of one of the environments:
In fact, to declare an array you must simply separate each string with ,.
Foreach loops in PowerShell
Among the other loops (while, do-while, for), the foreach loop is probably the most used.
Even here, it’s really simple:
foreach($baseUrl in $baseUrls)
{
}
As we’ve already seen before, there is no type declaration for the current item.
Just like C#, the keyword used in the body of the loop definition is in.
foreach (var item in collection)
{
// In C# we use the `var` keyword to declare the variable}
String concatenation in PowerShell
The $fullUrl variable is the concatenation of 2 string variables: $baseUrl and $path.
$fullUrl = "$($baseUrl)$($path)";
We can see that to declare this new string we must wrap it between "...".
More important, every variable that must be interpolated is wrapped in a $() block.
How to run a command with PowerShell
The key part of this script is for sure this line:
Invoke-Expression "cmd.exe /C start $($fullUrl)"
The Invoke-Expression cmdlet evaluates and runs the specified string in your local machine.
The command cmd.exe /C start $($fullUrl) just tells the CMD to open the link stored in the $fullUrl variable with the default browser.
Wrapping up
We learned how to open multiple browser instances with PowerShell. As you can understand, this was just an excuse to revise some basic concepts of PowerShell.
I think that many of us are too focused on our main language (C#, Java, JavaScript, and so on) that we forget to learn something different that may help us with our day-to-day job.
Davide Bellone is a Principal Backend Developer with more than 10 years of professional experience with Microsoft platforms and frameworks.
He loves learning new things and sharing these learnings with others: that’s why he writes on this blog and is involved as speaker at tech conferences.
In this tutorial, we’ll explore how to bring motion and interactivity to your WebGL projects by combining GSAP with custom shaders. Working with the Dev team at Adoratorio Studio, I’ll guide you through four GPU-powered effects, from ripples that react to clicks to dynamic blurs that respond to scroll and drag.
We’ll start by setting up a simple WebGL scene and syncing it with our HTML layout. From there, we’ll move step by step through more advanced interactions, animating shader uniforms, blending textures, and revealing images through masks, until we turn everything into a scrollable, animated carousel.
By the end, you’ll understand how to connect GSAP timelines with shader parameters to create fluid, expressive visuals that react in real time and form the foundation for your own immersive web experiences.
Creating the HTML structure
As a first step, we will set up the page using HTML.
We will create a container without specifying its dimensions, allowing it to extend beyond the page width. Then, we will set the main container’s overflow property to hidden, as the page will be later made interactive through the GSAP Draggable and ScrollTrigger functionalities.
We’ll style all this and then move on to the next step.
Sync between HTML and Canvas
We can now begin integrating Three.js into our project by creating a Stage class responsible for managing all 3D engine logic. Initially, this class will set up a renderer, a scene, and a camera.
We will pass an HTML node as the first parameter, which will act as the container for our canvas. Next, we will update the CSS and the main script to create a full-screen canvas that resizes responsively and renders on every GSAP frame.
Back in our main.js file, we’ll first handle the stage’s resize event. After that, we’ll synchronize the renderer’s requestAnimationFrame (RAF) with GSAP by using gsap.ticker.add, passing the stage’s render function as the callback.
// Update resize with the stage resize
function resize() {
...
stage.resize();
}
// Add render cycle to gsap ticker
gsap.ticker.add(stage.render.bind(stage));
<style>
.content__canvas {
position: absolute;
top: 0;
left: 0;
width: 100vw;
height: 100svh;
z-index: 2;
pointer-events: none;
}
</style>
It’s now time to load all the images included in the HTML. For each image, we will create a plane and add it to the scene. To achieve this, we’ll update the class by adding two new methods:
setUpPlanes() {
this.DOMElements.forEach((image) => {
this.scene.add(this.generatePlane(image));
});
}
generatePlane(image, ) {
const loader = new TextureLoader();
const texture = loader.load(image.src);
texture.colorSpace = SRGBColorSpace;
const plane = new Mesh(
new PlaneGeometry(1, 1),
new MeshStandardMaterial(),
);
return plane;
}
We can then call setUpPlanes() within the constructor of our Stage class. The result should resemble the following, depending on the camera’s z-position or the planes’ placement—both of which can be adjusted to fit our specific needs.
The next step is to position the planes precisely to correspond with the location of their associated images and update their positions on each frame. To achieve this, we will implement a utility function that converts screen space (CSS pixels) into world space, leveraging the Orthographic Camera, which is already aligned with the screen.
render() {
this.renderer.render(this.scene, this.camera);
// For each plane and each image update the position of the plane to match the DOM element position on page
this.DOMElements.forEach((image, index) => {
this.scene.children[index].position.copy(getWorldPositionFromDOM(image, this.camera, this.renderer));
});
}
By hiding the original DOM carousel, we can now display only the images as planes within the canvas. Create a simple class extending ShaderMaterial and use it in place of MeshStandardMaterial for the planes.
Click on the images for a ripple and coloring effect
This steps breaks down the creation of an interactive grayscale transition effect, emphasizing the relationship between JavaScript (using GSAP) and GLSL shaders.
Step 1: Instant Color/Grayscale Toggle
Let’s start with the simplest version: clicking the image makes it instantly switch between color and grayscale.
The JavaScript (GSAP)
At this stage, GSAP’s role is to act as a simple “on/off” switch so let’s create a GSAP Observer to monitor the mouse click interaction:
An instant switch is boring. Let’s make the transition a smooth, circular reveal that expands from the center.
The JavaScript (GSAP)
GSAP’s role now changes from a switch to an animator. Instead of gsap.set(), we use gsap.to() to animate uGrayscaleProgress from 0 to 1 (or 1 to 0) over a set duration. This sends a continuous stream of values (0.0, 0.01, 0.02, …) to the shader.
The shader now uses the animated uGrayscaleProgress to define the radius of a circle.
void main() {
float dist = distance(vUv, vec2(0.5));
// 2. Create a circular mask.
float mask = smoothstep(uGrayscaleProgress - 0.1, uGrayscaleProgress, dist);
// 3. Mix the colors based on the mask's value for each pixel.
vec3 finalColor = mix(originalColor, grayscaleColor, mask);
gl_FragColor = vec4(finalColor, 1.0);
}
How smoothstep works here: Pixels where dist is less than uGrayscaleProgress – 0.1 get a mask value of 0. Pixels where dist is greater than uGrayscaleProgress get a value of 1. In between, it’s a smooth transition, creating the soft edge.
Step 3: Originating from the Mouse Click
The effect is much more engaging if it starts from the exact point of the click.
The JavaScript (GSAP)
We need to tell the shader where the click happened.
Raycasting: We use a Raycaster to find the precise (u, v) texture coordinate of the click on the mesh.
uMouse Uniform: We add a uniform vec2 uMouse to our material.
GSAP Timeline: Before the animation starts, we use .set() on our GSAP timeline to update the uMouse uniform with the intersection.uv coordinates.
We simply replace the hardcoded center with our new uMouse uniform.
...
uniform vec2 uMouse; // The (u,v) coordinates from the click
...
void main() {
...
// 1. Calculate distance from the MOUSE CLICK, not the center.
float dist = distance(vUv, uMouse);
}
Important Detail: To ensure the circular reveal always covers the entire plane, even when clicking in a corner, we calculate the maximum possible distance from the click point to any of the four corners (getMaxDistFromCorners) and normalize our dist value with it: dist / maxDist.
This guarantees the animation completes fully.
Step 4: Adding the Final Ripple Effect
The last step is to add the 3D ripple effect that deforms the plane. This requires modifying the vertex shader.
The JavaScript (GSAP)
We need one more animated uniform to control the ripple’s lifecycle.
uRippleProgress Uniform: We add a uniform float uRippleProgress.
GSAP Keyframes: In the same timeline, we animate uRippleProgress from 0 to 1 and back to 0. This makes the wave rise up and then settle back down.
High-Poly Geometry: To see a smooth deformation, the PlaneGeometry in Three.js must be created with many segments (e.g., new PlaneGeometry(1, 1, 50, 50)). This gives the vertex shader more points to manipulate.
generatePlane(image, ) {
...
const plane = new Mesh(
new PlaneGeometry(1, 1, 50, 50),
new PlanesMaterial(texture),
);
return plane;
}
Vertex Shader: This shader now calculates the wave and moves the vertices.
Fragment Shader: We can use the ripple intensity to add a final touch, like making the wave crests brighter.
varying float vRipple; // Received from vertex shader
void main() {
// ... (all the color and mask logic from before)
vec3 color = mix(color1, color2, mask);
// Add a highlight based on the wave's height
color += vRipple * 2.0;
gl_FragColor = vec4(color, diffuse.a);
}
By layering these techniques, we create a rich, interactive effect where JavaScript and GSAP act as the puppet master, telling the shaders what to do, while the shaders handle the heavy lifting of drawing it beautifully and efficiently on the GPU.
Step 5: Reverse effect on previous tile
As a final step, we set up a reverse animation of the current tile when a new tile is clicked. Let’s start by creating the reset animation that reverses the animation of the uniforms:
Now, at each click, we need to set the current tile so that it’s saved in the constructor, allowing us to pass the current material to the reset animation. Let’s modify the onClick function like this and analyze it step by step:
if (this.activeObject && intersection.object !== this.activeObject && this.activeObject.userData.isBw) {
this.resetMaterial(this.activeObject)
// Stops timeline if active
if (this.activeObject.userData.tl?.isActive()) this.activeObject.userData.tl.kill();
// Cleans timeline
this.activeObject.userData.tl = null;
}
// Setup active object
this.activeObject = intersection.object;
If this.activeObject exists (initially set to null in the constructor), we proceed to reset it to its initial black and white state
If there’s a current animation on the active tile, we use GSAP’s kill method to avoid conflicts and overlapping animations
We reset userData.tl to null (it will be assigned a new timeline value if the tile is clicked again)
We then set the value of this.activeObject to the object selected via the Raycaster
In this way, we’ll have a double ripple animation: one on the clicked tile, which will be colored, and one on the previously active tile, which will be reset to its original black and white state.
Texture reveal mask effect
In this tutorial, we will create an interactive effect that blends two images on a plane when the user hovers or touches it.
Step 1: Setting Up the Planes
Unlike the previous examples, in this case we need different uniforms for the planes, as we are going to create a mix between a visible front texture and another texture that will be revealed through a mask that “cuts through” the first texture.
Let’s start by modifying the index.html file, adding a data attribute to all images where we’ll specify the underlying texture:
Then, inside our Stage.js, we’ll modify the generatePlane method, which is used to create the planes in WebGL. We’ll start by retrieving the second texture to load via the data attribute, and we’ll pass the plane material the parameters with both textures and the aspect ratio of the images:
Quickly, let’s create a GSAP Observer to monitor the mouse movement, passing two functions:
onMove checks, using the Raycaster, whether a plane is being hit in order to manage the opening of the reveal mask
onHoverEnd is triggered when the cursor leaves the target area, so we’ll use this method to reset the reveal mask’s expansion uniform value back to 0.0
Let’s go into more detail on the onMove function to explain how it works:
In the onMove method, the first step is to normalize the mouse coordinates from -1 to 1 to allow the Raycaster to work with the correct coordinates.
On each frame, the Raycaster is then updated to check if any object in the scene is intersected. If there is an intersection, the code saves the hit object in a variable.
When an intersection occurs, we proceed to work on the animation of the shader uniforms.
Specifically, we use GSAP’s set method to update the mouse position in uMouse, and then animate the uMixFactor variable from 0.0 to 1.0 to open the reveal mask and show the underlying texture.
If the Raycaster doesn’t find any object under the pointer, the hoverOut method is called.
hoverOut() {
if (!this.intersected) return;
// Stop any running tweens on the uMixFactor uniform
gsap.killTweensOf(this.intersected.material.uniforms.uMixFactor);
// Animate uMixFactor back to 0 smoothly
gsap.to(this.intersected.material.uniforms.uMixFactor, { value: 0.0, duration: 0.5, ease: 'power3.out });
// Clear the intersected reference
this.intersected = null;
}
This method handles closing the reveal mask once the cursor leaves the plane.
First, we rely on the killAllTweensOf method to prevent conflicts or overlaps between the mask’s opening and closing animations by stopping all ongoing animations on the uMixFactor .
Then, we animate the mask’s closing by setting the uMixFactor uniform back to 0.0 and reset the variable that was tracking the currently highlighted object.
Inside the main() function, it starts by normalizing the UV coordinates and the mouse position relative to the image’s aspect ratio. This correction is applied because we are using non-square images, so the vertical coordinates must be adjusted to keep the mask’s proportions correct and ensure it remains circular. Therefore, the vUv.y and uMouse.y coordinates are modified so they are “scaled” vertically according to the aspect ratio.
At this point, the distance is calculated between the current pixel (correctedUv) and the mouse position (correctedMouse). This distance is a numeric value that indicates how close or far the pixel is from the mouse center on the surface.
We then move on to the actual creation of the mask. The uniform influence must vary from 1 at the cursor’s center to 0 as it moves away from the center. We use the smoothstep function to recreate this effect and obtain a soft, gradual transition between two values, so the effect naturally fades.
The final value for the mix between the two textures, that is the finalMix uniform, is given by the product of the global factor uMixFactor (which is a static numeric value passed to the shader) and this local influence value. So the closer a pixel is to the mouse position, the more its color will be influenced by the second texture, uTextureBack.
The last part is the actual blending: the two colors are mixed using the mix() function, which creates a linear interpolation between the two textures based on the value of finalMix. When finalMix is 0, only the front texture is visible.
When it is 1, only the background texture is visible. Intermediate values create a gradual blend between the two textures.
Click & Hold mask reveal effect
This document breaks down the creation of an interactive effect that transitions an image from color to grayscale. The effect starts from the user’s click, expanding outwards with a ripple distortion.
Step 1: The “Move” (Hover) Effect
In this step, we’ll create an effect where an image transitions to another as the user hovers their mouse over it. The transition will originate from the pointer’s position and expand outwards.
The JavaScript (GSAP Observer for onMove)
GSAP’s Observer plugin is the perfect tool for tracking pointer movements without the boilerplate of traditional event listeners.
Setup Observer: We create an Observer instance that targets our main container and listens for touch and pointer events. We only need the onMove and onHoverEnd callbacks.
onMove(e) Logic: When the pointer moves, we use a Raycaster to determine if it’s over one of our interactive images.
If an object is intersected, we store it in this.intersected.
We then use a GSAP Timeline to animate the shader’s uniforms.
uMouse: We instantly set this vec2 uniform to the pointer’s UV coordinate on the image. This tells the shader where the effect should originate.
uMixFactor: We animate this float uniform from 0 to 1. This uniform will control the blend between the two textures in the shader.
onHoverEnd() Logic:
When the pointer leaves the object, Observer calls this function.
We kill any ongoing animations on uMixFactor to prevent conflicts.
We animate uMixFactor back to 0, reversing the effect.
Code Example: the “Move” effect
This code shows how Observer is configured to handle the hover interaction.
import { gsap } from 'gsap';
import { Observer } from 'gsap/Observer';
import { Raycaster } from 'three';
gsap.registerPlugin(Observer);
export default class Effect {
constructor(scene, camera) {
this.scene = scene;
this.camera = camera;
this.intersected = null;
this.raycaster = new Raycaster();
// 1. Create the Observer
this.observer = Observer.create({
target: document.querySelector('.content__carousel'),
type: 'touch,pointer',
onMove: e => this.onMove(e),
onHoverEnd: () => this.hoverOut(), // Called when the pointer leaves the target
});
}
hoverOut() {
if (!this.intersected) return;
// 3. Animate the effect out
gsap.killTweensOf(this.intersected.material.uniforms.uMixFactor);
gsap.to(this.intersected.material.uniforms.uMixFactor, {
value: 0.0,
duration: 0.5,
ease: 'power3.out'
});
this.intersected = null;
}
onMove(e) {
// ... (Raycaster logic to find intersection)
const [intersection] = this.raycaster.intersectObjects(this.scene.children);
if (intersection) {
this.intersected = intersection.object;
const { material } = intersection.object;
// 2. Animate the uniforms on hover
gsap.timeline()
.set(material.uniforms.uMouse, { value: intersection.uv }, 0) // Set origin point
.to(material.uniforms.uMixFactor, { // Animate the blendvalue: 1.0,
duration: 3,
ease: 'power3.out'
}, 0);
} else {
this.hoverOut(); // Reset if not hovering over anything
}
}
}
The Shader (GLSL)
The fragment shader receives the uniforms animated by GSAP and uses them to draw the effect.
uMouse: Used to calculate the distance of each pixel from the pointer.
uMixFactor: Used as the interpolation value in a mix() function. As it animates from 0 to 1, the shader smoothly blends from textureFront to textureBack.
smoothstep(): We use this function to create a circular mask that expands from the uMouse position. The radius of this circle is controlled by uMixFactor.
uniform sampler2D uTexture; // Front image
uniform sampler2D uTextureBack; // Back image
uniform float uMixFactor; // Animated by GSAP (0 to 1)
uniform vec2 uMouse; // Set by GSAP on move
// ...
void main() {
// ... (code to correct for aspect ratio)
// 1. Calculate distance of the current pixel from the mouse
float distance = length(correctedUv - correctedMouse);
// 2. Create a circular mask that expands as uMixFactor increases
float influence = 1.0 - smoothstep(0.0, 0.5, distance);
float finalMix = uMixFactor * influence;
// 3. Read colors from both textures
vec4 textureFront = texture2D(uTexture, vUv);
vec4 textureBack = texture2D(uTextureBack, vUv);
// 4. Mix the two textures based on the animated value
vec4 finalColor = mix(textureFront, textureBack, finalMix);
gl_FragColor = finalColor;
}
Step 2: The “Click & Hold” Effect
Now, let’s build a more engaging interaction. The effect will start when the user presses down, “charge up” while they hold, and either complete or reverse when they release.
The JavaScript (GSAP)
Observer makes this complex interaction straightforward by providing clear callbacks for each state.
Setup Observer: This time, we configure Observer to use onPress, onMove, and onRelease.
onPress(e):
When the user presses down, we find the intersected object and store it in this.active.
We then call onActiveEnter(), which starts a GSAP timeline for the “charging” animation.
onActiveEnter():
This function defines the multi-stage animation. We use await with a GSAP tween to create a sequence.
First, it animates uGrayscaleProgress to a midpoint (e.g., 0.35) and holds it. This is the “hold” part of the interaction.
If the user continues to hold, a second tween completes the animation, transitioning uGrayscaleProgress to 1.0.
An onComplete callback then resets the state, preparing for the next interaction.
onRelease():
If the user releases the pointer before the animation completes, this function is called.
It calls onActiveLeve(), which kills the “charging” animation and animates uGrayscaleProgress back to 0, effectively reversing the effect.
onMove(e):
This is still used to continuously update the uMouse uniform, so the shader’s noise effect tracks the pointer even during the hold.
Crucially, if the pointer moves off the object, we call onRelease() to cancel the interaction.
Code Example: Click & Hold
This code demonstrates the press, hold, and release logic managed by Observer.
import { gsap } from 'gsap';
import { Observer } from 'gsap/Observer';
// ...
export default class Effect {
constructor(scene, camera) {
// ...
this.active = null; // Currently active (pressed) object
this.raycaster = new Raycaster();
// 1. Create the Observer for press, move, and release
this.observer = Observer.create({
target: document.querySelector('.content__carousel'),
type: 'touch,pointer',
onPress: e => this.onPress(e),
onMove: e => this.onMove(e),
onRelease: () => this.onRelease(),
});
// Continuously update uTime for the procedural effect
gsap.ticker.add(() => {
if (this.active) {
this.active.material.uniforms.uTime.value += 0.1;
}
});
}
// 3. The "charging" animation
async onActiveEnter() {
gsap.killTweensOf(this.active.material.uniforms.uGrayscaleProgress);
// First part of the animation (the "hold" phase)
await gsap.to(this.active.material.uniforms.uGrayscaleProgress, {
value: 0.35,
duration: 0.5,
});
// Second part, completes after the hold
gsap.to(this.active.material.uniforms.uGrayscaleProgress, {
value: 1,
duration: 0.5,
delay: 0.12,
ease: 'power2.in',
onComplete: () => {/* ... reset state ... */ },
});
}
// 4. Reverses the animation on early release
onActiveLeve(mesh) {
gsap.killTweensOf(mesh.material.uniforms.uGrayscaleProgress);
gsap.to(mesh.material.uniforms.uGrayscaleProgress, {
value: 0,
onUpdate: () => {
mesh.material.uniforms.uTime.value += 0.1;
},
});
}
// ... (getIntersection logic) ...
// 2. Handle the initial press
onPress(e) {
const intersection = this.getIntersection(e);
if (intersection) {
this.active = intersection.object;
this.onActiveEnter(this.active); // Start the animation
}
}
onRelease() {
if (this.active) {
const prevActive = this.active;
this.active = null;
this.onActiveLeve(prevActive); // Reverse the animation
}
}
onMove(e) {
// ... (getIntersection logic) ...
if (intersection) {
// 5. Keep uMouse updated while holding
const { material } = intersection.object;
gsap.set(material.uniforms.uMouse, { value: intersection.uv });
} else {
this.onRelease(); // Cancel if pointer leaves
}
}
}
The Shader (GLSL)
The fragment shader for this effect is more complex. It uses the animated uniforms to create a distorted, noisy reveal.
uGrayscaleProgress: This is the main driver, animated by GSAP. It controls both the radius of the circular mask and the strength of a “liquid” distortion effect.
uTime: This is continuously updated by gsap.ticker as long as the user is pressing. It’s used to add movement to the noise, making the effect feel alive and dynamic.
noise() function: A standard GLSL noise function generates procedural, organic patterns. We use this to distort both the shape of the circular mask and the image texture coordinates (UVs).
// ... (uniforms and helper functions)
void main() {
// 1. Generate a noise value that changes over time
float noisy = (noise(vUv * 25.0 + uTime * 0.5) - 0.5) * 0.05;
// 2. Create a distortion that pulses using the main progress animation
float distortionStrength = sin(uGrayscaleProgress * PI) * 0.5;
vec2 distortedUv = vUv + vec2(noisy) * distortionStrength;
// 3. Read the texture using the distorted coordinates for a liquid effect
vec4 diffuse = texture2D(uTexture, distortedUv);
// ... (grayscale logic)
// 4. Calculate distance from the mouse, but add noise to it
float dist = distance(vUv, uMouse);
float distortedDist = dist + noisy;
// 5. Create the circular mask using the distorted distance and progress
float maxDist = getMaxDistFromCorners(uMouse);
float mask = smoothstep(uGrayscaleProgress - 0.1, uGrayscaleProgress, distortedDist / maxDist);
// 6. Mix between the original and grayscale colors
vec3 color = mix(color1, color2, mask);
gl_FragColor = vec4(color, diffuse.a);
}
This shader combines noise-based distortion, smooth circular masking, and real-time uniform updates to create a liquid, organic transition that radiates from the click position. As GSAP animates the shader’s progress and time values, the effect feels alive and tactile — a perfect example of how animation logic in JavaScript can drive complex visual behavior directly on the GPU.
Dynamic blur effect carousel
Step 1: Create the carousel
In this final demo, we will create an additional implementation, turning the image grid into a scrollable carousel that can be navigated both by dragging and scrolling.
First we will implement the Draggable plugin by registering it and targeting the appropriate <div> with the desired configuration. Make sure to handle boundary constraints and update them accordingly when the window is resized.
We ill also link GSAP Draggable to the scroll functionality using the GSAP ScrollTrigger plugin, allowing us to synchronize both scroll and drag behavior within the same container. Let’s explore this in more detail:
Now that ScrollTrigger is configured on the same container, we can focus on synchronizing the scroll position between both plugins, starting from the ScrollTrigger instance:
onUpdate(e) {
const x = -maxScroll * e.progress;
gsap.set(carouselInnerRef, { x });
draggable.x = x;
draggable.update();
}
We then move on to the Draggable instance, which will be updated within both its onDrag and onThrowUpdate callbacks using the scrollPos variable. This variable will serve as the final scroll position for both the window and the ScrollTrigger instance.
Vector projects each plane’s 3D position into normalized device coordinates; .project(this.camera) converts to the -1..1 range, then it’s scaled to real screen pixel coordinates.
screenX are the 2D screen-space coordinates.
distance measures how far the plane is from the screen center.
maxDistance is the maximum possible distance from center to corner.
blurAmount computes blur strength based on distance from the center; it’s clamped between 0.0 and 5.0 to avoid extreme values that would harm visual quality or shader performance.
The <strong>uBlurAmount</strong> uniform is animated toward the computed blurAmount. Rounding to the nearest even number (Math.round(blurAmount / 2) * 2) helps avoid overly frequent tiny changes that could cause visually unstable blur.
This GLSL fragment receives a texture (uTexture) and a dynamic value (uBlurAmount) indicating how much the plane should be blurred. Based on this value, the shader applies a multi-pass Kawase blur, an efficient technique that simulates a soft, pleasing blur while staying performant.
Let’s examine the kawaseBlur function, which applies a light blur by sampling 4 points around the current pixel (uv), each offset positively or negatively.
texelSize computes the size of one pixel in UV coordinates so offsets refer to “pixel amounts” regardless of texture resolution.
Four samples are taken in a diagonal cross pattern around uv.
The four colors are averaged (multiplied by 0.25) to return a balanced result.
This function is a light single pass. To achieve a stronger effect, we apply it multiple times.
The multiPassKawaseBlur function does exactly that, progressively increasing blur and then blending the passes:
The first mix blends blur1 and blur2, while the second blends that result with blur3. The resulting finalBlur represents the Kawase-blurred texture, which we finally mix with the base texture passed via the uniform.
Finally, we mix the blurred texture with the original texture based on blurStrength, using another smoothstep from 0 to 1:
Bringing together GSAP’s animation power and the creative freedom of GLSL shaders opens up a whole new layer of interactivity for the web. By animating shader uniforms directly with GSAP, we’re able to blend smooth motion design principles with the raw flexibility of GPU rendering — crafting experiences that feel alive, fluid, and tactile.
From simple grayscale transitions to ripple-based deformations and dynamic blur effects, every step in this tutorial demonstrates how motion and graphics can respond naturally to user input, creating interfaces that invite exploration rather than just observation.
While these techniques push the boundaries of front-end development, they also highlight a growing trend: the convergence of design, code, and real-time rendering.
So, take these examples, remix them, and make them your own — because the most exciting part of working with GSAP and shaders is that the canvas is quite literally infinite.
It’s not a good practice to return the ID of a newly created item in the HTTP Response Body. What to do? You can return it in the HTTP Response Headers, with CreatedAtAction and CreatedAtRoute.
Table of Contents
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
Even though many devs (including me!) often forget about it, REST is not a synonym of HTTP API: it is an architectural style based on the central idea of resource.
So, when you are seeing an HTTP request like GET http://api.example.com/games/123 you may correctly think that you are getting the details of the game with ID 123. You are asking for the resource with ID 123.
But what happens when you create a new resource? You perform a POST, insert a new item… and then? How can you know the ID of the newly created resource – if the ID is created automatically – and use it to access the details of the new item?
Get item detail
For .NET APIs, all the endpoints are exposed inside a Controller, which is a class that derives from ControllerBase:
[ApiController][Route("[controller]")]
publicclassGameBoardController : ControllerBase
{
// all the actions here!}
So, to define a GET endpoint, we have to create an Action and specify the HTTP verb associated by using [HttpGet].
[HttpGet][Route("{id}")]public IActionResult GetDetail(Guid id)
{
var game = Games.FirstOrDefault(_ => _.Id.Equals(id));
if (game is not null)
{
return Ok(game);
}
else {
return NotFound();
}
}
This endpoint is pretty straightforward: if the game with the specified ID exists, the method returns it; otherwise, the method returns a NotFoundResult object that corresponds to a 404 HTTP Status Code.
Notice the [Route("{id}")] attribute: it means that the ASP.NET engine when parsing the incoming HTTP requests, searches for an Action with the required HTTP method and a route that matches the required path. Then, when it finds the Action, it maps the route parameters ({id}) to the parameters of the C# method (Guid id).
Hey! in this section I inserted not-so-correct info: I mean, it is generally right, but not precise. Can you spot it? Drop a comment😉
What to do when POST-ing a resource?
Of course, you also need to create new resources: that’s where the HTTP POST verb comes in handy.
Suppose a simple data flow: you create a new object, you insert it in the database, and it is the database itself that assigns to the object an ID.
Then, you need to use the newly created object. How to proceed?
You could return the ID in the HTTP Response Body. But we are using a POST verb, so you should not return data – POST is meant to insert data, not return values.
Otherwise, you can perform a query to find an item with the exact fields you’ve just inserted. For example
POST /item {title:"foo", description: "bar"}
GET /items?title=foo&description=bar
Not a good idea to use those ways, uh?
We have a third possibility: return the resource location in the HTTP Response Header.
How to return it? We have 2 ways: returning a CreatedAtActionResult or a CreatedAtRouteResult.
Using CreatedAtAction
With CreatedAtAction you can specify the name of the Action (or, better, the name of the method that implements that action) as a parameter.
ps: for the sake of simplicity, the new ID is generated directly into the method – no DBs in sight!
[HttpPost]public IActionResult Create(GameBoard game)
{
var newGameId = Guid.NewGuid();
var gameBoard = new GameBoardEntity
{
Title = game.Title,
Duration = game.Duration,
Id = newGameId
};
Games.Add(gameBoard);
return CreatedAtAction(nameof(GetDetail), new { id = newGameId }, game);
}
What are the second and third parameters?
We can see a new { id = newGameId } that indicates the route parameters defined in the GET endpoint (remember the [Route("{id}")] attribute? ) and assigns to each parameter a value.
The last parameter is the newly created item – or any object you want to return in that field.
Using CreatedAtRoute
Similar to the previous method we have CreatedAtRoute. As you may guess by the name, it does not refer to a specific Action by using the name, but it refers to the Route.
[HttpPost]public IActionResult Create(GameBoard game)
{
var newGameId = Guid.NewGuid();
var gameBoard = new GameBoardEntity
{
Title = game.Title,
Duration = game.Duration,
Id = newGameId
};
Games.Add(gameBoard);
return CreatedAtRoute("EndpointName", new { id = newGameId }, game);
}
To give a Route a name, we need to add a Name attribute to it:
[HttpGet]
- [Route("{id}")]
+ [Route("{id}", Name = "EndpointName")]
public IActionResult GetDetail(Guid id)
That’s it! Easy Peasy!
Needless to say, when we perform a GET at the URL specified in the Location attribute, we get the details of the item we’ve just created.
What about Routes and Query Strings?
We can use the same technique to get the details of an item by retrieving it using a query string parameter instead of a route parameter:
[HttpGet]
- [Route("{id}")]
- public IActionResult GetDetail(Guid id)
+ [Route("details")]
+ public IActionResult GetDetail([FromQuery] Guid id)
{
This means that the corresponding path is /GameBoard/details?id=123.
And, without modifying the Create methods we’ve seen before, we can let ASP.NET resolve the routing and create for us the URL:
And, surprise surprise, there’s more!
We can mix route parameters with query string parameters, and the Location attribute will hold the right value for the path.
Let’s update the GetDetail method: now the resource ID is included in the route, and a new parameter – title – is passed in query string to filter for the name of the game:
[HttpGet][Route("details/{id}")]public IActionResult GetDetail([FromRoute] Guid id, [FromQuery] string title)
{
var game = Games.FirstOrDefault(_ =>
_.Id.Equals(id) && _.Title.Equals(title, StringComparison.OrdinalIgnoreCase)
);
This means that we need to pass a new field in the object passed to the CreatedAtRoute and CreatedAtAction methods:
- return CreatedAtRoute("EndpointName", new { id = newGameId }, game);
+ return CreatedAtRoute("EndpointName", new { id = newGameId, title = game.Title }, game);
see, the title field?
When creating a new item, we can see the correct path in the Response Header:
Wrapping up
We’ve seen how to manage the creation of an item when developing a REST API: depending on the way you define routes, you can use CreatedAtRoute or CreatedAtAction.
Remember that REST APIs are based on the idea of manipulation of resources: you should remember that every HTTP Verb has its meaning, and you should always consider it when developing an endpoint. Is it a GET? We should not change the status of a resource. Is it a POST? We should not return the resource itself – but we can return a reference to it.
Senders and Receivers handle errors on Azure Service Bus differently. We’ll see how to catch them, what they mean and how to fix them. We’ll also introduce Dead Letters.
Table of Contents
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
In this article, we are gonna see which kind of errors you may get on Azure Service Bus and how to fix them. We will look at simpler errors, the ones you get if configurations on your code are wrong, or you’ve not declared the modules properly; then we will have a quick look at Dead Letters and what they represent.
This is the last part of the series about Azure Service Bus. In the previous parts, we’ve seen
For this article, we’re going to introduce some errors in the code we used in the previous examples.
Just to recap the context, our system receives orders for some pizzas via HTTP APIs, processes them by putting some messages on a Topic on Azure Service Bus. Then, a different application that is listening for notifications on the Topic, reads the message and performs some dummy operations.
Common exceptions with .NET SDK
To introduce the exceptions, we’d better keep at hand the code we used in the previous examples.
Let’s recall that a connection string has a form like this:
To send a message in the Queue, remember that we have 3 main steps:
create a new ServiceBusClient instance using the connection string
create a new ServiceBusSender specifying the name of the queue or topic (in our case, the Topic)
send the message by calling the SendMessageAsync method
awaitusing (ServiceBusClient client = new ServiceBusClient(ConnectionString))
{
ServiceBusSender sender = client.CreateSender(TopicName);
foreach (var order in validOrders)
{
/// Create Bus Message ServiceBusMessage serializedContents = CreateServiceBusMessage(order);
// Send the message on the Busawait sender.SendMessageAsync(serializedContents);
}
}
To receive messages from a Topic, we need the following steps:
create a new ServiceBusClient instance as we did before
create a new ServiceBusProcessor instance by specifying the name of the Topic and of the Subscription
Of course, I recommend reading the previous articles to get a full understanding of the examples.
Now it’s time to introduce some errors and see what happens.
No such host is known
When the connection string is invalid because the host name is wrong, you get an Azure.Messaging.ServiceBus.ServiceBusException exception with this message: No such host is known. ErrorCode: HostNotFound.
What is the host? It’s the first part of the connection string. For example, in a connection string like
So we can easily understand why this error happens: that host name does not exist (or, more probably, there’s a typo).
A curious fact about this exception: it is thrown later than I expected. I was expecting it to be thrown when initializing the ServiceBusClient instance, but it is actually thrown only when a message is being sent using SendMessageAsync.
You can perform all the operations you want without receiving any error until you really access the resources on the Bus.
Put token failed: The messaging entity X could not be found
Another message you may receive is Put token failed. status-code: 404, status-description: The messaging entity ‘X’ could not be found.
The reason is pretty straightforward: the resource you are trying to use does not exist: by resource I mean Queue, Topic, and Subscription.
Again, that exception is thrown only when interacting directly with Azure Service Bus.
Put token failed: the token has an invalid signature
If the connection string is not valid because of invalid SharedAccessKeyName or SharedAccessKey, you will get an exception of type System.UnauthorizedAccessException with the following message: Put token failed. status-code: 401, status-description: InvalidSignature: The token has an invalid signature.
The best way to fix it is to head to the Azure portal and copy again the credentials, as I explained in the introductory article.
Cannot begin processing without ProcessErrorAsync handler set.
Let’s recall a statement from my first article about Azure Service Bus:
The PizzaItemErrorHandler, however, must be at least declared, even if empty: you will get an exception if you forget about it.
That’s odd, but that’s true: you have to define handlers both for manage success and failure.
If you don’t, and you only declare the ProcessMessageAsync handler, like in this example:
and acts as a catch block for the receivers: all the errors we’ve thrown in the first part of the article can be handled here. Of course, we are not directly receiving an instance of Exception, but we can access it by navigating the arg object.
As an example, let’s update again the host part of the connection string. When running the application, we can see that the error is caught in the PizzaItemErrorHandler method, and the arg argument contains many fields that we can use to handle the error. One of them is Exception, which wraps the Exception types we’ve already seen.
This means that in this method you have to define your error handling, add logs, and whatever may help your application managing errors.
The same handler can be used to manage errors that occur while performing operations on a message: if an exception is thrown when processing an incoming message, you have two choices: handle it in the ProcessMessageAsync handler, in a try-catch block, or leave the error handling on the ProcessErrorAsync handler.
In the above picture, I’ve simulated an error while processing an incoming message by throwing a new DivideByZeroException. As a result, the PizzaItemErrorHandler method is called, and the arg argument contains info about the thrown exception.
I personally prefer separating the two error handling situations: in the ProcessMessageAsync method I handle errors that occur in the business logic, when operating on an already received message; in the ProcessErrorAsync method I handle error coming from the infrastructure, like errors in the connection string, invalid credentials and so on.
Dead Letters: when messages become stale
When talking about queues, you’ll often come across the term dead letter. What does it mean?
Dead letters are unprocessed messages: messages die when a message cannot be processed for a certain period of time. You can ignore that message because it has become obsolete or, anyway, it cannot be processed – maybe because it is malformed.
Messages like these are moved to a specific queue called Dead Letter Queue (DLQ): messages are moved here to avoid making the normal queue full of messages that will never be processed.
You can see which messages are present in the DLQ to try to understand the reason they failed and put them again into the main queue.
in the above picture, you can see how the DLQ can be navigated using Service Bus Explorer: you can see all the messages in the DLQ, update them (not only the content, but even the associated metadata), and put them again into the main Queue to be processed.
Wrapping up
In this article, we’ve seen some of the errors you can meet when working with Azure Service Bus and .NET.
We’ve seen the most common Exceptions, how to manage them both on the Sender and the Receiver side: on the Receiver you must handle them in the ProcessErrorAsync handler.
Finally, we’ve seen what is a Dead Letter, and how you can recover messages moved to the DLQ.
This is the last part of this series about Azure Service Bus and .NET: there’s a lot more to talk about, like dive deeper into DLQ and understanding Retry Patterns.
Debugging our .NET applications can be cumbersome. With the DebuggerDisplay attribute we can simplify it by displaying custom messages.
Table of Contents
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
Picture this: you are debugging a .NET application, and you need to retrieve a list of objects. To make sure that the items are as you expect, you need to look at the content of each item.
For example, you are retrieving a list of Movies – an object with dozens of fields – and you are interested only in the Title and VoteAverage fields. How to view them while debugging?
There are several options: you could override ToString, or use a projection and debug the transformed list. Or you could use the DebuggerDisplay attribute to define custom messages that will be displayed on Visual Studio. Let’s see what we can do with this powerful – yet ignored – attribute!
Simplify debugging by overriding ToString
Let’s start with the definition of the Movie object:
This is quite a small object, but yet it can become cumbersome to view the content of each object while debugging.
As you can see, to view the content of the items you have to open them one by one. When there are only 3 items like in this example, it still can be fine. But when working with tens of items, that’s not a good idea.
Notice what is the default text displayed by Visual Studio: does it ring you a bell?
By default, the debugger shows you the ToString() of every object. So an idea is to override that method to view the desired fields.
This override allows us to see the items in a much better way:
So, yes, this could be a way to achieve this result.
Using LINQ
Another way to achieve the same result is by using LINQ. Almost every C# developer has
already used it, so I won’t explain what it is and what you can do with LINQ.
By the way, one of the most used methods is Select: it takes a list of items and, by applying a function, returns the result of that function applied to each item in the list.
So, we can create a list of strings that holds the info relevant to us, and then use the debugger to view the content of that list.
The fields to be displayed are wrapped in { and }: it’s "{Title}", not "Title";
The names must match with the ones of the fields;
You are viewing the ToString() representation of each displayed field (notice the VoteAverage field, which is a double);
When debugging, you don’t see the names of the displayed fields;
You can write whatever you want, not only the fields name (see the hyphen between the fields)
The 5th point brings us to another example: adding custom text to the display attribute:
[DebuggerDisplay("Title: {Title} - Average Vote: {VoteAverage}")]
So we can customize the content as we want.
What if you rename a field? Since the value of the attribute is a simple string, it will not notice any update, so you’ll miss that field (it does not match any object field, so it gets used as a simple text).
To avoid this issue you can simply use string concatenation and the nameof expression:
You can get rid of quotes by adding nq to the string: add that modifier to every string you want to escape, and it will remove the quotes (in fact, nq stands for no-quotes).
In this way, we achieve the same result, and we have the help of the Intellisense in case our expression is not valid.
Why not overriding ToString or using LINQ?
Ok, DebuggerDisplay is neat and whatever. But why can’t we use LINQ, or override ToString?
That’s because of the side effect of those two approaches.
By overriding the ToString method you are changing its behavior all over the application. This means that, if somewhere you print on console that object (like in Console.WriteLine(movie)), the result will be the one defined in the ToString method.
By using the LINQ approach you are performing “useless” operations: every time you run the application, even without the debugger attached, you will perform the transformation on every object in the collection.This is fine if your collection has 3 elements, but it can cause performance issues on huge collections.
That’s why you should use the DebuggerDisplay attribute: it has no side effects on your application, both talking about results and performance – it will only be used when debugging.
In this article, we’ve seen how the DebuggerDisplay attribute provided by .NET is useful to perform smarter and easier debugging sessions.
With this Attribute, you can display custom messages to watch the state of an object, and even see the state of nested fields.
We’ve seen that you can customize the message in several ways, like by calling ToUpper on the string result. We’ve also seen that for complex messages you should consider creating a new internal field whose sole purpose is to be used during debugging sessions.
After a series of commercial projects that were more practical than playful, I decided to use my portfolio site as a space to experiment with new ideas. My goals were clear: one, it had to be interactive and contain 3D elements. Two, it needed to capture your attention. Three, it had to perform well across different devices.
How did the idea for my site come about? Everyday moments. In the toilet, to be exact. My curious 20-month-old barged in when I was using the toilet one day and gleefully unleashed a long trail of toilet paper across the floor. The scene was chaotic, funny and oddly delightful to watch. As the mess grew, so did the idea: this kind of playful, almost mischievous, interaction with an object could be reimagined as a digital experience.
Of course, toilet paper wasn’t quite the right fit for the aesthetic, so the idea pivoted to duct tape. Duct tape was cooler and more in tune with the energy the project needed. With the concept locked in, the process moved to sketching, designing and coding.
Design Principles
With duct tape unraveling across the screen, things could easily feel chaotic and visually heavy. To balance that energy, the interface was kept intentionally simple and clean. The goal was to let the visuals take center stage while giving users plenty of white space to wander and play.
There’s also a layer of interaction woven into the experience. Animations respond to user actions, creating a sense of movement and interactivity. Hidden touches, like the option to rewind, orbit around elements, or a blinking dot that signals unseen projects.
Hitting spacebar rewinds the roll so that it can draw a new path again.
Hitting the tab key unlocks an orbit view, allowing the scene to be explored from different angles.
Building the Experience
Building an immersive, interactive portfolio is one thing. Making it perform smoothly across devices is another. Nearly 70% of the effort went into refining the experience and squeezing out every drop of performance. The result is a site that feels playful on the surface, but under the hood, it’s powered by a series of systems built to keep things fast, responsive, and accessible.
01. Real-time path drawing
The core magic lies in real-time path drawing. Mouse or touch movements are captured and projected into 3D space through raycasting. Points are smoothed with Catmull-Rom curves to create flowing paths that feel natural as they unfold. Geometry is generated on the fly, giving each user a unique drawing that can be rewound, replayed, or explored from different angles.
02. BVH raycasting
To keep those interactions fast, BVH raycasting steps in. Instead of testing every triangle in a scene, the system checks larger bounding boxes first, reducing thousands of calculations to just a few. Normally reserved for game engines, this optimization brings complex geometry into the browser at smooth 60fps.
// First, we make our geometry "smart" by adding BVH acceleration
useEffect(() => {
if (planeRef.current && !bvhGenerated.current) {
const plane = planeRef.current
// Step 1: Create a BVH tree structure for the plane
const generator = new StaticGeometryGenerator(plane)
const geometry = generator.generate()
// Step 2: Build the acceleration structure
geometry.boundsTree = new MeshBVH(geometry)
// Step 3: Replace the old geometry with the BVH-enabled version
if (plane.geometry) {
plane.geometry.dispose() // Clean up old geometry
}
plane.geometry = geometry
// Step 4: Enable fast raycasting
plane.raycast = acceleratedRaycast
bvhGenerated.current = true
}
}, [])
03. LOD + dynamic device detection
The system detects the capabilities of each device, GPU power, available memory, even CPU cores, and adapts quality settings on the fly. High-end machines get the full experience, while mobile devices enjoy a leaner version that still feels fluid and engaging.
const [isLowResMode, setIsLowResMode] = useState(false)
const [isVeryLowResMode, setIsVeryLowResMode] = useState(false)
// Detect low-end devices and enable low-res mode
useEffect(() => {
const detectLowEndDevice = () => {
const isMobile = /Android|webOS|iPhone|iPad|iPod|BlackBerry|IEMobile|Opera Mini/i.test(navigator.userAgent)
const isLowMemory = (navigator as any).deviceMemory && (navigator as any).deviceMemory < 4
const isLowCores = (navigator as any).hardwareConcurrency && (navigator as any).hardwareConcurrency < 4
const isSlowGPU = /(Intel|AMD|Mali|PowerVR|Adreno)/i.test(navigator.userAgent) && !/(RTX|GTX|Radeon RX)/i.test(navigator.userAgent)
const canvas = document.createElement('canvas')
const gl = canvas.getContext('webgl') || canvas.getContext('experimental-webgl') as WebGLRenderingContext | null
let isLowEndGPU = false
let isVeryLowEndGPU = false
if (gl) {
const debugInfo = gl.getExtension('WEBGL_debug_renderer_info')
if (debugInfo) {
const renderer = gl.getParameter(debugInfo.UNMASKED_RENDERER_WEBGL)
isLowEndGPU = /(Mali-4|Mali-T|PowerVR|Adreno 3|Adreno 4|Intel HD|Intel UHD)/i.test(renderer)
isVeryLowEndGPU = /(Mali-4|Mali-T6|Mali-T7|PowerVR G6|Adreno 3|Adreno 4|Intel HD 4000|Intel HD 3000|Intel UHD 600)/i.test(renderer)
}
}
const isVeryLowMemory = (navigator as any).deviceMemory && (navigator as any).deviceMemory < 2
const isVeryLowCores = (navigator as any).hardwareConcurrency && (navigator as any).hardwareConcurrency < 2
const shouldEnableVeryLowRes = isVeryLowMemory || isVeryLowCores || isVeryLowEndGPU
if (shouldEnableVeryLowRes) {
setIsVeryLowResMode(true)
setIsLowResMode(true)
} else if (isMobile || isLowMemory || isLowCores || isSlowGPU || isLowEndGPU) {
setIsLowResMode(true)
}
}
detectLowEndDevice()
}, [])
04. Keep-alive frame system + throttled geometry updates
To ensures smooth performance without draining batteries or overloading CPUs. Frames render only when needed, then hold a steady rhythm after interaction to keep everything responsive. It’s this balance between playfulness and precision that makes the site feel effortless for the user.
The Creator
Lax Space is a combination of my name, Lax, and a Space dedicated to creativity. It’s both a portfolio and a playground, a hub where design and code meet in a fun, playful and stress-free way.
Originally from Singapore, I embarked on creative work there before relocating to Japan. My aims were simple: explore new ideas, learn from different perspectives and challenge old ways of thinking. Being surrounded by some of the most inspiring creators from Japan and beyond has pushed my work further creatively and technologically.
Design and code form part of my toolkit, and blending them together makes it possible to craft experiences that balance function with aesthetics. Every project is a chance to try something new, experiment and push the boundaries of digital design.
I am keen to connecting with other creatives. If something at Lax Space piques your interest, let’s chat!
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
One of the most common issues we face when developing applications is handling dates, times, and time zones.
Let’s say that we need the date for January 1st, 2020, exactly 30 minutes after midnight. We would be tempted to do something like:
var plainDate = new DateTime(2020, 1, 1, 0, 30, 0);
It makes sense. And plainDate.ToString() returns 2020/1/1 0:30:00, which is correct.
But, as I explained in a previous article, while ToString does not care about time zone, when you use ToUniversalTime and ToLocalTime, the results differ, according to your time zone.
Let’s use a real example. Please, note that I live in UTC+1, so pay attention to what happens to the hour!
var plainDate = new DateTime(2020, 1, 1, 0, 30, 0);
Console.WriteLine(plainDate); // 2020-01-01 00:30:00Console.WriteLine(plainDate.ToUniversalTime()); // 2019-12-31 23:30:00Console.WriteLine(plainDate.ToLocalTime()); // 2020-01-01 01:30:00
This means that ToUniversalTime considers plainDate as Local, so, in my case, it subtracts 1 hour.
On the contrary, ToLocalTime considers plainDate as UTC, so it adds one hour.
So what to do?
Always specify the DateTimeKind parameter when creating DateTimes__. This helps the application understanding which kind of date is it managing.
var specificDate = new DateTime(2020, 1, 1, 0, 30, 0, DateTimeKind.Utc);
Console.WriteLine(specificDate); //2020-01-01 00:30:00Console.WriteLine(specificDate.ToUniversalTime()); //2020-01-01 00:30:00Console.WriteLine(specificDate.ToLocalTime()); //2020-01-01 00:30:00
As you see, it’s always the same date.
Ah, right! DateTimeKind has only 3 possible values:
publicenum DateTimeKind
{
Unspecified,
Utc,
Local
}
So, my suggestion is to always specify the DateTimeKind parameter when creating a new DateTime.
You should not add the caching logic in the same component used for retrieving data from external sources: you’d better use the Decorator Pattern. We’ll see how to use it, what benefits it brings to your application, and how to use Scrutor to add it to your .NET projects.
Table of Contents
Just a second! 🫷 If you are here, it means that you are a software developer.
So, you know that storage, networking, and domain management have a cost .
If you want to support this blog, please ensure that you have disabled the adblocker for this site. I configured Google AdSense to show as few ADS as possible – I don’t want to bother you with lots of ads, but I still need to add some to pay for the resources for my site.
Thank you for your understanding. – Davide
When fetching external resources – like performing a GET on some remote APIs – you often need to cache the result. Even a simple caching mechanism can boost the performance of your application: the fewer actual calls to the external system, the faster the response time of the overall application.
We should not add the caching layer directly to the classes that get the data we want to cache, because it will make our code less extensible and testable. On the contrary, we might want to decorate those classes with a specific caching layer.
In this article, we will see how we can use the Decorator Pattern to add a cache layer to our repositories (external APIs, database access, or whatever else) by using Scrutor, a NuGet package that allows you to decorate services.
Before understanding what is the Decorator Pattern and how we can use it to add a cache layer, let me explain the context of our simple application.
We are exposing an API with only a single endpoint, GetBySlug, which returns some data about the RSS item with the specified slug if present on my blog.
That interface is implemented by the RssFeedReader class, which uses the SyndicationFeed class (that comes from the System.ServiceModel.Syndication namespace) to get the correct item from my RSS feed:
publicclassRssFeedReader : IRssFeedReader
{
public RssItem GetItem(string slug)
{
var url = "https://www.code4it.dev/rss.xml";
using var reader = XmlReader.Create(url);
var feed = SyndicationFeed.Load(reader);
SyndicationItem item = feed.Items.FirstOrDefault(item => item.Id.EndsWith(slug));
if (item == null)
returnnull;
returnnew RssItem
{
Title = item.Title.Text,
Url = item.Links.First().Uri.AbsoluteUri,
Source = "RSS feed" };
}
}
When we run the application and try to find an article I published, we retrieve the data directly from the RSS feed (as you can see from the value of Source).
The application is quite easy, right?
Let’s translate it into a simple diagram:
The sequence diagram is simple as well- it’s almost obvious!
Now it’s time to see what is the Decorator pattern, and how we can apply it to our situation.
Introducing the Decorator pattern
The Decorator pattern is a design pattern that allows you to add behavior to a class at runtime, without modifying that class. Since the caller works with interfaces and ignores the type of the concrete class, it’s easy to “trick” it into believing it is using the simple class: all we have to do is to add a new class that implements the expected interface, make it call the original class, and add new functionalities to that.
Quite confusing, uh?
To make it easier to understand, I’ll show you a simplified version of the pattern:
In short, the Client needs to use an IService. Instead of passing a BaseService to it (as usual, via Dependency Injection), we pass the Client an instance of DecoratedService (which implements IService as well). DecoratedService contains a reference to another IService (this time, the actual type is BaseService), and calls it to perform the doSomething operation. But DecoratedService not only calls IService.doSomething(), but enriches its behavior with new capabilities (like caching, logging, and so on).
In this way, our services are focused on a single aspect (Single Responsibility Principle) and can be extended with new functionalities (Open-close Principle).
Enough theory! There are plenty of online resources about the Decorator pattern, so now let’s see how the pattern can help us adding a cache layer.
Ah, I forgot to mention that the original pattern defines another object between IService and DecoratedService, but it’s useless for the purpose of this article, so we are fine anyway.
Implementing the Decorator with Scrutor
Have you noticed that we almost have all our pieces already in place?
If we compare the Decorator pattern objects with our application’s classes can notice that:
Client corresponds to our RssInfoController controller: it’s the one that calls our services
IService corresponds to IRssFeedReader: it’s the interface consumed by the Client
BaseService corresponds to RssFeedReader: it’s the class that implements the operations from its interface, and that we want to decorate.
So, we need a class that decorates RssFeedReader. Let’s call it CachedFeedReader: it checks if the searched item has already been processed, and, if not, calls the decorated class to perform the base operation.
There are a few points you have to notice in the previous snippet:
this class implements the IRssFeedReader interface;
we are passing an instance of IRssFeedReader in the constructor, which is the class that we are decorating;
we are performing other operations both before and after calling the base operation (so, calling _rssFeedReader.GetItem(slug));
we are setting the value of the Source property to Cache if the object is already in cache – its value is RSS feed the first time we retrieve this item;
Open your project and install it via UI or using the command line by running dotnet add package Scrutor.
Now head to the ConfigureServices method and use the Decorate extension method to decorate a specific interface with a new service:
services.AddSingleton<IRssFeedReader, RssFeedReader>(); // this one was already presentservices.Decorate<IRssFeedReader, CachedFeedReader>(); // add a new decorator to IRssFeedReader
… and that’s it! You don’t have to update any other classes; everything is transparent for the clients.
If we run the application again, we can see that the first call to the endpoint returns the data from the RSS Feed, and all the followings return data from the cache.
We can now update our class diagram to add the new CachedFeedReader class
And, of course, the sequence diagram changed a bit too.
Benefits of the Decorator pattern
Using the Decorator pattern brings many benefits.
Every component is focused on only one thing: we are separating responsibilities across different components so that every single component does only one thing and does it well. RssFeedReader fetches RSS data, CachedFeedReader defines caching mechanisms.
Every component is easily testable: we can test our caching strategy by mocking the IRssFeedReader dependency, without the worrying of the concrete classes called by the RssFeedReader class. On the contrary, if we put cache and RSS fetching functionalities in the RssFeedReader class, we would have many troubles testing our caching strategies, since we cannot mock the XmlReader.Create and SyndicationFeed.Load methods.
We can easily add new decorators: say that we want to log the duration of every call. Instead of putting the logging in the RssFeedReader class or in the CachedFeedReader class, we can simply create a new class that implements IRssFeedReader and add it to the list of decorators.
An example of Decorator outside the programming world? The following video from YouTube, where you can see that each cup (component) has only one responsibility, and can be easily decorated with many other cups.
In this article, we’ve seen that the Decorator pattern allows us to write better code by focusing each component on a single task and by making them easy to compose and extend.
We’ve done it thanks to Scrutor, a NuGet package that allows you to decorate services with just a simple configuration.
I’ve always been interested in data visualization using Three.js / R3F, and I thought a weather web app would be the perfect place to start. One of my favorite open-source libraries, @react-three/drei, already has a bunch of great tools like clouds, sky, and stars that fit perfectly into visualizing the weather in 3D.
This tutorial explores how to transform API data into a 3D experience, where we add a little flair and fun to weather visualization.
The Technology Stack
Our weather world is built on a foundation of some of my favorite technologies:
Weather Components
The heart of our visualization lies in conditionally showing a realistic sun, moon, and/or clouds based on the weather
results from your city or a city you search for, particles that simulate rain or snow, day/night logic, and some fun
lighting effects during a thunderstorm. We’ll start by building these weather components and then move on to displaying
them based on the results of the WeatherAPI call.
Sun + Moon Implementation
Let’s start simple: we’ll create a sun and moon component that’s just a sphere with a realistic texture wrapped
around it. We’ll also give it a little rotation and some lighting.
// Sun.js and Moon.js Component, a texture wrapped sphere
import React, { useRef } from 'react';
import { useFrame, useLoader } from '@react-three/fiber';
import { Sphere } from '@react-three/drei';
import * as THREE from 'three';
const Sun = () => {
const sunRef = useRef();
const sunTexture = useLoader(THREE.TextureLoader, '/textures/sun_2k.jpg');
useFrame((state) => {
if (sunRef.current) {
sunRef.current.rotation.y = state.clock.getElapsedTime() * 0.1;
}
});
const sunMaterial = new THREE.MeshBasicMaterial({
map: sunTexture,
});
return (
<group position={[0, 4.5, 0]}>
<Sphere ref={sunRef} args={[2, 32, 32]} material={sunMaterial} />
{/* Sun lighting */}
<pointLight position={[0, 0, 0]} intensity={2.5} color="#FFD700" distance={25} />
</group>
);
};
export default Sun;
I grabbed the CC0 texture from here. The moon component is essentially the same; I used this image. The pointLight intensity is low because most of our lighting will come from the sky.
Rain: Instanced Cylinders
Next, let’s create a rain particle effect. To keep things performant, we’re going to use instancedMesh instead of creating a separate mesh component for each rain particle. We’ll render a single geometry (<cylinderGeometry>) multiple times with different transformations (position, rotation, scale). Also, instead of creating a new THREE.Object3D for each particle in every frame, we’ll reuse a single dummy object. This saves memory and prevents the overhead of creating and garbage-collecting a large number of temporary objects within the animation loop. We’ll also use the useMemo hook to create and initialize the particles array only once when the component mounts.
When a particle reaches a negative Y-axis level, it’s immediately recycled to the top of the scene with a new random horizontal position, creating the illusion of continuous rainfall without constantly creating new objects.
Snow: Physics-Based Tumbling
We’ll use the same basic template for the snow effect, but instead of the particles falling straight down, we’ll give them some drift.
The horizontal drift uses Math.sin(state.clock.elapsedTime + i), where state.clock.elapsedTime provides a continuously increasing time value and i offsets each particle’s timing. This creates a natural swaying motion in which each snowflake follows its own path. The rotation updates apply small increments to both the X and Y axes, creating the tumbling effect.
Storm System: Multi-Component Weather Events
When a storm rolls in, I wanted to simulate dark, brooding clouds and flashes of lightning. This effect requires combining multiple weather effects simultaneously. We’ll import our rain component, add some clouds, and implement a lightning effect with a pointLight that simulates flashes of lightning coming from inside the clouds.
The lightning system uses a simple ref-based cooldown mechanism to prevent constant flashing. When lightning triggers, it creates a single bright flash with random positioning. The system uses setTimeout to reset the light intensity after 400ms, creating a realistic lightning effect without complex multi-stage sequences.
Clouds: Drei Cloud
For weather types like cloudy, partly cloudy, overcast, foggy, rainy, snowy, and misty, we’ll pull in our clouds component. I wanted the storm component to have its own clouds because storms should have darker clouds than the conditions above. The clouds component will simply display Drei clouds, and we’ll pull it all together with the sun or moon component in the next section.
Now that we’ve built our weather components, we need a system to decide which ones to display based on real weather data. The WeatherAPI.com service provides detailed current conditions that we’ll transform into our 3D scene parameters. The API gives us condition text like “Partly cloudy,” “Thunderstorm,” or “Light snow,” but we need to convert these into our component types.
// weatherService.js - Fetching real weather data
const response = await axios.get(
`${WEATHER_API_BASE}/forecast.json?key=${API_KEY}&q=${location}&days=3&aqi=no&alerts=no&tz=${Intl.DateTimeFormat().resolvedOptions().timeZone}`,
{ timeout: 10000 }
);
The API request includes time zone information so we can accurately determine day or night for our Sun/Moon system. The days=3 parameter grabs forecast data for our portal feature, while aqi=no&alerts=no keeps the payload lean by excluding data we don’t need.
Converting API Conditions to Component Types
The heart of our system is a simple parsing function that maps hundreds of possible weather descriptions to our manageable set of visual components:
// weatherService.js - Converting weather text to renderable types
export const getWeatherConditionType = (condition) => {
const conditionLower = condition.toLowerCase();
if (conditionLower.includes('sunny') || conditionLower.includes('clear')) {
return 'sunny';
}
if (conditionLower.includes('thunder') || conditionLower.includes('storm')) {
return 'stormy';
}
if (conditionLower.includes('cloud') || conditionLower.includes('overcast')) {
return 'cloudy';
}
if (conditionLower.includes('rain') || conditionLower.includes('drizzle')) {
return 'rainy';
}
if (conditionLower.includes('snow') || conditionLower.includes('blizzard')) {
return 'snowy';
}
// ... additional fog and mist conditions
return 'cloudy';
};
This string-matching approach handles edge cases gracefully—whether the API returns “Light rain,” “Heavy rain,” or “Patchy light drizzle,” they all map to our rainy type and trigger the appropriate 3D effects. This way, we can reuse our main components without needing a separate component for each weather condition.
Conditional Component Rendering
The magic happens in our WeatherVisualization component, where the parsed weather type determines exactly which 3D components to render:
// WeatherVisualization.js - Bringing weather data to life
const renderWeatherEffect = () => {
if (weatherType === 'sunny') {
if (partlyCloudy) {
return (
<>
{isNight ? <Moon /> : <Sun />}
<Clouds intensity={0.5} speed={0.1} />
</>
);
}
return isNight ? <Moon /> : <Sun />;
} else if (weatherType === 'rainy') {
return (
<>
<Clouds intensity={0.8} speed={0.15} />
<Rain count={800} />
</>
);
} else if (weatherType === 'stormy') {
return <Storm />; // Includes its own clouds, rain, and lightning
}
// ... additional weather types
};
This conditional system ensures we only load the particle systems we actually need. A sunny day renders just our Sun component, while a storm loads our complete Storm system with heavy rain, dark clouds, and lightning effects. Each weather type gets its own combination of the components we built earlier, creating distinct visual experiences that match the real weather conditions.
Dynamic Time-of-Day System
Weather isn’t just about conditions—it’s also about timing. Our weather components need to know whether to show the sun or moon, and we need to configure Drei’s Sky component to render the appropriate atmospheric colors for the current time of day. Fortunately, our WeatherAPI response already includes the local time for any location, so we can extract that to drive our day/night logic.
The API provides local time in a simple format that we can parse to determine the current period:
// Scene3D.js - Parsing time from weather API data
const getTimeOfDay = () => {
if (!weatherData?.location?.localtime) return 'day';
const localTime = weatherData.location.localtime;
const currentHour = new Date(localTime).getHours();
if (currentHour >= 19 || currentHour <= 6) return 'night';
if (currentHour >= 6 && currentHour < 8) return 'dawn';
if (currentHour >= 17 && currentHour < 19) return 'dusk';
return 'day';
};
This gives us four distinct time periods, each with different lighting and sky configurations. Now we can use these periods to configure Drei’s Sky component, which handles atmospheric scattering and generates realistic sky colors.
Dynamic Sky Configuration
Drei’s Sky component is fantastic because it simulates actual atmospheric physics—we just need to adjust atmospheric parameters for each time period:
// Scene3D.js - Time-responsive Sky configuration
{timeOfDay !== 'night' && (
<Sky
sunPosition={(() => {
if (timeOfDay === 'dawn') {
return [100, -5, 100]; // Sun below horizon for darker dawn colors
} else if (timeOfDay === 'dusk') {
return [-100, -5, 100]; // Sun below horizon for sunset colors
} else { // day
return [100, 20, 100]; // High sun position for bright daylight
}
})()}
inclination={(() => {
if (timeOfDay === 'dawn' || timeOfDay === 'dusk') {
return 0.6; // Medium inclination for transitional periods
} else { // day
return 0.9; // High inclination for clear daytime sky
}
})()}
turbidity={(() => {
if (timeOfDay === 'dawn' || timeOfDay === 'dusk') {
return 8; // Higher turbidity creates warm sunrise/sunset colors
} else { // day
return 2; // Lower turbidity for clear blue sky
}
})()}
/>
)}
The magic happens in the positioning. During dawn and dusk, we place the sun just below the horizon (-5 Y position) so Drei’s Sky component generates those warm orange and pink colors we associate with sunrise and sunset. The turbidity parameter controls atmospheric scattering, with higher values creating more dramatic color effects during transitional periods.
Nighttime: Simple Black Background + Stars
For nighttime, I made a deliberate choice to skip Drei’s Sky component entirely and use a simple black background instead. The Sky component can be computationally expensive, and for nighttime scenes, a pure black backdrop actually looks better and performs significantly faster. We complement this with Drei’s Stars component for that authentic nighttime atmosphere:
Drei’s Stars component creates 5,000 individual stars scattered across a 100-unit sphere with realistic depth variation. The saturation={0} keeps them properly desaturated for authentic nighttime visibility, while the gentle speed={1} creates subtle movement that simulates the natural motion of celestial bodies. Stars only appear during nighttime hours (7 PM to 6 AM) and automatically disappear at dawn, creating a smooth transition back to Drei’s daytime Sky component.
This approach gives us four distinct atmospheric moods—bright daylight, warm dawn colors, golden dusk tones, and star-filled nights—all driven automatically by the real local time from our weather data.
Forecast Portals: Windows Into Tomorrow’s Weather
Like any good weather app, we don’t want to just show current conditions but also what’s coming next. Our API returns a three-day forecast that we transform into three interactive portals hovering in the 3D scene, each one showing a preview of that day’s weather conditions. Click on a portal and you’re transported into that day’s atmospheric environment.
Building Portals with MeshPortalMaterial
The portals use Drei’s MeshPortalMaterial, which renders a complete 3D scene to a texture that gets mapped onto a plane. Each portal becomes a window into its own weather world:
The roundedPlaneGeometry from the maath library gives our portals those smooth, organic edges instead of sharp rectangles. The [2, 2.5, 0.15] parameters create a 2×2.5 unit portal with 0.15 radius corners, providing enough rounding to look visually appealing.
Interactive States and Animations
Portals respond to user interaction with smooth state transitions. The system tracks two primary states: inactive and fullscreen:
// ForecastPortals.js - State management and blend animations
const ForecastPortal = ({ position, dayData, isActive, isFullscreen, onEnter }) => {
const materialRef = useRef();
useFrame(() => {
if (materialRef.current) {
// Smooth blend animation - only inactive (0) or fullscreen (1)
const targetBlend = isFullscreen ? 1 : 0;
materialRef.current.blend = THREE.MathUtils.lerp(
materialRef.current.blend || 0,
targetBlend,
0.1
);
}
});
// Portal content and UI elements hidden in fullscreen mode
return (
<group position={position}>
<mesh onClick={onEnter}>
<roundedPlaneGeometry args={[2, 2.5, 0.15]} />
<MeshPortalMaterial ref={materialRef}>
<PortalScene />
</MeshPortalMaterial>
</mesh>
{!isFullscreen && (
<>
{/* Temperature and condition text only show in preview mode */}
<Text position={[-0.8, 1.0, 0.1]} fontSize={0.18} color="#FFFFFF">
{formatDay(dayData.date, index)}
</Text>
</>
)}
</group>
);
};
The blend property controls how much the portal takes over your view. At 0 (inactive), you see the portal as a framed window into the weather scene. At 1 (fullscreen), you’re completely transported inside that day’s weather environment. The THREE.MathUtils.lerp function creates smooth transitions between these two states when clicking in and out of portals.
Fullscreen Portal Experience
When you click a portal, it fills your entire view with that day’s weather. Instead of looking at tomorrow’s weather through a window, you’re standing inside it:
In fullscreen mode, the portal weather data drives the entire scene: the Sky component, lighting, and all weather effects now represent that forecasted day. You can orbit around inside tomorrow’s storm or bask in the gentle sunlight of the day after. When you exit (click outside the portal), the system smoothly transitions back to the current weather conditions.
The key insight is that each portal runs our same WeatherVisualization component but with forecast data instead of current conditions. The portalMode={true} prop optimizes the components for smaller render targets—fewer particles, simpler clouds, but the same conditional logic we built earlier.
Now that we’ve introduced portals, we need to update our weather components to support this optimization. Going back to our conditional rendering examples, we add the portalMode prop:
And our Clouds component is updated to render fewer, simpler clouds in portal mode:
// Clouds.js - Portal optimization
const Clouds = ({ intensity = 0.7, speed = 0.1, portalMode = false }) => {
if (portalMode) {
return (
<DreiClouds material={THREE.MeshLambertMaterial}>
{/* Only 2 centered clouds for portal preview */}
<Cloud segments={40} bounds={[8, 3, 3]} volume={8} position={[0, 4, -2]} />
<Cloud segments={35} bounds={[6, 2.5, 2.5]} volume={6} position={[2, 3, -3]} />
</DreiClouds>
);
}
// Full cloud system for main scene (6+ detailed clouds)
return <group>{/* ... full cloud configuration ... */}</group>;
};
This dramatically reduces both particle counts (87.5% fewer rain particles) and cloud complexity (a 67% reduction from 6 detailed clouds to 2 centered clouds), ensuring smooth performance when multiple portals show weather effects simultaneously.
Integration with Scene3D
The portals are positioned and managed in our main Scene3D component, where they complement the current weather visualization:
// Scene3D.js - Portal integration
<>
{/* Current weather in the main scene */}
<WeatherVisualization
weatherData={weatherData}
isLoading={isLoading}
/>
{/* Three-day forecast portals */}
<ForecastPortals
weatherData={weatherData}
isLoading={isLoading}
onPortalStateChange={handlePortalStateChange}
/>
</>
When you click a portal, the entire scene transitions to fullscreen mode, showing that day’s weather in complete detail. The portal system tracks active states and handles smooth transitions between preview and immersive modes, creating a seamless way to explore future weather conditions alongside the current atmospheric environment.
The portals transform static forecast numbers into explorable 3D environments. Instead of reading “Tomorrow: 75°, Partly Cloudy,” you see and feel the gentle drift of cumulus clouds with warm sunlight filtering through.
Adding Cinematic Lens Flares
Our Sun component looks great, but to really make it feel cinematic, I wanted to implement a subtle lens flare effect. For this, I’m using the R3F-Ultimate-Lens-Flare library (shoutout to Anderson Mancini), which I installed manually by following the repository’s instructions. While lens flares typically work best with distant sun objects rather than our close-up approach, I still think it adds a nice cinematic touch to the scene.
The lens flare system needs to be smart about when to appear. Just like our weather components, it should only show when it makes meteorological sense:
The key parameters create a realistic lens flare effect: glareSize and flareSize both at 1.68 give prominent but not overwhelming flares, while ghostScale={0.03} adds subtle lens reflection artifacts. The haloScale={3.88} creates that large atmospheric glow around the sun.
The lens flare connects to our weather system through a visibility function that determines when the sun should be visible:
// weatherService.js - When should we show lens flares?
export const shouldShowSun = (weatherData) => {
if (!weatherData?.current?.condition) return true;
const condition = weatherData.current.condition.text.toLowerCase();
// Hide lens flare when weather obscures the sun
if (condition.includes('overcast') ||
condition.includes('rain') ||
condition.includes('storm') ||
condition.includes('snow')) {
return false;
}
return true; // Show for clear, sunny, partly cloudy conditions
};
// Scene3D.js - Combining weather and time conditions
const showLensFlare = useMemo(() => {
if (isNight || !weatherData) return false;
return shouldShowSun(weatherData);
}, [isNight, weatherData]);
This creates realistic behavior where lens flares only appear during daytime clear weather. During storms, the sun (and its lens flare) is hidden by clouds, just like in real life.
Performance Optimizations
Since we’re rendering thousands of particles, multiple cloud systems, and interactive portals—sometimes simultaneously—it can get expensive. As mentioned above, all our particle systems use instanced rendering to draw thousands of raindrops or snowflakes in single GPU calls. Conditional rendering ensures we only load the weather effects we actually need: no rain particles during sunny weather, no lens flares during storms. However, there’s still a lot of room for optimization. The most significant improvement comes from our portal system’s adaptive rendering. We already discussed decreasing the number of clouds in portals above, but when multiple forecast portals show precipitation simultaneously, we dramatically reduce particle counts.
This prevents the less-than-ideal scenario of rendering 4 × 800 = 3,200 rain particles when all portals show rain. Instead, we get 800 + (3 × 100) = 1,100 total particles while maintaining the visual effect.
API Reliability and Caching
Beyond 3D performance, we need the app to work reliably even when the weather API is slow, down, or rate-limited. The system implements smart caching and graceful degradation to keep the experience smooth.
Intelligent Caching
Rather than hitting the API for every request, we cache weather responses for 10 minutes:
This gives users instant responses for recently searched locations and keeps the app responsive during API slowdowns.
Rate Limiting and Fallback
When users exceed our 15 requests per hour limit, the system smoothly switches to demo data instead of showing errors:
// weatherService.js - Graceful degradation
if (error.response?.status === 429) {
console.log('Too many requests');
return getDemoWeatherData(location);
}
The demo data includes time-aware day/night detection, so even the fallback experience shows proper lighting and sky colors based on the user’s local time.
Future Enhancements
There’s plenty of room to expand this weather world. Adding accurate moon phases would bring another layer of realism to nighttime scenes—right now our moon is perpetually full. Wind effects could animate vegetation or create drifting fog patterns, using the wind speed data we’re already fetching but not yet visualizing. Performance-wise, the current optimizations handle most scenarios well, but there’s still room for improvement, especially when all forecast portals show precipitation simultaneously.
Conclusion
Building this 3D weather visualization combined React Three Fiber with real-time meteorological data to create something beyond a traditional weather app. By leveraging Drei’s ready-made components alongside custom particle systems, we’ve transformed API responses into explorable atmospheric environments.
The technical foundation combines several key approaches:
Instanced rendering for particle systems that maintain 60fps while simulating thousands of raindrops
Conditional component loading that only renders the weather effects currently needed
Portal-based scene composition using MeshPortalMaterial for forecast previews
Time-aware atmospheric rendering with Drei’s Sky component responding to local sunrise and sunset
Smart caching and fallback systems that keep the experience responsive during API limitations
This was something I always wanted to build, and I had a ton of fun bringing it to life!






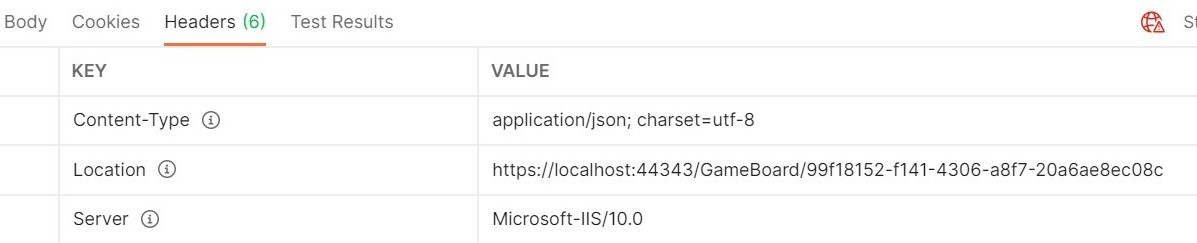
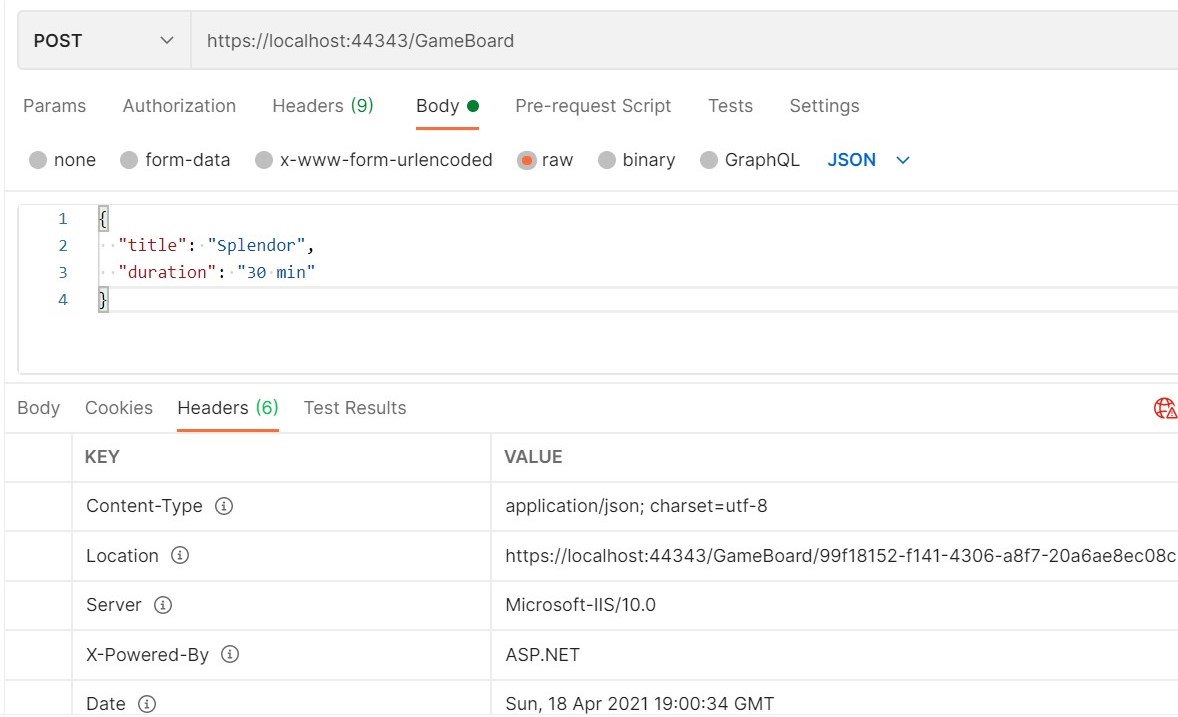
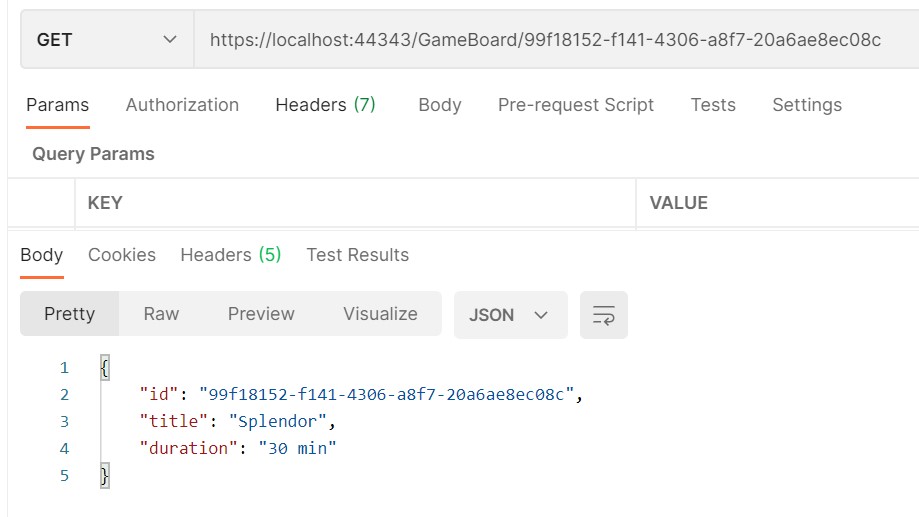

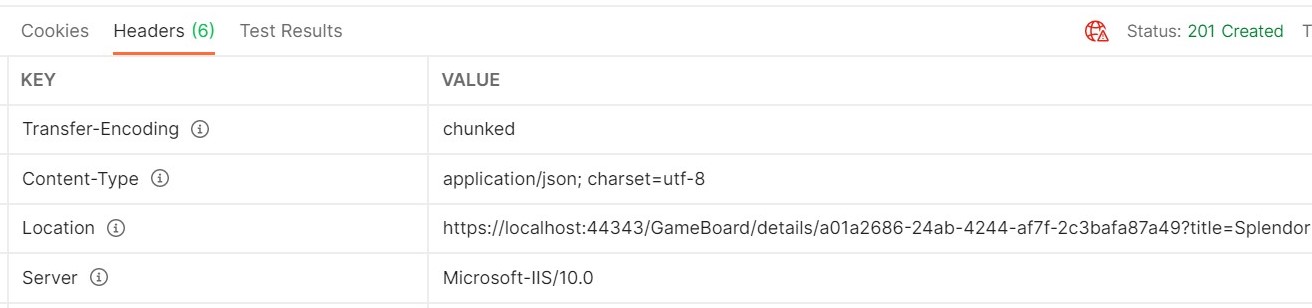
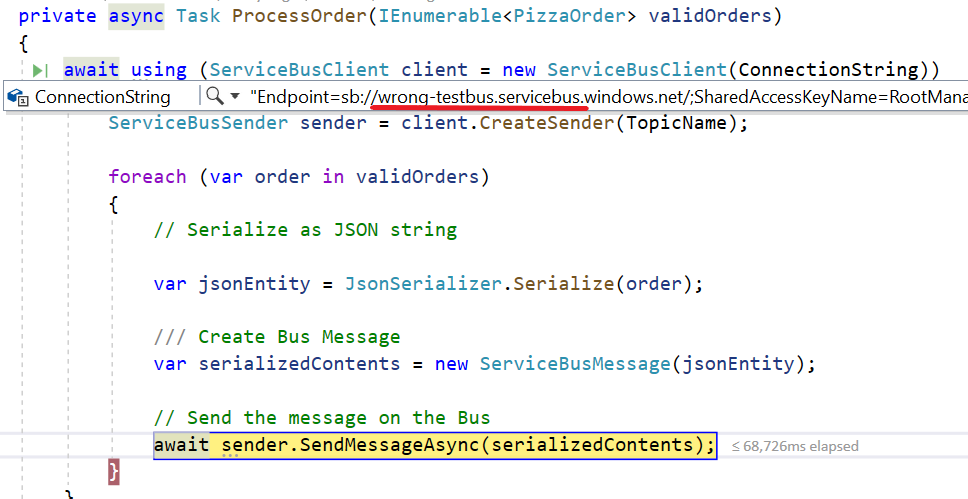
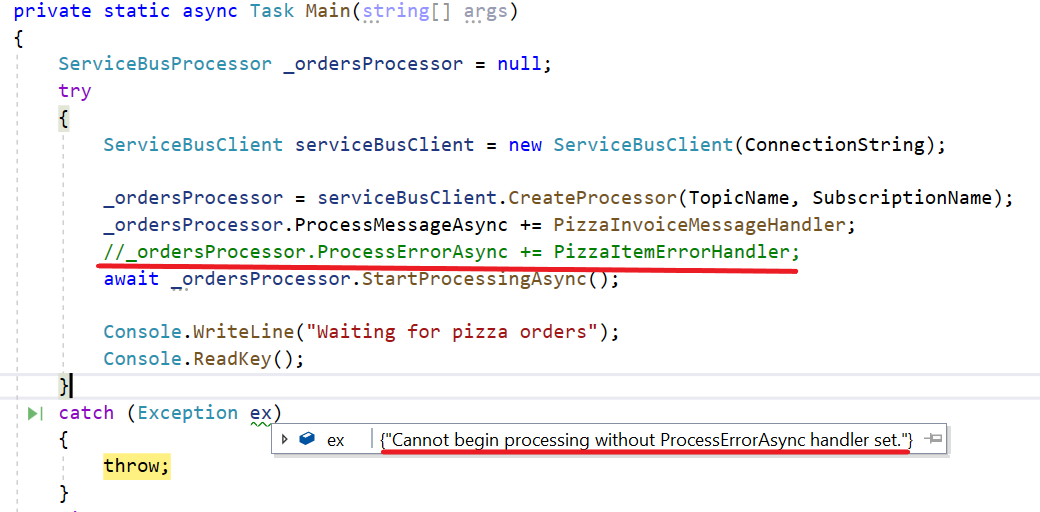
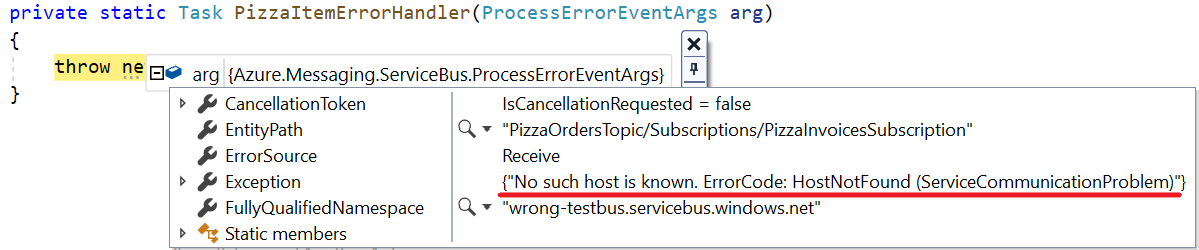
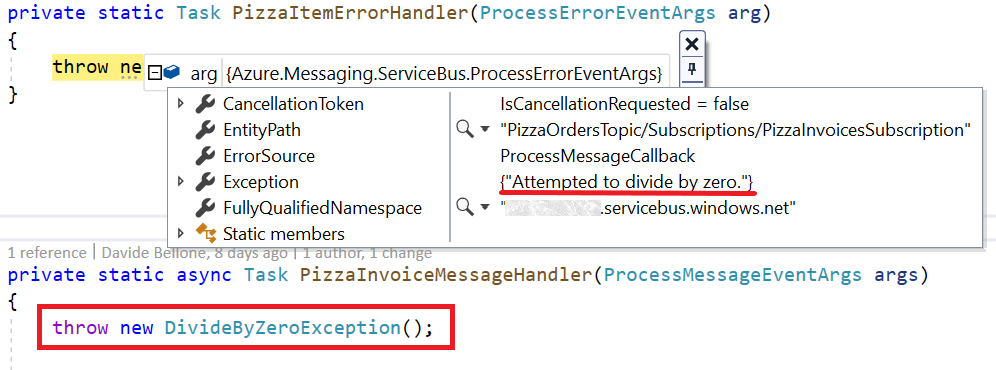
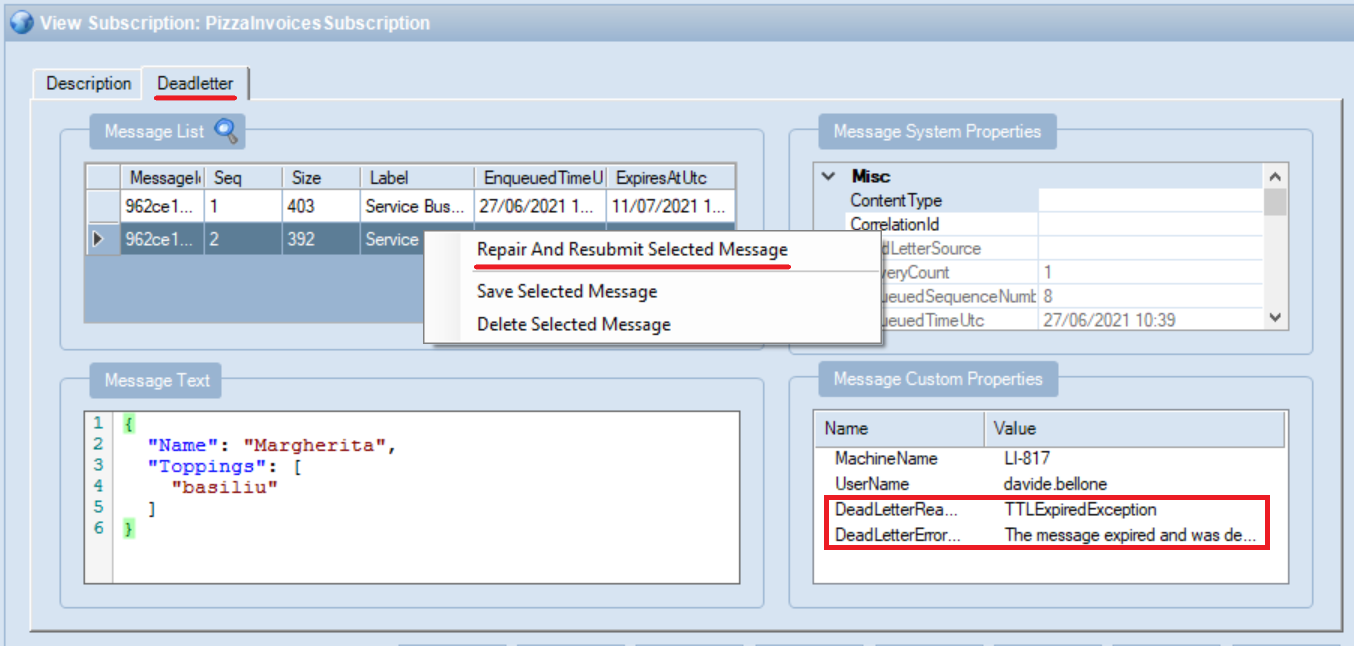
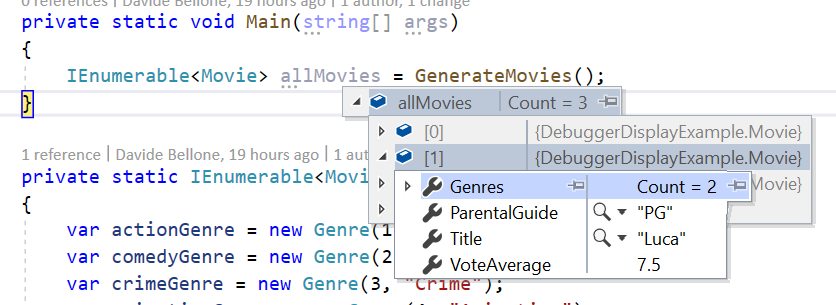
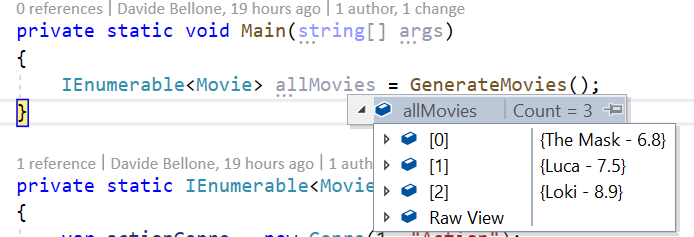
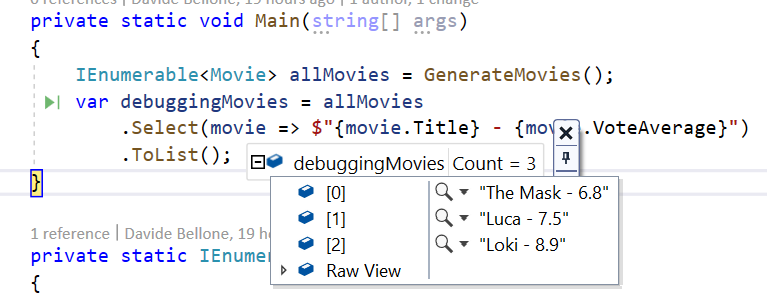
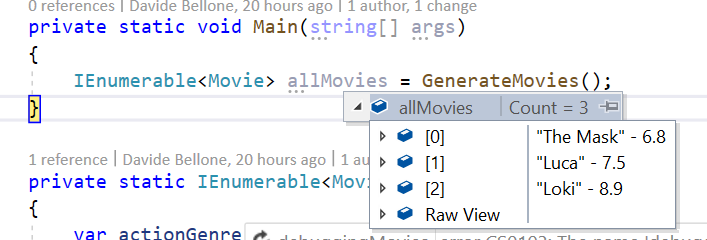
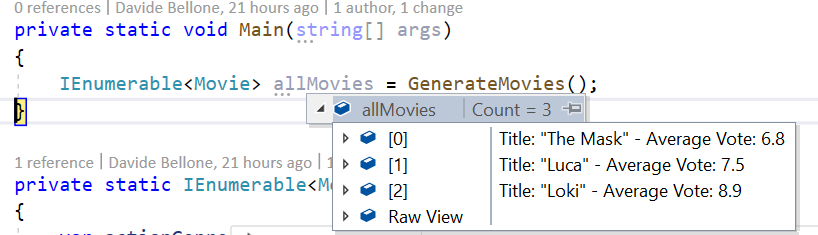
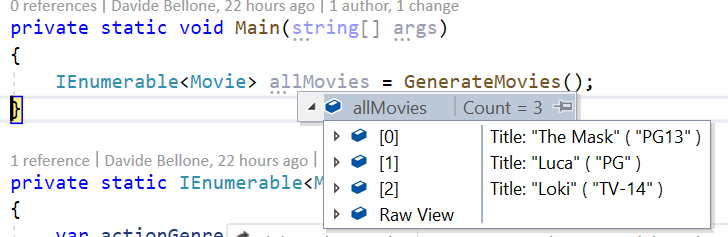
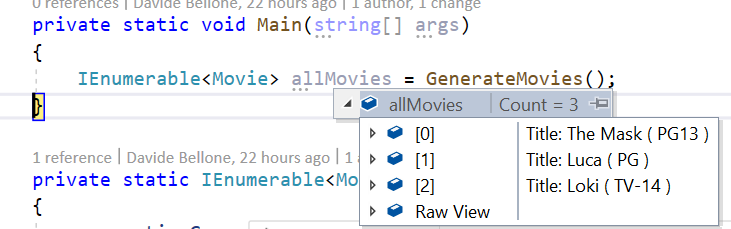
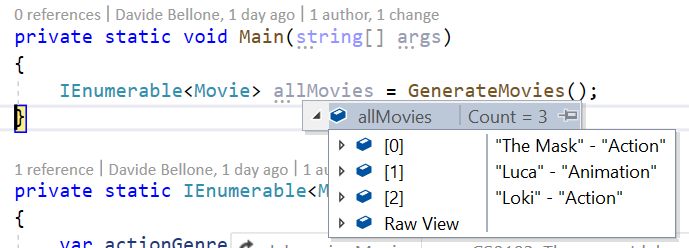
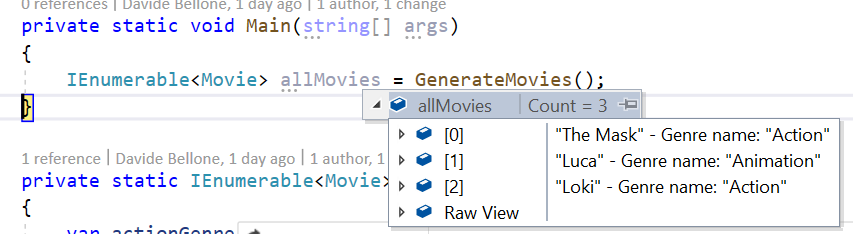



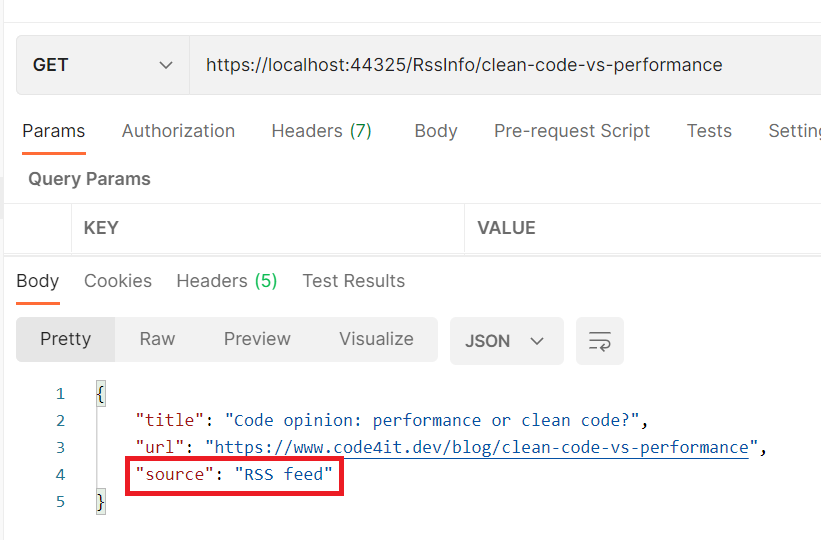
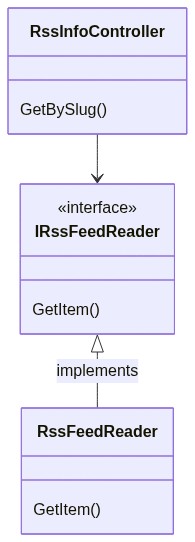
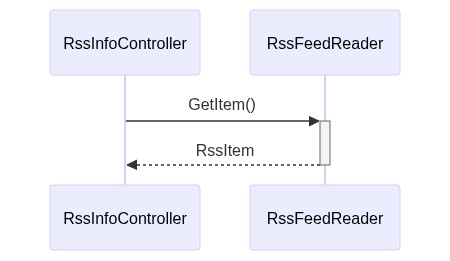
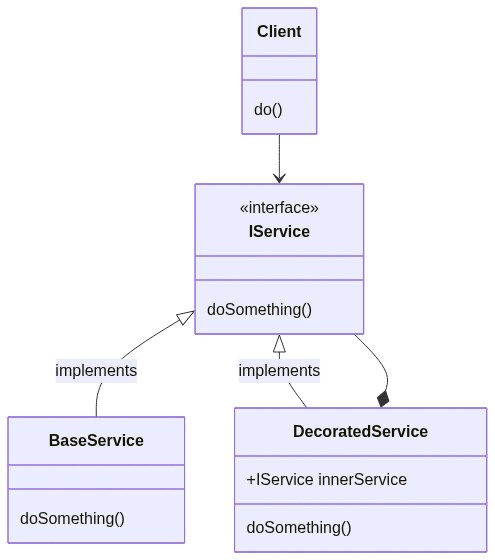
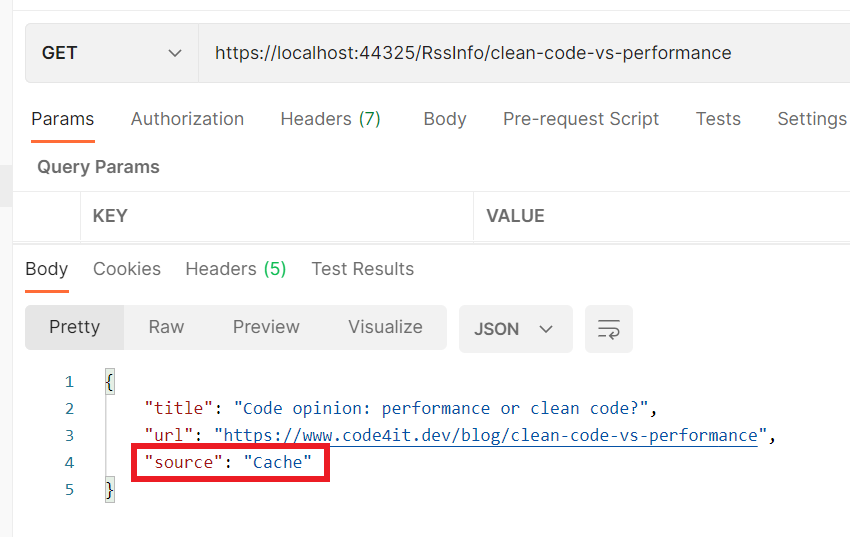
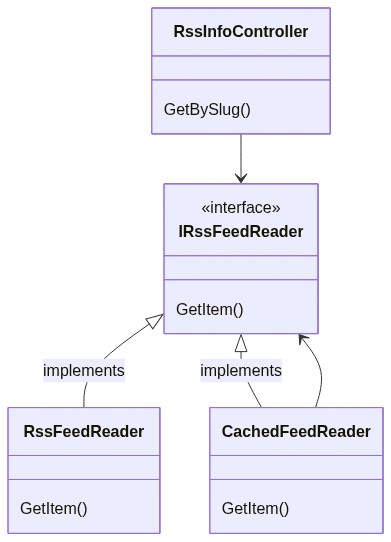
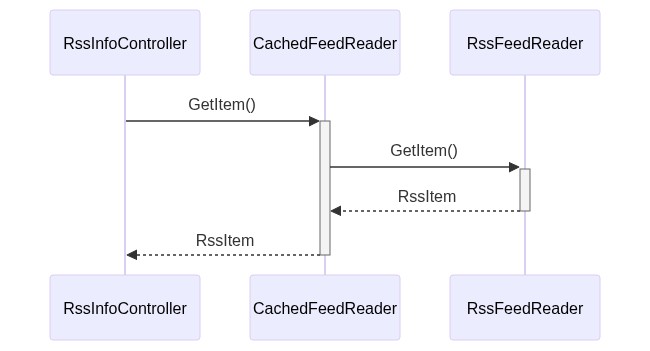
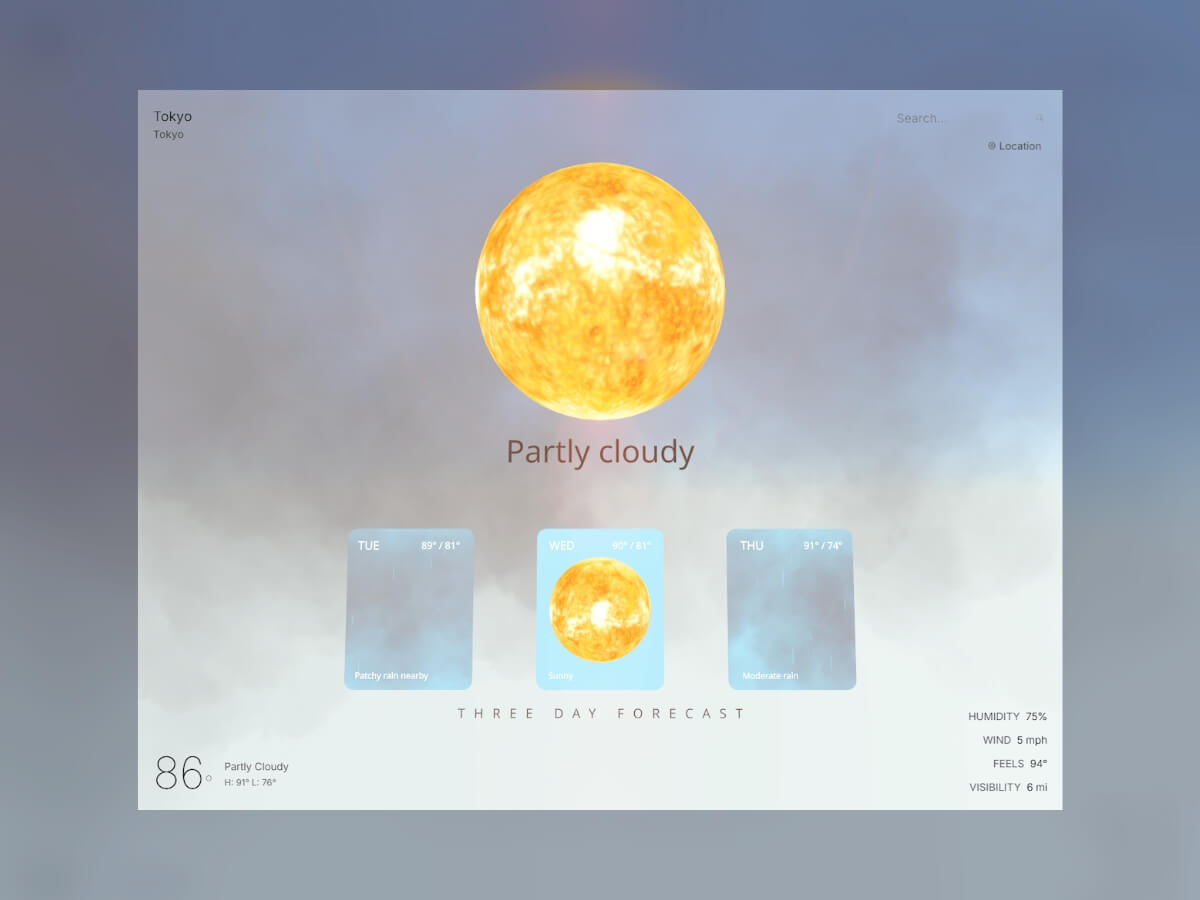

{kind=link}